 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeMi: A Graph-based, Multimodal Recommendation System for Narrative Scroll Paintings
Mar 01, 2026Recommendation Systems are effective in managing the ever-increasing amount of multimodal data available today and help users discover interesting new items. These systems can handle various media types such as images, text, audio, and video data, and this has made it possible to handle content-based recommendation utilizing features extracted from items while also incorporating user preferences. Graph Neural Network (GNN)-based recommendation systems are a special class of recommendation systems that can handle relationships between items and users, making them particularly attractive for content-based recommendations. Their popularity also stems from the fact that they use advanced machine learning techniques, such as deep learning on graph-structured data, to exploit user-to-item interactions. The nodes in the graph can access higher-order neighbor information along with state-of-the-art vision-language models for processing multimodal content, and there are well-designed algorithms for embedding, message passing, and propagation. In this work, we present the design of a GNN-based recommendation system on a novel data set collected from field research. Designed for an endangered performing art form, the recommendation system uses multimodal content (text and image data) to suggest similar paintings for viewing and purchase. To the best of our knowledge, there is no recommendation system designed for narrative scroll paintings -- our work therefore serves several purposes, including art conservation, a data storage system for endangered art objects, and a state-of-the-art recommendation system that leverages both the novel characteristics of the data and preferences of the user population interested in narrative scroll paintings.
Heterogeneous Sequel-Aware Graph Neural Networks for Sequential Learning
Jun 05, 2025



Graph-based recommendation systems use higher-order user and item embeddings for next-item predictions. Dynamically adding collaborative signals from neighbors helps to use similar users' preferences during learning. While item-item correlations and their impact on recommendations have been studied, the efficacy of temporal item sequences for recommendations is much less explored. In this paper, we examine temporal item sequence (sequel-aware) embeddings along with higher-order user embeddings and show that sequel-aware Graph Neural Networks have better (or comparable) recommendation performance than graph-based recommendation systems that do not consider sequel information. Extensive empirical results comparing Heterogeneous Sequel-aware Graph Neural Networks (HSAL-GNNs) to other algorithms for sequential learning (such as transformers, graph neural networks, auto-encoders) are presented on three synthetic and three real-world datasets. Our results indicate that the incorporation of sequence information from items greatly enhances recommendations.
Consensus Based Multi-Layer Perceptrons for Edge Computing
Feb 09, 2021


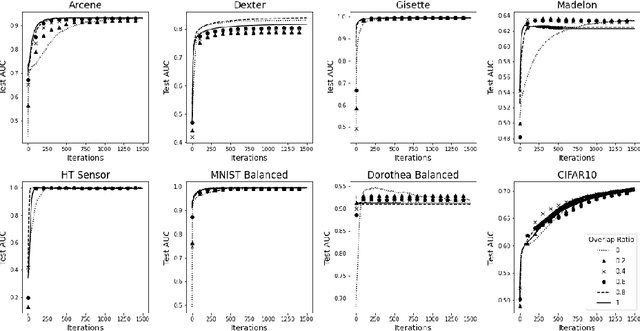
In recent years, storing large volumes of data on distributed devices has become commonplace. Applications involving sensors, for example, capture data in different modalities including image, video, audio, GPS and others. Novel algorithms are required to learn from this rich distributed data. In this paper, we present consensus based multi-layer perceptrons for resource-constrained devices. Assuming nodes (devices) in the distributed system are arranged in a graph and contain vertically partitioned data, the goal is to learn a global function that minimizes the loss. Each node learns a feed-forward multi-layer perceptron and obtains a loss on data stored locally. It then gossips with a neighbor, chosen uniformly at random, and exchanges information about the loss. The updated loss is used to run a back propagation algorithm and adjust weights appropriately. This method enables nodes to learn the global function without exchange of data in the network. Empirical results reveal that the consensus algorithm converges to the centralized model and has performance comparable to centralized multi-layer perceptrons and tree-based algorithms including random forests and gradient boosted decision trees.
