 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Continual Learning of Computer-Use Agents for Environment Adaptation
Feb 10, 2026Real-world digital environments are highly diverse and dynamic. These characteristics cause agents to frequently encounter unseen scenarios and distribution shifts, making continual learning in specific environments essential for computer-use agents (CUAs). However, a key challenge lies in obtaining high-quality and environment-grounded agent data without relying on costly human annotation. In this work, we introduce ACuRL, an Autonomous Curriculum Reinforcement Learning framework that continually adapts agents to specific environments with zero human data. The agent first explores target environments to acquire initial experiences. During subsequent iterative training, a curriculum task generator leverages these experiences together with feedback from the previous iteration to synthesize new tasks tailored for the agent's current capabilities. To provide reliable reward signals, we introduce CUAJudge, a robust automatic evaluator for CUAs that achieves 93% agreement with human judgments. Empirically, our method effectively enables both intra-environment and cross-environment continual learning, yielding 4-22% performance gains without catastrophic forgetting on existing environments. Further analyses show highly sparse updates (e.g., 20% parameters), which helps explain the effective and robust adaptation. Our data and code are available at https://github.com/OSU-NLP-Group/ACuRL.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025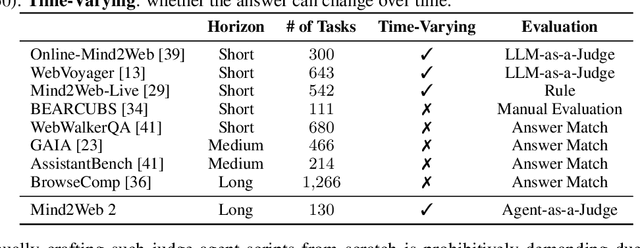
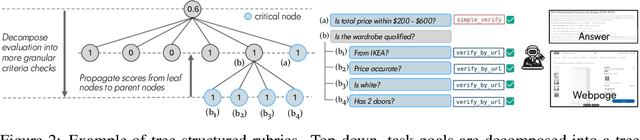

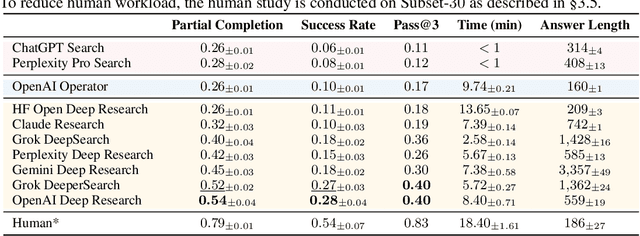
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
An Illusion of Progress? Assessing the Current State of Web Agents
Apr 02, 2025
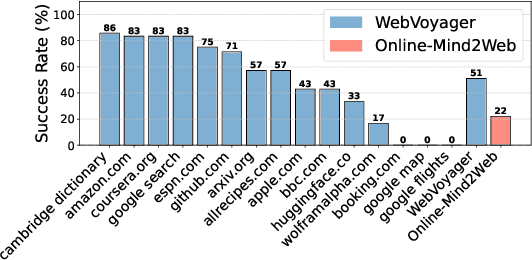
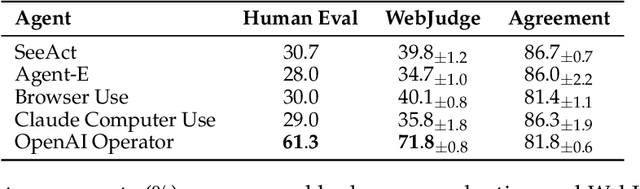
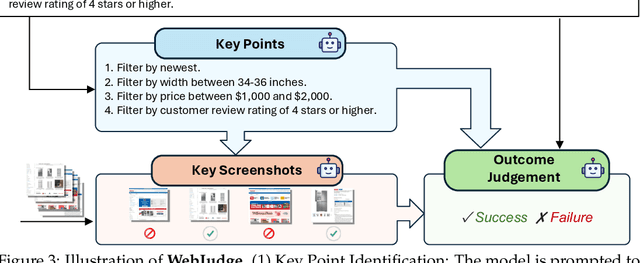
As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.
TADIS: Steering Models for Deep-Thinking about Demonstration Examples
Oct 05, 2023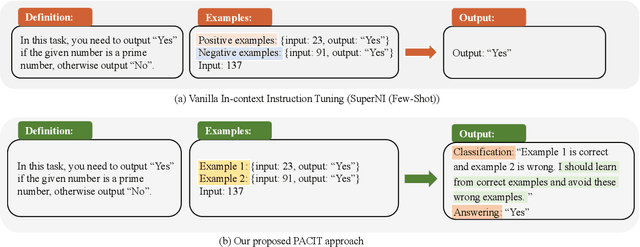
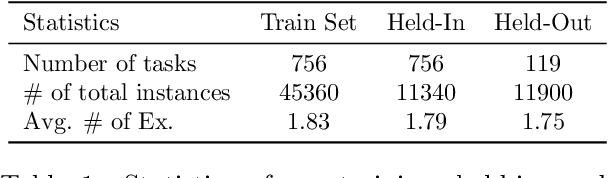
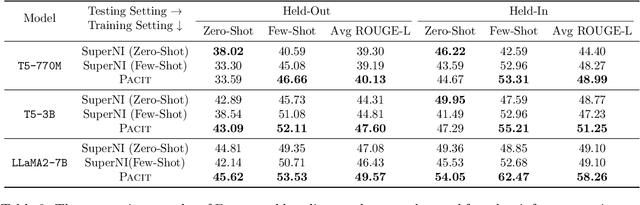

