 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocSplit: A Comprehensive Benchmark Dataset and Evaluation Approach for Document Packet Recognition and Splitting
Feb 17, 2026Document understanding in real-world applications often requires processing heterogeneous, multi-page document packets containing multiple documents stitched together. Despite recent advances in visual document understanding, the fundamental task of document packet splitting, which involves separating a document packet into individual units, remains largely unaddressed. We present the first comprehensive benchmark dataset, DocSplit, along with novel evaluation metrics for assessing the document packet splitting capabilities of large language models. DocSplit comprises five datasets of varying complexity, covering diverse document types, layouts, and multimodal settings. We formalize the DocSplit task, which requires models to identify document boundaries, classify document types, and maintain correct page ordering within a document packet. The benchmark addresses real-world challenges, including out-of-order pages, interleaved documents, and documents lacking clear demarcations. We conduct extensive experiments evaluating multimodal LLMs on our datasets, revealing significant performance gaps in current models' ability to handle complex document splitting tasks. The DocSplit benchmark datasets and proposed novel evaluation metrics provide a systematic framework for advancing document understanding capabilities essential for legal, financial, healthcare, and other document-intensive domains. We release the datasets to facilitate future research in document packet processing.
OmniGraph: Rich Representation and Graph Kernel Learning
Oct 10, 2015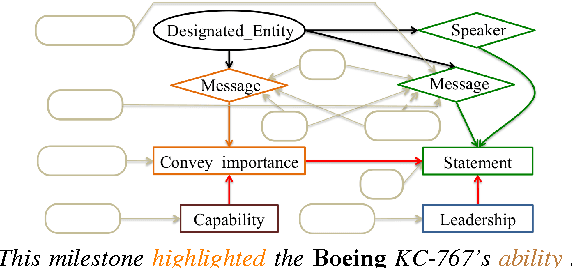
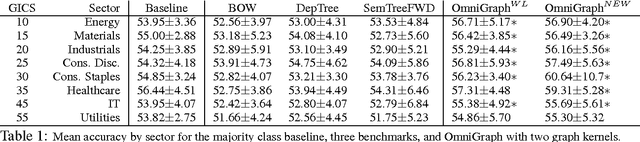


OmniGraph, a novel representation to support a range of NLP classification tasks, integrates lexical items, syntactic dependencies and frame semantic parses into graphs. Feature engineering is folded into the learning through convolution graph kernel learning to explore different extents of the graph. A high-dimensional space of features includes individual nodes as well as complex subgraphs. In experiments on a text-forecasting problem that predicts stock price change from news for company mentions, OmniGraph beats several benchmarks based on bag-of-words, syntactic dependencies, and semantic trees. The highly expressive features OmniGraph discovers provide insights into the semantics across distinct market sectors. To demonstrate the method's generality, we also report its high performance results on a fine-grained sentiment corpus.
Kernelized Locality-Sensitive Hashing for Semi-Supervised Agglomerative Clustering
Jan 16, 2013


Large scale agglomerative clustering is hindered by computational burdens. We propose a novel scheme where exact inter-instance distance calculation is replaced by the Hamming distance between Kernelized Locality-Sensitive Hashing (KLSH) hashed values. This results in a method that drastically decreases computation time. Additionally, we take advantage of certain labeled data points via distance metric learning to achieve a competitive precision and recall comparing to K-Means but in much less computation time.
Leveraging Subjective Human Annotation for Clustering Historic Newspaper Articles
Aug 17, 2012
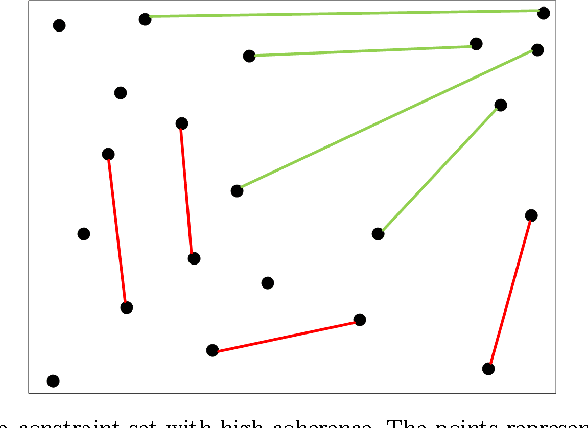
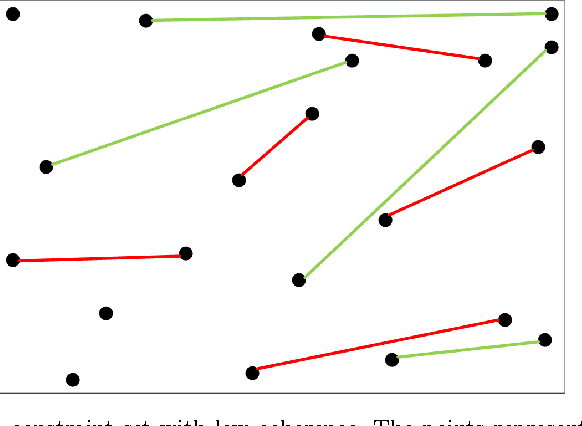
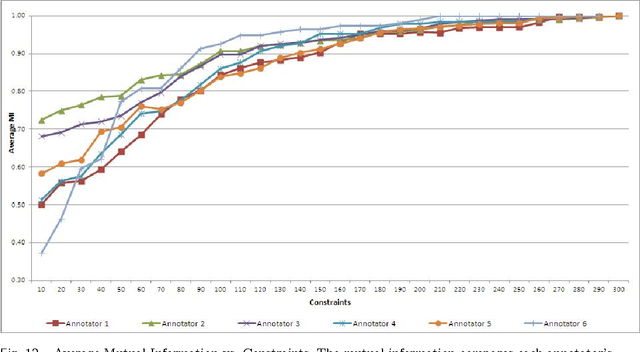
The New York Public Library is participating in the Chronicling America initiative to develop an online searchable database of historically significant newspaper articles. Microfilm copies of the newspapers are scanned and high resolution Optical Character Recognition (OCR) software is run on them. The text from the OCR provides a wealth of data and opinion for researchers and historians. However, categorization of articles provided by the OCR engine is rudimentary and a large number of the articles are labeled editorial without further grouping. Manually sorting articles into fine-grained categories is time consuming if not impossible given the size of the corpus. This paper studies techniques for automatic categorization of newspaper articles so as to enhance search and retrieval on the archive. We explore unsupervised (e.g. KMeans) and semi-supervised (e.g. constrained clustering) learning algorithms to develop article categorization schemes geared towards the needs of end-users. A pilot study was designed to understand whether there was unanimous agreement amongst patrons regarding how articles can be categorized. It was found that the task was very subjective and consequently automated algorithms that could deal with subjective labels were used. While the small scale pilot study was extremely helpful in designing machine learning algorithms, a much larger system needs to be developed to collect annotations from users of the archive. The "BODHI" system currently being developed is a step in that direction, allowing users to correct wrongly scanned OCR and providing keywords and tags for newspaper articles used frequently. On successful implementation of the beta version of this system, we hope that it can be integrated with existing software being developed for the Chronicling America project.