Impact of Community Structure on Consensus Machine Learning
Nov 02, 2020
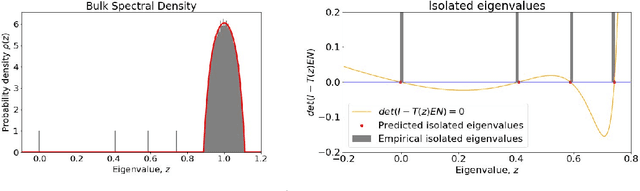
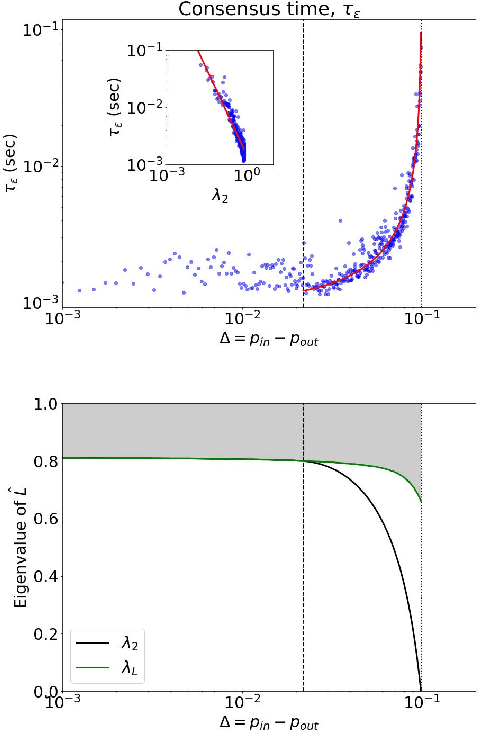
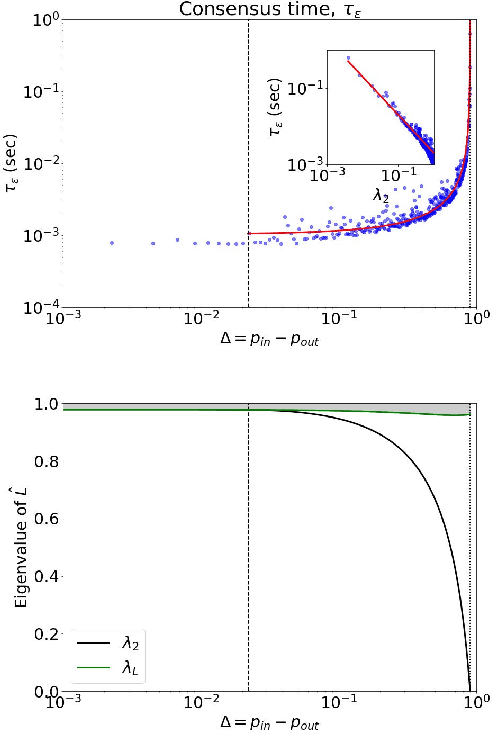
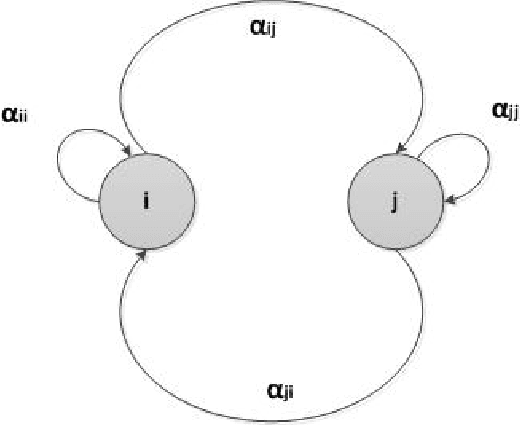
Consensus dynamics support decentralized machine learning for data that is distributed across a cloud compute cluster or across the internet of things. In these and other settings, one seeks to minimize the time $\tau_\epsilon$ required to obtain consensus within some $\epsilon>0$ margin of error. $\tau_\epsilon$ typically depends on the topology of the underlying communication network, and for many algorithms $\tau_\epsilon$ depends on the second-smallest eigenvalue $\lambda_2\in[0,1]$ of the network's normalized Laplacian matrix: $\tau_\epsilon\sim\mathcal{O}(\lambda_2^{-1})$. Here, we analyze the effect on $\tau_\epsilon$ of network community structure, which can arise when compute nodes/sensors are spatially clustered, for example. We study consensus machine learning over networks drawn from stochastic block models, which yield random networks that can contain heterogeneous communities with different sizes and densities. Using random matrix theory, we analyze the effects of communities on $\lambda_2$ and consensus, finding that $\lambda_2$ generally increases (i.e., $\tau_\epsilon$ decreases) as one decreases the extent of community structure. We further observe that there exists a critical level of community structure at which $\tau_\epsilon$ reaches a lower bound and is no longer limited by the presence of communities. We support our findings with empirical experiments for decentralized support vector machines.
