 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyondFacial: Identity-Preserving Personalized Generation Beyond Facial Close-ups
Nov 15, 2025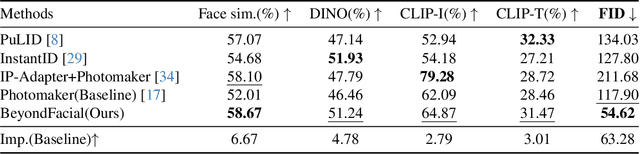
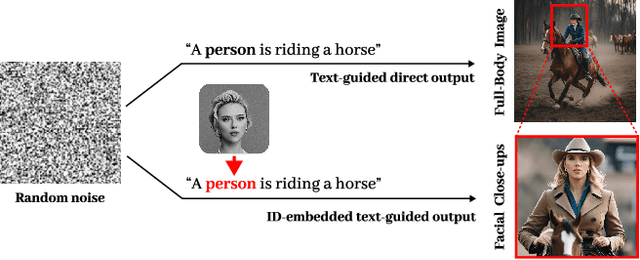
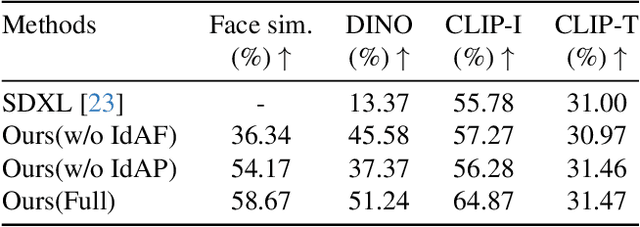
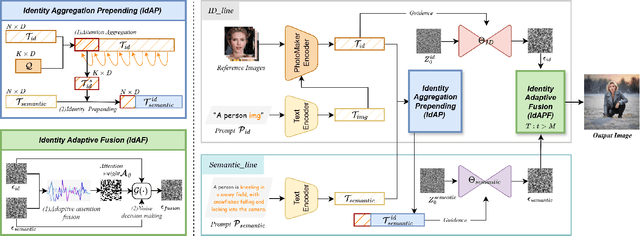
Identity-Preserving Personalized Generation (IPPG) has advanced film production and artistic creation, yet existing approaches overemphasize facial regions, resulting in outputs dominated by facial close-ups.These methods suffer from weak visual narrativity and poor semantic consistency under complex text prompts, with the core limitation rooted in identity (ID) feature embeddings undermining the semantic expressiveness of generative models. To address these issues, this paper presents an IPPG method that breaks the constraint of facial close-ups, achieving synergistic optimization of identity fidelity and scene semantic creation. Specifically, we design a Dual-Line Inference (DLI) pipeline with identity-semantic separation, resolving the representation conflict between ID and semantics inherent in traditional single-path architectures. Further, we propose an Identity Adaptive Fusion (IdAF) strategy that defers ID-semantic fusion to the noise prediction stage, integrating adaptive attention fusion and noise decision masking to avoid ID embedding interference on semantics without manual masking. Finally, an Identity Aggregation Prepending (IdAP) module is introduced to aggregate ID information and replace random initializations, further enhancing identity preservation. Experimental results validate that our method achieves stable and effective performance in IPPG tasks beyond facial close-ups, enabling efficient generation without manual masking or fine-tuning. As a plug-and-play component, it can be rapidly deployed in existing IPPG frameworks, addressing the over-reliance on facial close-ups, facilitating film-level character-scene creation, and providing richer personalized generation capabilities for related domains.
