 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniGraph: Rich Representation and Graph Kernel Learning
Paper and Code
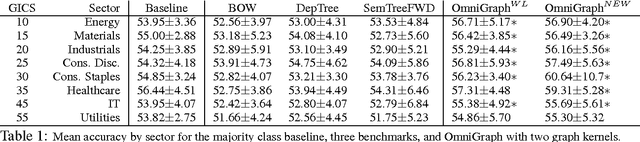
Oct 10, 2015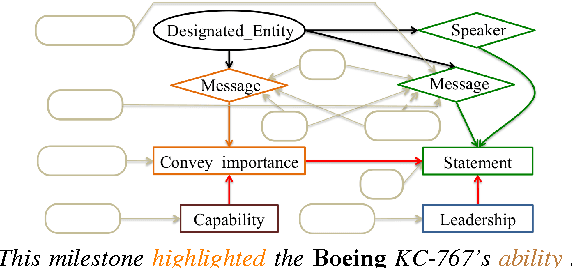


OmniGraph, a novel representation to support a range of NLP classification tasks, integrates lexical items, syntactic dependencies and frame semantic parses into graphs. Feature engineering is folded into the learning through convolution graph kernel learning to explore different extents of the graph. A high-dimensional space of features includes individual nodes as well as complex subgraphs. In experiments on a text-forecasting problem that predicts stock price change from news for company mentions, OmniGraph beats several benchmarks based on bag-of-words, syntactic dependencies, and semantic trees. The highly expressive features OmniGraph discovers provide insights into the semantics across distinct market sectors. To demonstrate the method's generality, we also report its high performance results on a fine-grained sentiment corpus.