GADGET SVM: A Gossip-bAseD sub-GradiEnT Solver for Linear SVMs
Dec 05, 2018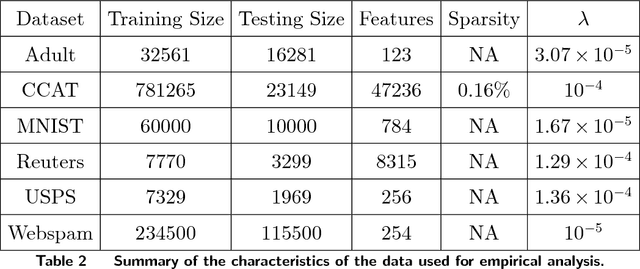
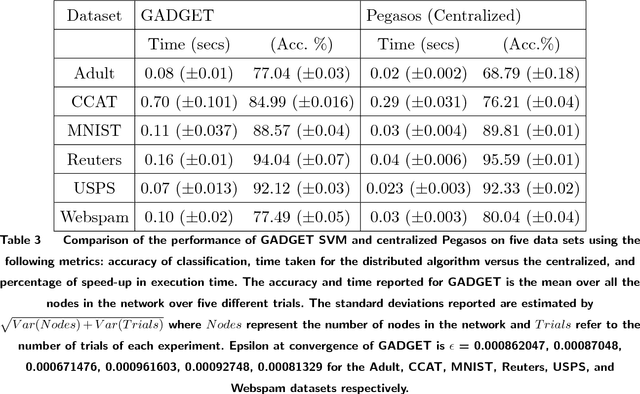
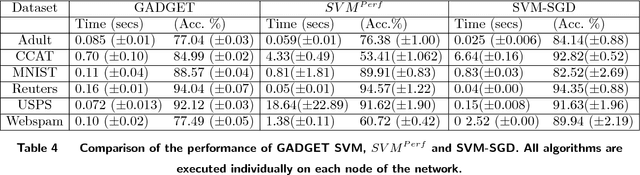
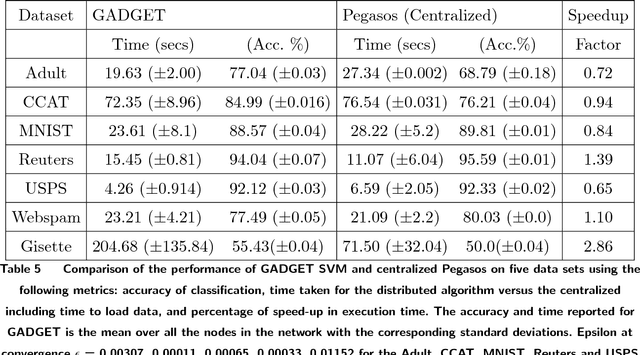
In the era of big data, an important weapon in a machine learning researcher's arsenal is a scalable Support Vector Machine (SVM) algorithm. SVMs are extensively used for solving classification problems. Traditional algorithms for learning SVMs often scale super linearly with training set size which becomes infeasible very quickly for large data sets. In recent years, scalable algorithms have been designed which study the primal or dual formulations of the problem. This often suggests a way to decompose the problem and facilitate development of distributed algorithms. In this paper, we present a distributed algorithm for learning linear Support Vector Machines in the primal form for binary classification called Gossip-bAseD sub-GradiEnT (GADGET) SVM. The algorithm is designed such that it can be executed locally on nodes of a distributed system. Each node processes its local homogeneously partitioned data and learns a primal SVM model. It then gossips with random neighbors about the classifier learnt and uses this information to update the model. Extensive theoretical and empirical results suggest that this anytime algorithm has performance comparable to its centralized and online counterparts.