LLMEmbed: Rethinking Lightweight LLM's Genuine Function in Text Classification
Jun 06, 2024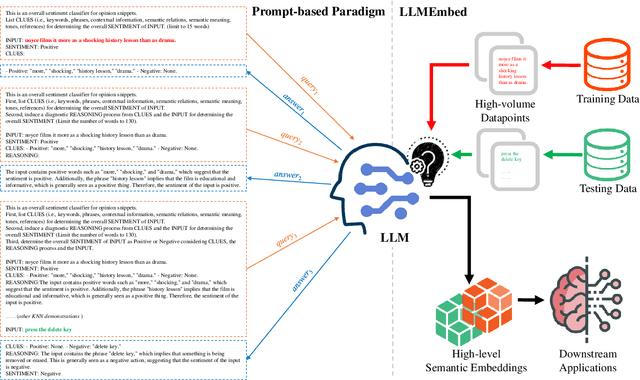
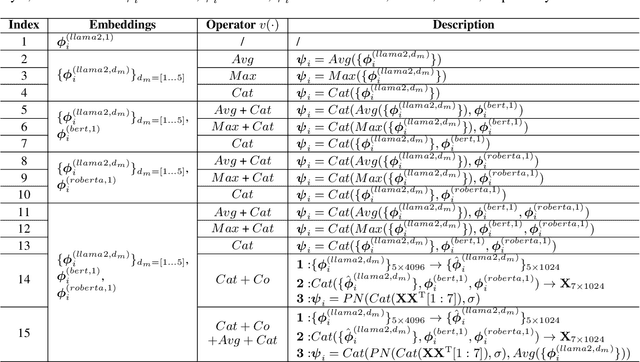
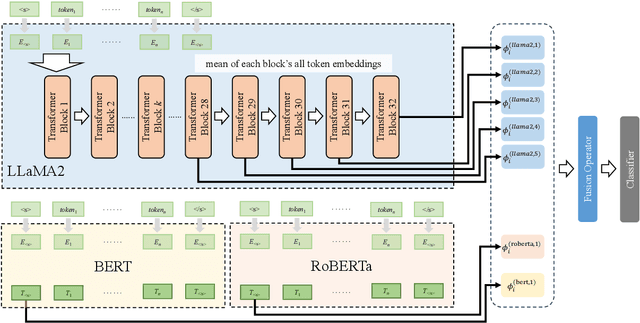
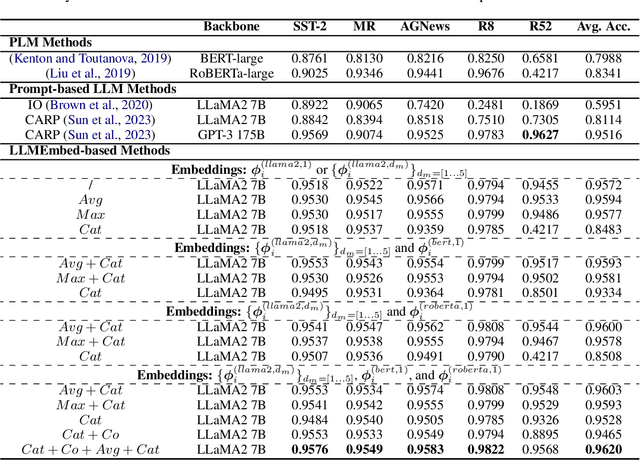
With the booming of Large Language Models (LLMs), prompt-learning has become a promising method mainly researched in various research areas. Recently, many attempts based on prompt-learning have been made to improve the performance of text classification. However, most of these methods are based on heuristic Chain-of-Thought (CoT), and tend to be more complex but less efficient. In this paper, we rethink the LLM-based text classification methodology, propose a simple and effective transfer learning strategy, namely LLMEmbed, to address this classical but challenging task. To illustrate, we first study how to properly extract and fuse the text embeddings via various lightweight LLMs at different network depths to improve their robustness and discrimination, then adapt such embeddings to train the classifier. We perform extensive experiments on publicly available datasets, and the results show that LLMEmbed achieves strong performance while enjoys low training overhead using lightweight LLM backbones compared to recent methods based on larger LLMs, i.e. GPT-3, and sophisticated prompt-based strategies. Our LLMEmbed achieves adequate accuracy on publicly available benchmarks without any fine-tuning while merely use 4% model parameters, 1.8% electricity consumption and 1.5% runtime compared to its counterparts. Code is available at: https://github.com/ChunLiu-cs/LLMEmbed-ACL2024.
