 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Embeddings Via Distributions
Apr 17, 2021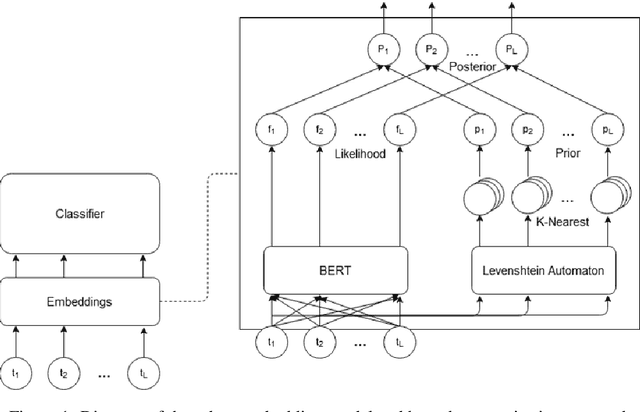
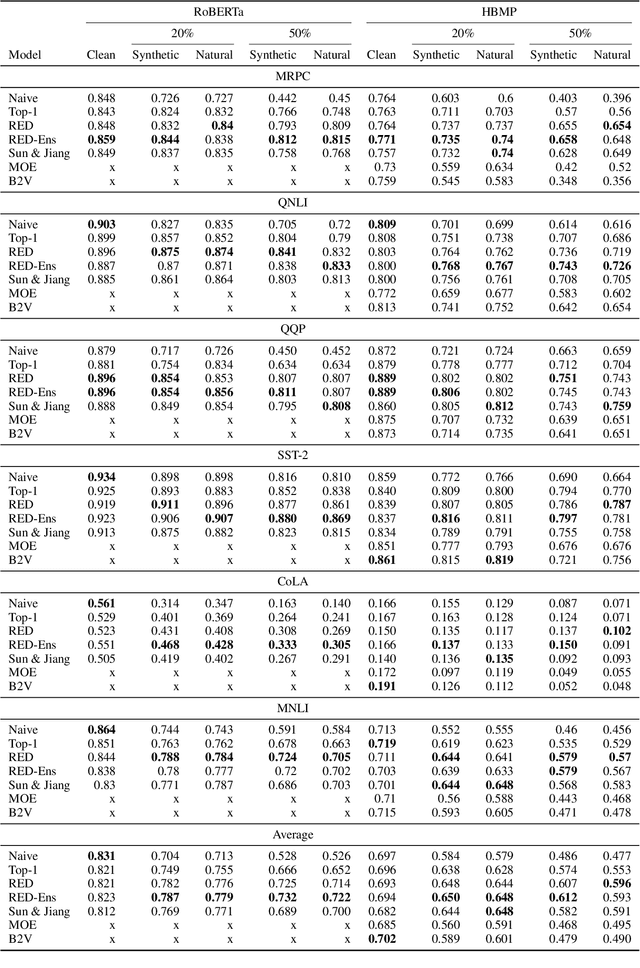

Despite recent monumental advances in the field, many Natural Language Processing (NLP) models still struggle to perform adequately on noisy domains. We propose a novel probabilistic embedding-level method to improve the robustness of NLP models. Our method, Robust Embeddings via Distributions (RED), incorporates information from both noisy tokens and surrounding context to obtain distributions over embedding vectors that can express uncertainty in semantic space more fully than any deterministic method. We evaluate our method on a number of downstream tasks using existing state-of-the-art models in the presence of both natural and synthetic noise, and demonstrate a clear improvement over other embedding approaches to robustness from the literature.
Sum-of-Squares Polynomial Flow
May 07, 2019
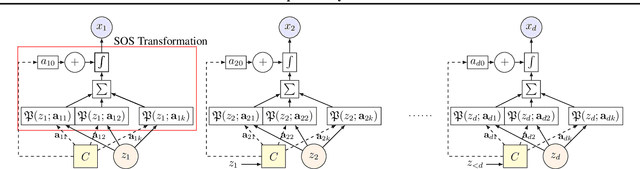

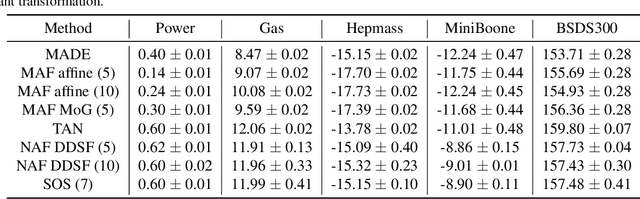
Triangular map is a recent construct in probability theory that allows one to transform any source probability density function to any target density function. Based on triangular maps, we propose a general framework for high-dimensional density estimation, by specifying one-dimensional transformations (equivalently conditional densities) and appropriate conditioner networks. This framework (a) reveals the commonalities and differences of existing autoregressive and flow based methods, (b) allows a unified understanding of the limitations and representation power of these recent approaches and, (c) motivates us to uncover a new Sum-of-Squares (SOS) flow that is interpretable, universal, and easy to train. We perform several synthetic experiments on various density geometries to demonstrate the benefits (and short-comings) of such transformations. SOS flows achieve competitive results in simulations and several real-world datasets.