A Machine Learning Approach to Quantitative Prosopography
Jan 30, 2018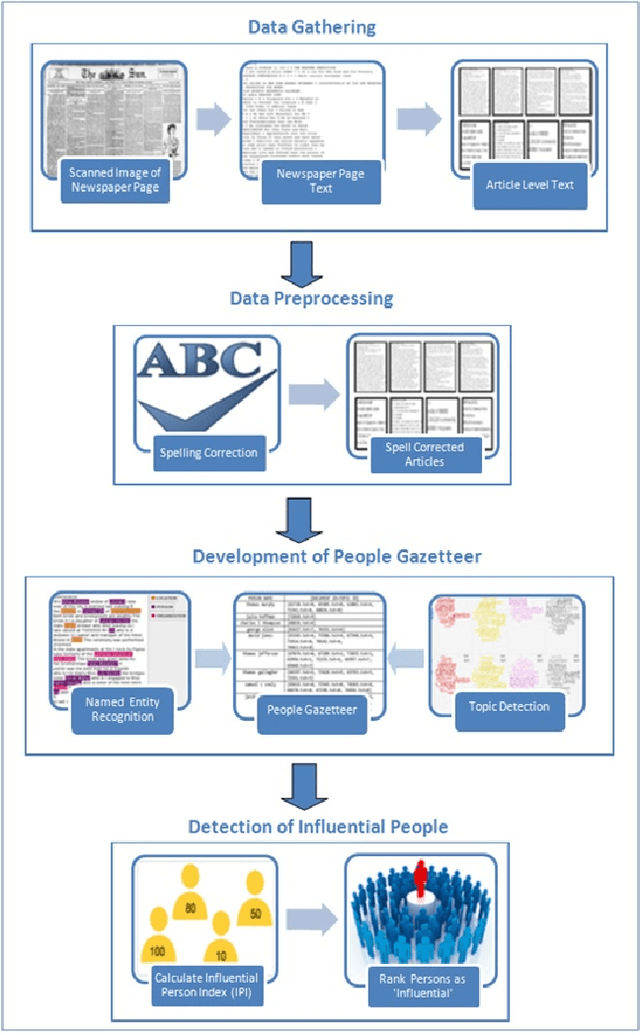


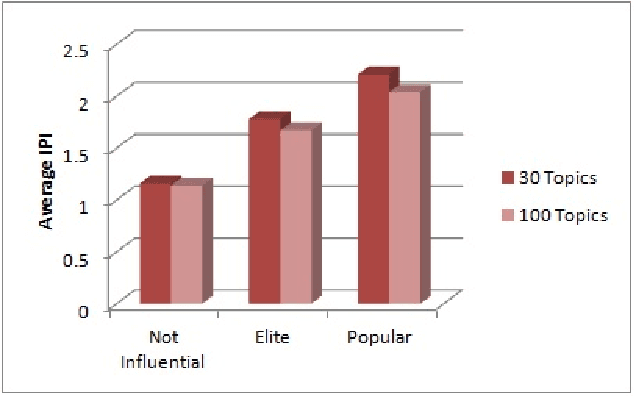
Prosopography is an investigation of the common characteristics of a group of people in history, by a collective study of their lives. It involves a study of biographies to solve historical problems. If such biographies are unavailable, surviving documents and secondary biographical data are used. Quantitative prosopography involves analysis of information from a wide variety of sources about "ordinary people". In this paper, we present a machine learning framework for automatically designing a people gazetteer which forms the basis of quantitative prosopographical research. The gazetteer is learnt from the noisy text of newspapers using a Named Entity Recognizer (NER). It is capable of identifying influential people from it by making use of a custom designed Influential Person Index (IPI). Our corpus comprises of 14020 articles from a local newspaper, "The Sun", published from New York in 1896. Some influential people identified by our algorithm include Captain Donald Hankey (an English soldier), Dame Nellie Melba (an Australian operatic soprano), Hugh Allan (a Canadian shipping magnate) and Sir Hugh John McDonald (the first Prime Minister of Canada).
