 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Extraction of Causal Relations from Natural Language Texts: A Comprehensive Survey
Paper and Code
May 25, 2016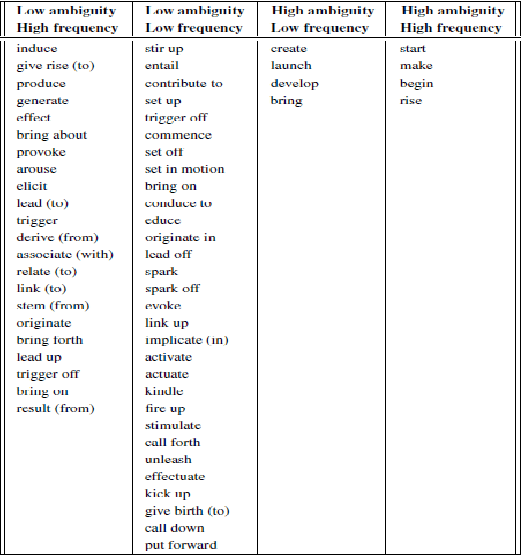
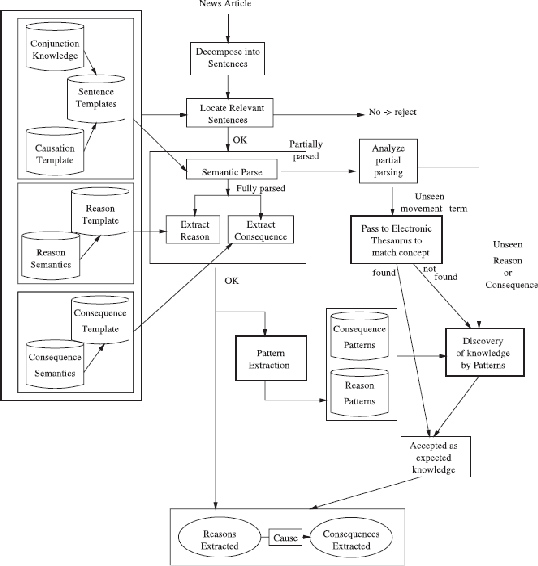

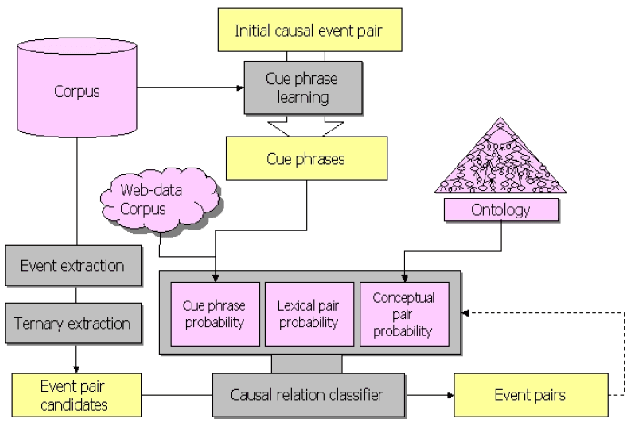
Automatic extraction of cause-effect relationships from natural language texts is a challenging open problem in Artificial Intelligence. Most of the early attempts at its solution used manually constructed linguistic and syntactic rules on small and domain-specific data sets. However, with the advent of big data, the availability of affordable computing power and the recent popularization of machine learning, the paradigm to tackle this problem has slowly shifted. Machines are now expected to learn generic causal extraction rules from labelled data with minimal supervision, in a domain independent-manner. In this paper, we provide a comprehensive survey of causal relation extraction techniques from both paradigms, and analyse their relative strengths and weaknesses, with recommendations for future work.