Instruction tuning has been demonstrated that could significantly improve the zero-shot generalization capability to unseen tasks by an apparent margin. By incorporating additional context (e.g., task definition, examples) during the fine-tuning process, Large Language Models (LLMs) achieved much higher performance than before. However, recent work reported that delusive task examples can achieve almost the same performance as correct task examples, indicating the input-label correspondence is less important than previously thought. Intrigued by this counter-intuitive observation, we suspect models have the same illusion of competence as humans. Therefore, we propose a novel method called TADIS that steers LLMs for "Deep-Thinking'' about demonstration examples instead of merely seeing. To alleviate the illusion of competence of models, we first ask the model to verify the correctness of shown examples. Then, using the verification results as conditions to elicit models for a better answer. Our experimental results show that TADIS consistently outperforms competitive baselines on in-domain and out-domain tasks (improving 2.79 and 4.03 average ROUGLE-L on out-domain and in-domain datasets, respectively). Despite the presence of generated examples (not all of the thinking labels are accurate), TADIS can notably enhance performance in zero-shot and few-shot settings. This also suggests that our approach can be adopted on a large scale to improve the instruction following capabilities of models without any manual labor. Moreover, we construct three types of thinking labels with different model sizes and find that small models learn from the format of TADIS but larger models can be steered for "Deep-Thinking''.
Parameter-Efficient Tuning Helps Language Model Alignment
Oct 01, 2023Aligning large language models (LLMs) with human preferences is essential for safe and useful LLMs. Previous works mainly adopt reinforcement learning (RLHF) and direct preference optimization (DPO) with human feedback for alignment. Nevertheless, they have certain drawbacks. One such limitation is that they can only align models with one preference at the training time (e.g., they cannot learn to generate concise responses when the preference data prefers detailed responses), or have certain constraints for the data format (e.g., DPO only supports pairwise preference data). To this end, prior works incorporate controllable generations for alignment to make language models learn multiple preferences and provide outputs with different preferences during inference if asked. Controllable generation also offers more flexibility with regard to data format (e.g., it supports pointwise preference data). Specifically, it uses different control tokens for different preferences during training and inference, making LLMs behave differently when required. Current controllable generation methods either use a special token or hand-crafted prompts as control tokens, and optimize them together with LLMs. As control tokens are typically much lighter than LLMs, this optimization strategy may not effectively optimize control tokens. To this end, we first use parameter-efficient tuning (e.g., prompting tuning and low-rank adaptation) to optimize control tokens and then fine-tune models for controllable generations, similar to prior works. Our approach, alignMEnt with parameter-Efficient Tuning (MEET), improves the quality of control tokens, thus improving controllable generation quality consistently by an apparent margin on two well-recognized datasets compared with prior works.
RCOT: Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought
May 19, 2023
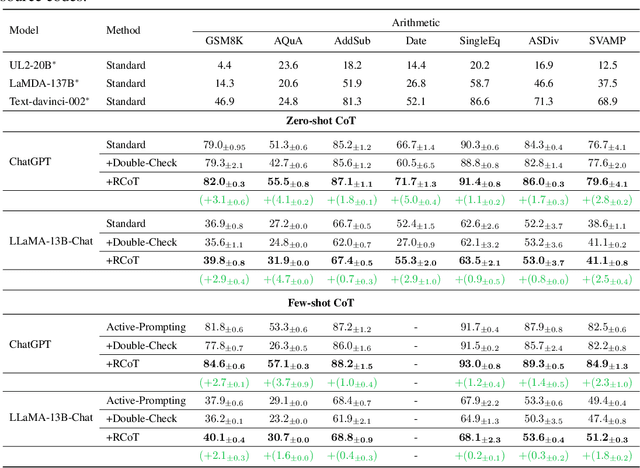


Large language Models (LLMs) have achieved promising performance on arithmetic reasoning tasks by incorporating step-by-step chain-of-thought (CoT) prompting. However, LLMs face challenges in maintaining factual consistency during reasoning, exhibiting tendencies to condition overlooking, question misinterpretation, and condition hallucination over given problems. Existing methods use coarse-grained feedback (e.g., whether the answer is correct) to improve factual consistency. In this work, we propose RCoT (Reversing Chain-of-Thought), a novel method to improve LLMs' reasoning abilities by automatically detecting and rectifying factual inconsistency in LLMs' generated solutions. To detect factual inconsistency, RCoT first asks LLMs to reconstruct the problem based on generated solutions. Then fine-grained comparisons between the original problem and the reconstructed problem expose the factual inconsistency in the original solutions. To rectify the solution, RCoT formulates detected factual inconsistency into fine-grained feedback to guide LLMs in revising solutions. Experimental results demonstrate consistent improvements of RCoT over standard CoT across seven arithmetic datasets. Moreover, we find that manually written fine-grained feedback can dramatically improve LLMs' reasoning abilities (e.g., ChatGPT reaches 94.6% accuracy on GSM8K), encouraging the community to further explore the fine-grained feedback generation methods.