Exploiting Inter-sample and Inter-feature Relations in Dataset Distillation
Mar 31, 2024



Dataset distillation has emerged as a promising approach in deep learning, enabling efficient training with small synthetic datasets derived from larger real ones. Particularly, distribution matching-based distillation methods attract attention thanks to its effectiveness and low computational cost. However, these methods face two primary limitations: the dispersed feature distribution within the same class in synthetic datasets, reducing class discrimination, and an exclusive focus on mean feature consistency, lacking precision and comprehensiveness. To address these challenges, we introduce two novel constraints: a class centralization constraint and a covariance matching constraint. The class centralization constraint aims to enhance class discrimination by more closely clustering samples within classes. The covariance matching constraint seeks to achieve more accurate feature distribution matching between real and synthetic datasets through local feature covariance matrices, particularly beneficial when sample sizes are much smaller than the number of features. Experiments demonstrate notable improvements with these constraints, yielding performance boosts of up to 6.6% on CIFAR10, 2.9% on SVHN, 2.5% on CIFAR100, and 2.5% on TinyImageNet, compared to the state-of-the-art relevant methods. In addition, our method maintains robust performance in cross-architecture settings, with a maximum performance drop of 1.7% on four architectures. Code is available at https://github.com/VincenDen/IID.
Event-guided Multi-patch Network with Self-supervision for Non-uniform Motion Deblurring
Feb 14, 2023Contemporary deep learning multi-scale deblurring models suffer from many issues: 1) They perform poorly on non-uniformly blurred images/videos; 2) Simply increasing the model depth with finer-scale levels cannot improve deblurring; 3) Individual RGB frames contain a limited motion information for deblurring; 4) Previous models have a limited robustness to spatial transformations and noise. Below, we extend the DMPHN model by several mechanisms to address the above issues: I) We present a novel self-supervised event-guided deep hierarchical Multi-patch Network (MPN) to deal with blurry images and videos via fine-to-coarse hierarchical localized representations; II) We propose a novel stacked pipeline, StackMPN, to improve the deblurring performance under the increased network depth; III) We propose an event-guided architecture to exploit motion cues contained in videos to tackle complex blur in videos; IV) We propose a novel self-supervised step to expose the model to random transformations (rotations, scale changes), and make it robust to Gaussian noises. Our MPN achieves the state of the art on the GoPro and VideoDeblur datasets with a 40x faster runtime compared to current multi-scale methods. With 30ms to process an image at 1280x720 resolution, it is the first real-time deep motion deblurring model for 720p images at 30fps. For StackMPN, we obtain significant improvements over 1.2dB on the GoPro dataset by increasing the network depth. Utilizing the event information and self-supervision further boost results to 33.83dB.