Consensus-Based Modelling using Distributed Feature Construction
Sep 11, 2014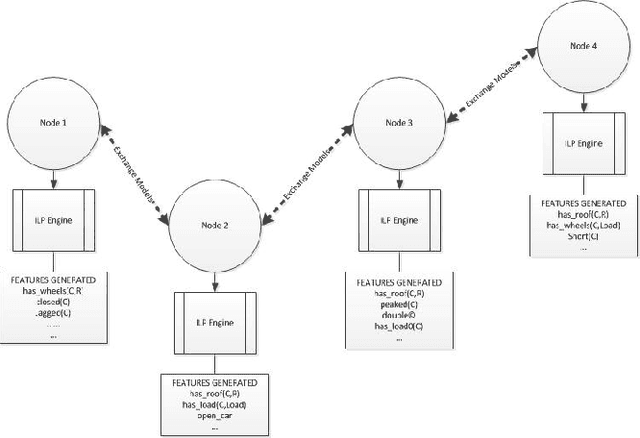
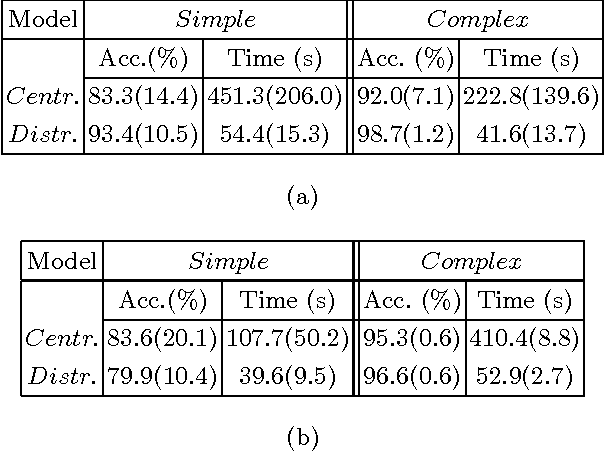
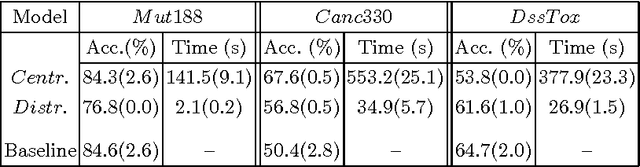
A particularly successful role for Inductive Logic Programming (ILP) is as a tool for discovering useful relational features for subsequent use in a predictive model. Conceptually, the case for using ILP to construct relational features rests on treating these features as functions, the automated discovery of which necessarily requires some form of first-order learning. Practically, there are now several reports in the literature that suggest that augmenting any existing features with ILP-discovered relational features can substantially improve the predictive power of a model. While the approach is straightforward enough, much still needs to be done to scale it up to explore more fully the space of possible features that can be constructed by an ILP system. This is in principle, infinite and in practice, extremely large. Applications have been confined to heuristic or random selections from this space. In this paper, we address this computational difficulty by allowing features to be constructed in a distributed manner. That is, there is a network of computational units, each of which employs an ILP engine to construct some small number of features and then builds a (local) model. We then employ a consensus-based algorithm, in which neighboring nodes share information to update local models. For a category of models (those with convex loss functions), it can be shown that the algorithm will result in all nodes converging to a consensus model. In practice, it may be slow to achieve this convergence. Nevertheless, our results on synthetic and real datasets that suggests that in relatively short time the "best" node in the network reaches a model whose predictive accuracy is comparable to that obtained using more computational effort in a non-distributed setting (the best node is identified as the one whose weights converge first).
