 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus Based Multi-Layer Perceptrons for Edge Computing
Feb 09, 2021


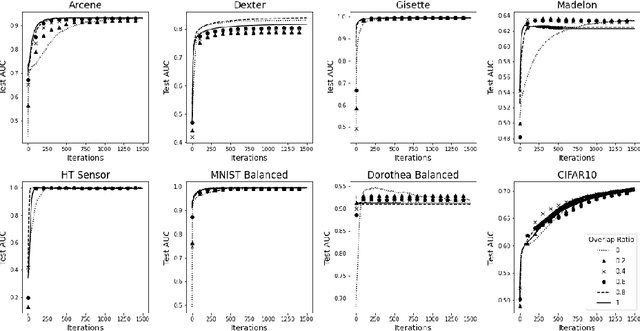
In recent years, storing large volumes of data on distributed devices has become commonplace. Applications involving sensors, for example, capture data in different modalities including image, video, audio, GPS and others. Novel algorithms are required to learn from this rich distributed data. In this paper, we present consensus based multi-layer perceptrons for resource-constrained devices. Assuming nodes (devices) in the distributed system are arranged in a graph and contain vertically partitioned data, the goal is to learn a global function that minimizes the loss. Each node learns a feed-forward multi-layer perceptron and obtains a loss on data stored locally. It then gossips with a neighbor, chosen uniformly at random, and exchanges information about the loss. The updated loss is used to run a back propagation algorithm and adjust weights appropriately. This method enables nodes to learn the global function without exchange of data in the network. Empirical results reveal that the consensus algorithm converges to the centralized model and has performance comparable to centralized multi-layer perceptrons and tree-based algorithms including random forests and gradient boosted decision trees.
GADGET SVM: A Gossip-bAseD sub-GradiEnT Solver for Linear SVMs
Dec 05, 2018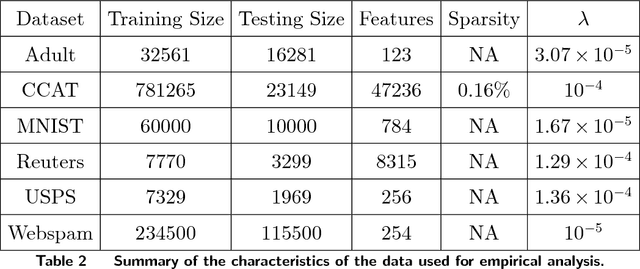
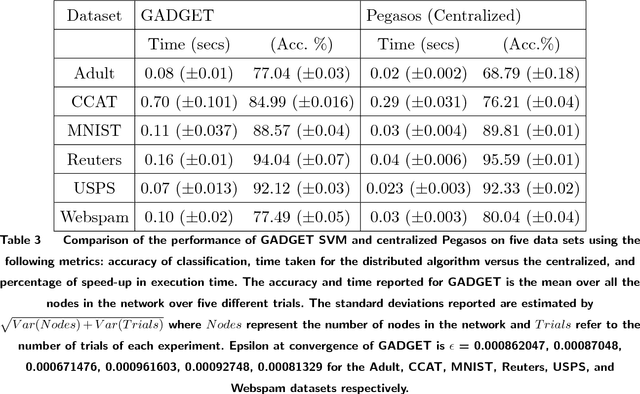
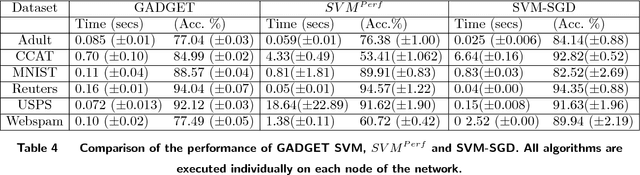
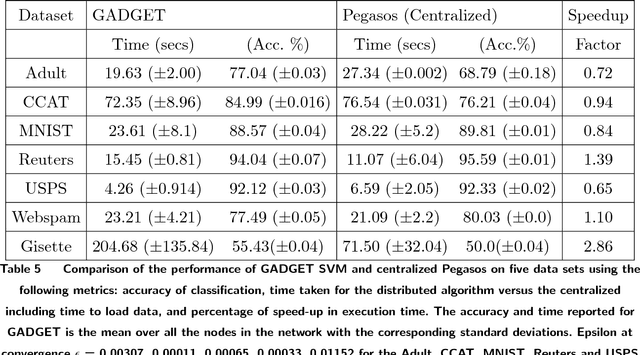
In the era of big data, an important weapon in a machine learning researcher's arsenal is a scalable Support Vector Machine (SVM) algorithm. SVMs are extensively used for solving classification problems. Traditional algorithms for learning SVMs often scale super linearly with training set size which becomes infeasible very quickly for large data sets. In recent years, scalable algorithms have been designed which study the primal or dual formulations of the problem. This often suggests a way to decompose the problem and facilitate development of distributed algorithms. In this paper, we present a distributed algorithm for learning linear Support Vector Machines in the primal form for binary classification called Gossip-bAseD sub-GradiEnT (GADGET) SVM. The algorithm is designed such that it can be executed locally on nodes of a distributed system. Each node processes its local homogeneously partitioned data and learns a primal SVM model. It then gossips with random neighbors about the classifier learnt and uses this information to update the model. Extensive theoretical and empirical results suggest that this anytime algorithm has performance comparable to its centralized and online counterparts.