Multi-level Second-order Few-shot Learning
Jan 15, 2022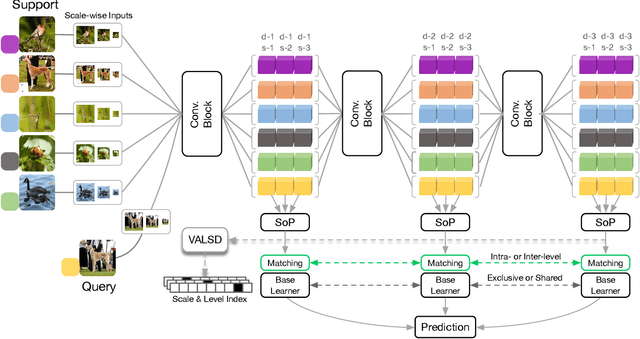
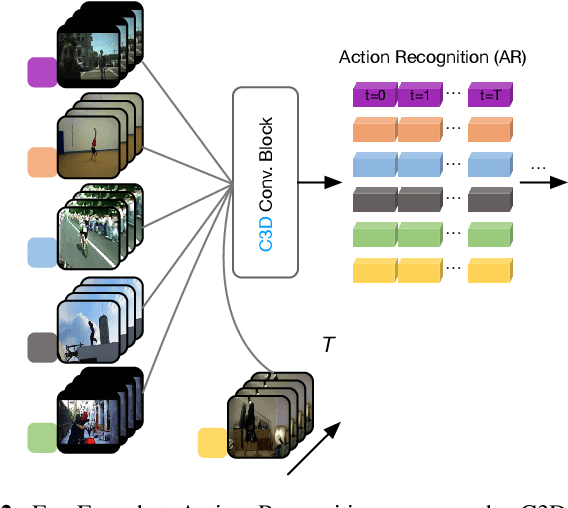
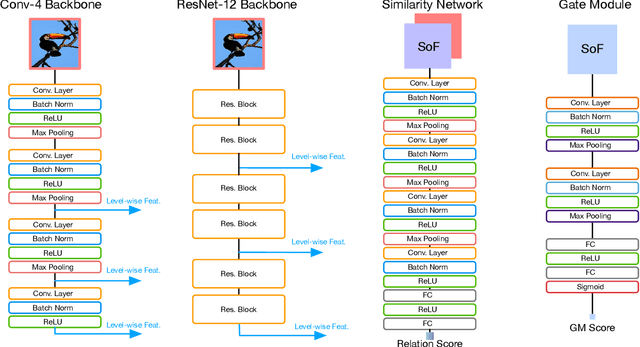
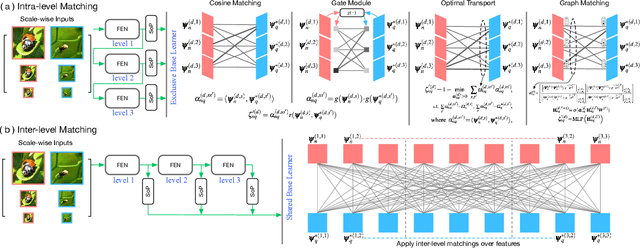
We propose a Multi-level Second-order (MlSo) few-shot learning network for supervised or unsupervised few-shot image classification and few-shot action recognition. We leverage so-called power-normalized second-order base learner streams combined with features that express multiple levels of visual abstraction, and we use self-supervised discriminating mechanisms. As Second-order Pooling (SoP) is popular in image recognition, we employ its basic element-wise variant in our pipeline. The goal of multi-level feature design is to extract feature representations at different layer-wise levels of CNN, realizing several levels of visual abstraction to achieve robust few-shot learning. As SoP can handle convolutional feature maps of varying spatial sizes, we also introduce image inputs at multiple spatial scales into MlSo. To exploit the discriminative information from multi-level and multi-scale features, we develop a Feature Matching (FM) module that reweights their respective branches. We also introduce a self-supervised step, which is a discriminator of the spatial level and the scale of abstraction. Our pipeline is trained in an end-to-end manner. With a simple architecture, we demonstrate respectable results on standard datasets such as Omniglot, mini-ImageNet, tiered-ImageNet, Open MIC, fine-grained datasets such as CUB Birds, Stanford Dogs and Cars, and action recognition datasets such as HMDB51, UCF101, and mini-MIT.
Power Normalizations in Fine-grained Image, Few-shot Image and Graph Classification
Dec 27, 2020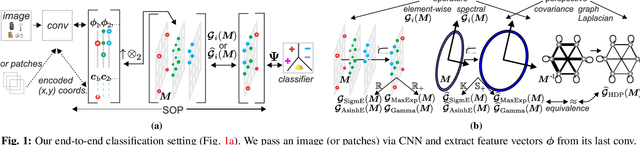
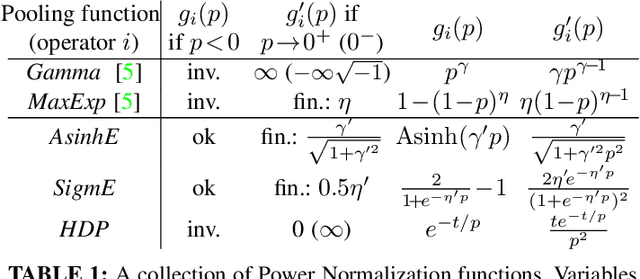
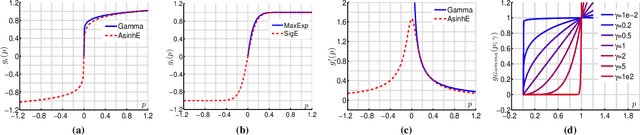

Power Normalizations (PN) are useful non-linear operators which tackle feature imbalances in classification problems. We study PNs in the deep learning setup via a novel PN layer pooling feature maps. Our layer combines the feature vectors and their respective spatial locations in the feature maps produced by the last convolutional layer of CNN into a positive definite matrix with second-order statistics to which PN operators are applied, forming so-called Second-order Pooling (SOP). As the main goal of this paper is to study Power Normalizations, we investigate the role and meaning of MaxExp and Gamma, two popular PN functions. To this end, we provide probabilistic interpretations of such element-wise operators and discover surrogates with well-behaved derivatives for end-to-end training. Furthermore, we look at the spectral applicability of MaxExp and Gamma by studying Spectral Power Normalizations (SPN). We show that SPN on the autocorrelation/covariance matrix and the Heat Diffusion Process (HDP) on a graph Laplacian matrix are closely related, thus sharing their properties. Such a finding leads us to the culmination of our work, a fast spectral MaxExp which is a variant of HDP for covariances/autocorrelation matrices. We evaluate our ideas on fine-grained recognition, scene recognition, and material classification, as well as in few-shot learning and graph classification.