Leveraging Subjective Human Annotation for Clustering Historic Newspaper Articles
Aug 17, 2012
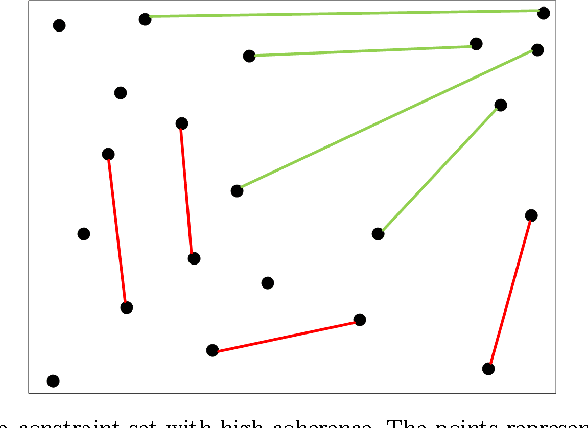
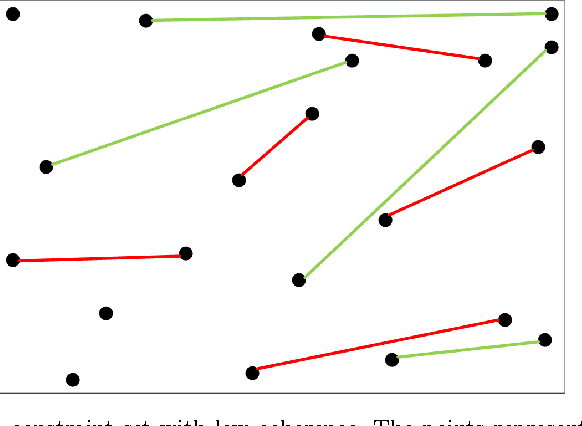
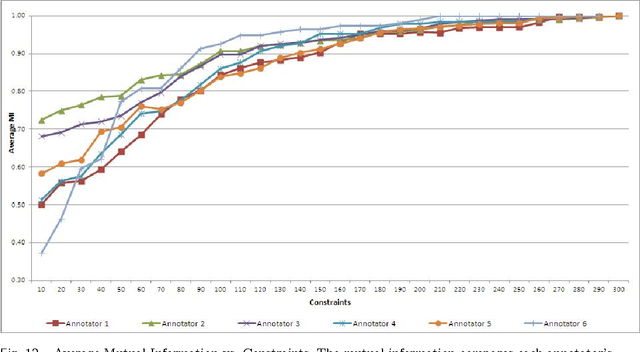
The New York Public Library is participating in the Chronicling America initiative to develop an online searchable database of historically significant newspaper articles. Microfilm copies of the newspapers are scanned and high resolution Optical Character Recognition (OCR) software is run on them. The text from the OCR provides a wealth of data and opinion for researchers and historians. However, categorization of articles provided by the OCR engine is rudimentary and a large number of the articles are labeled editorial without further grouping. Manually sorting articles into fine-grained categories is time consuming if not impossible given the size of the corpus. This paper studies techniques for automatic categorization of newspaper articles so as to enhance search and retrieval on the archive. We explore unsupervised (e.g. KMeans) and semi-supervised (e.g. constrained clustering) learning algorithms to develop article categorization schemes geared towards the needs of end-users. A pilot study was designed to understand whether there was unanimous agreement amongst patrons regarding how articles can be categorized. It was found that the task was very subjective and consequently automated algorithms that could deal with subjective labels were used. While the small scale pilot study was extremely helpful in designing machine learning algorithms, a much larger system needs to be developed to collect annotations from users of the archive. The "BODHI" system currently being developed is a step in that direction, allowing users to correct wrongly scanned OCR and providing keywords and tags for newspaper articles used frequently. On successful implementation of the beta version of this system, we hope that it can be integrated with existing software being developed for the Chronicling America project.