Progressive Memory Banks for Incremental Domain Adaptation
Nov 01, 2018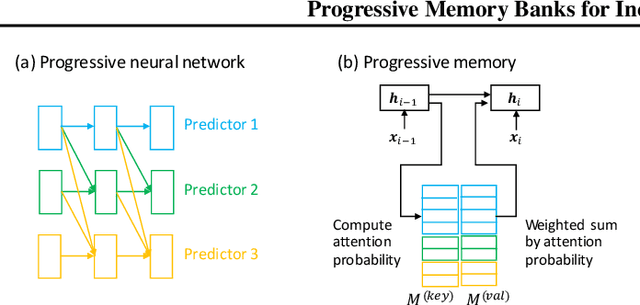
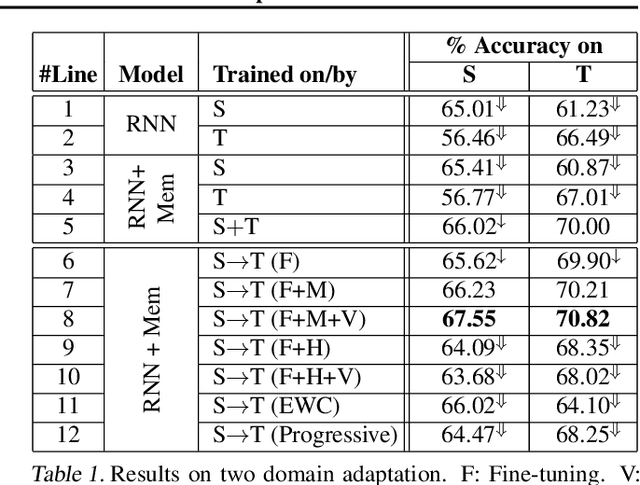
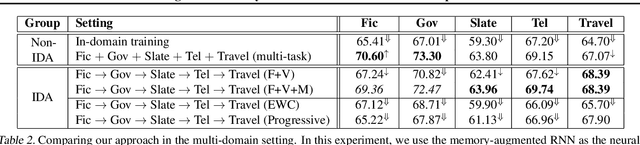
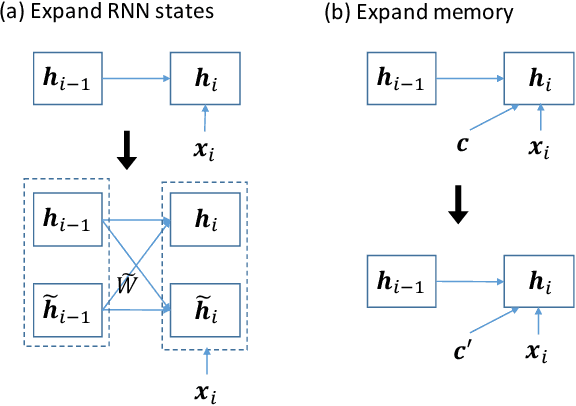
This paper addresses the problem of incremental domain adaptation (IDA). We assume each domain comes one after another, and that we could only access data in the current domain. The goal of IDA is to build a unified model performing well on all the domains that we have encountered. We propose to augment a recurrent neural network (RNN) with a directly parameterized memory bank, which is retrieved by an attention mechanism at each step of RNN transition. The memory bank provides a natural way of IDA: when adapting our model to a new domain, we progressively add new slots to the memory bank, which increases the number of parameters, and thus the model capacity. We learn the new memory slots and fine-tune existing parameters by back-propagation. Experimental results show that our approach achieves significantly better performance than fine-tuning alone, which suffers from the catastrophic forgetting problem. Compared with expanding hidden states, our approach is more robust for old domains, shown by both empirical and theoretical results. Our model also outperforms previous work of IDA including elastic weight consolidation (EWC) and the progressive neural network.