Dual Pixel Exploration: Simultaneous Depth Estimation and Image Restoration
Dec 01, 2020
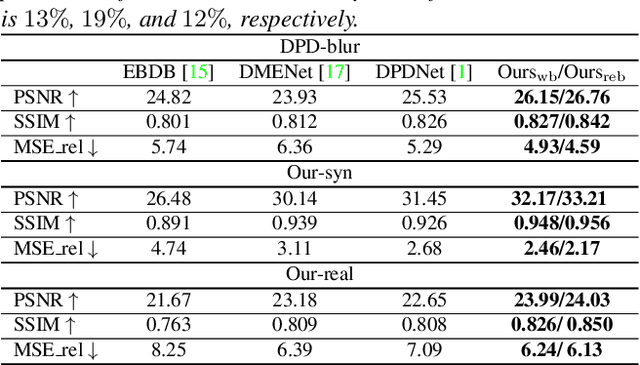
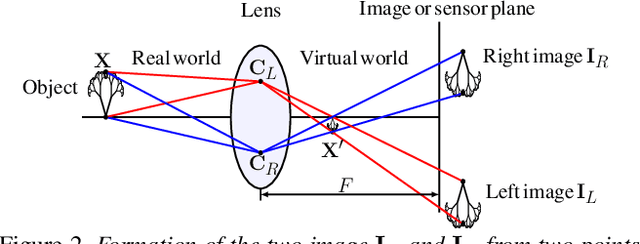
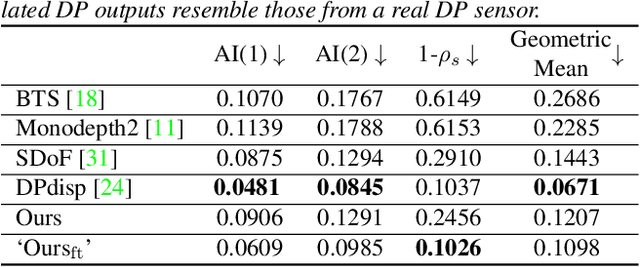
The dual-pixel (DP) hardware works by splitting each pixel in half and creating an image pair in a single snapshot. Several works estimate depth/inverse depth by treating the DP pair as a stereo pair. However, dual-pixel disparity only occurs in image regions with the defocus blur. The heavy defocus blur in DP pairs affects the performance of matching-based depth estimation approaches. Instead of removing the blur effect blindly, we study the formation of the DP pair which links the blur and the depth information. In this paper, we propose a mathematical DP model which can benefit depth estimation by the blur. These explorations motivate us to propose an end-to-end DDDNet (DP-based Depth and Deblur Network) to jointly estimate the depth and restore the image. Moreover, we define a reblur loss, which reflects the relationship of the DP image formation process with depth information, to regularise our depth estimate in training. To meet the requirement of a large amount of data for learning, we propose the first DP image simulator which allows us to create datasets with DP pairs from any existing RGBD dataset. As a side contribution, we collect a real dataset for further research. Extensive experimental evaluation on both synthetic and real datasets shows that our approach achieves competitive performance compared to state-of-the-art approaches.
