 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020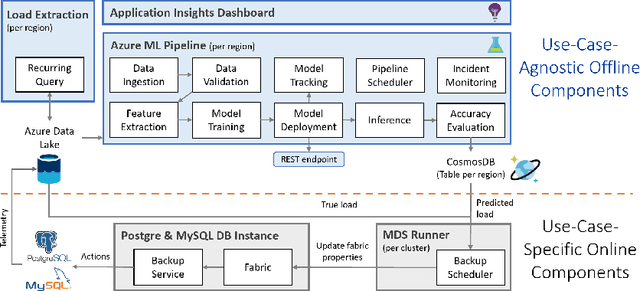
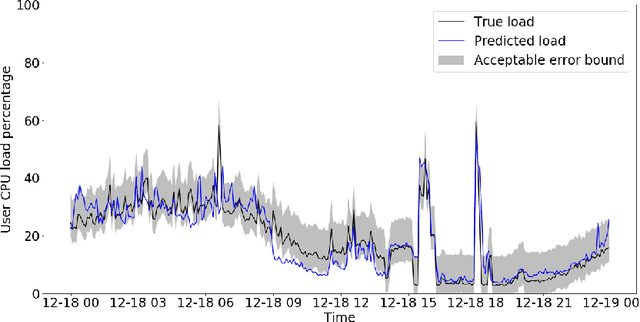
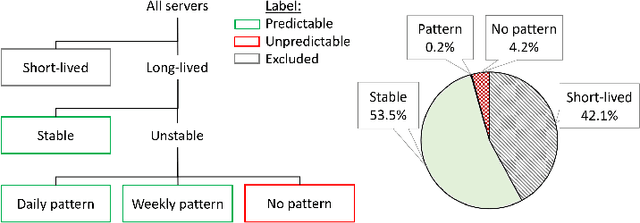
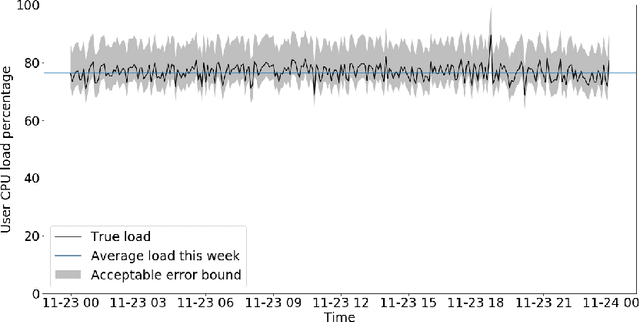
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.
Leveraging Subjective Human Annotation for Clustering Historic Newspaper Articles
Aug 17, 2012
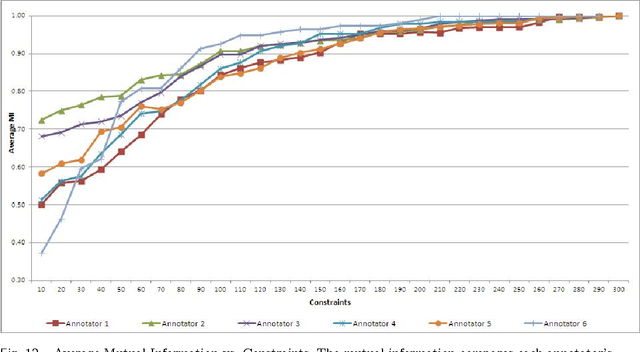
The New York Public Library is participating in the Chronicling America initiative to develop an online searchable database of historically significant newspaper articles. Microfilm copies of the newspapers are scanned and high resolution Optical Character Recognition (OCR) software is run on them. The text from the OCR provides a wealth of data and opinion for researchers and historians. However, categorization of articles provided by the OCR engine is rudimentary and a large number of the articles are labeled editorial without further grouping. Manually sorting articles into fine-grained categories is time consuming if not impossible given the size of the corpus. This paper studies techniques for automatic categorization of newspaper articles so as to enhance search and retrieval on the archive. We explore unsupervised (e.g. KMeans) and semi-supervised (e.g. constrained clustering) learning algorithms to develop article categorization schemes geared towards the needs of end-users. A pilot study was designed to understand whether there was unanimous agreement amongst patrons regarding how articles can be categorized. It was found that the task was very subjective and consequently automated algorithms that could deal with subjective labels were used. While the small scale pilot study was extremely helpful in designing machine learning algorithms, a much larger system needs to be developed to collect annotations from users of the archive. The "BODHI" system currently being developed is a step in that direction, allowing users to correct wrongly scanned OCR and providing keywords and tags for newspaper articles used frequently. On successful implementation of the beta version of this system, we hope that it can be integrated with existing software being developed for the Chronicling America project.