Rethinking Class Relations: Absolute-relative Few-shot Learning
Jan 12, 2020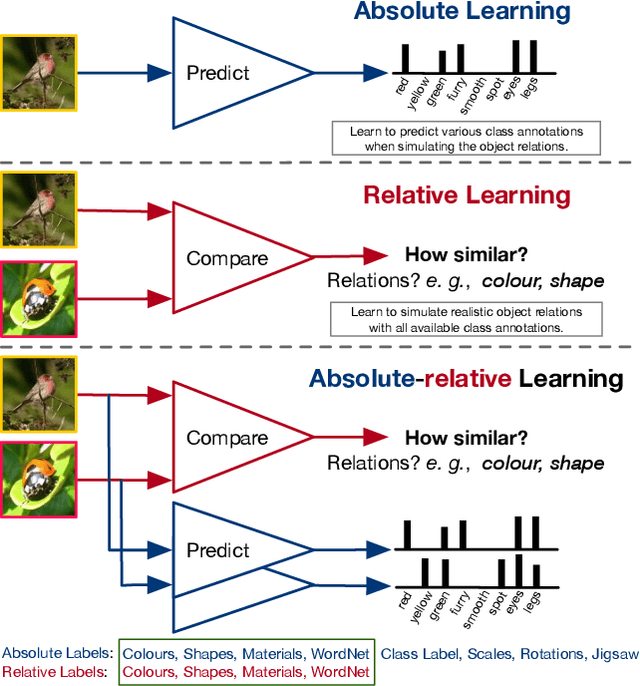
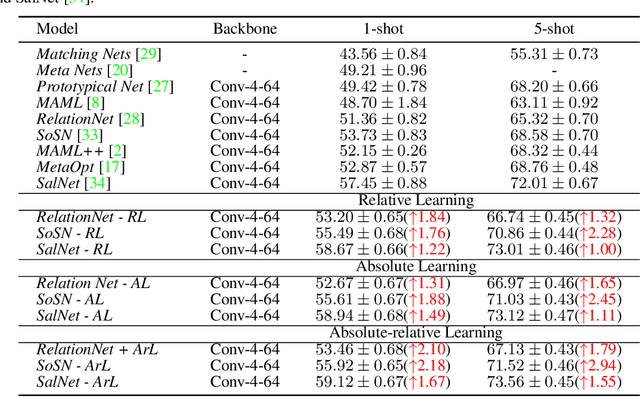
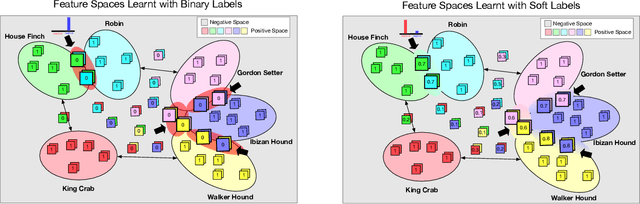
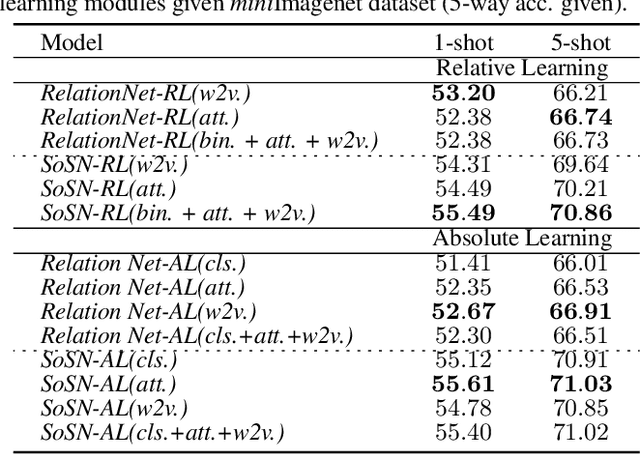
The majority of existing few-shot learning describe image relations with {0,1} binary labels. However, such binary relations are insufficient to teach the network complicated real-world relations, due to the lack of decision smoothness. Furthermore, current few-shot learning models capture only the similarity via relation labels, but they are not exposed to class concepts associated with objects, which is likely detrimental to the classification performance due to underutilization of the available class labels. To paraphrase, while children learn the concept of tiger from a few of examples with ease, and while they learn from comparisons of tiger to other animals, they are also taught the actual concept names. Thus, we hypothesize that in fact both similarity and class concept learning must be occurring simultaneously. With these observations at hand, we study the fundamental problem of simplistic class modeling in current few-shot learning, we rethink the relations between class concepts, and propose a novel absolute-relative learning paradigm to fully take advantage of label information to refine the image representations and correct the relation understanding. Our proposed absolute-relative learning paradigm improves the performance of several the state-of-the-art models on publicly available datasets.
Few-shot Action Recognition via Improved Attention with Self-supervision
Jan 12, 2020
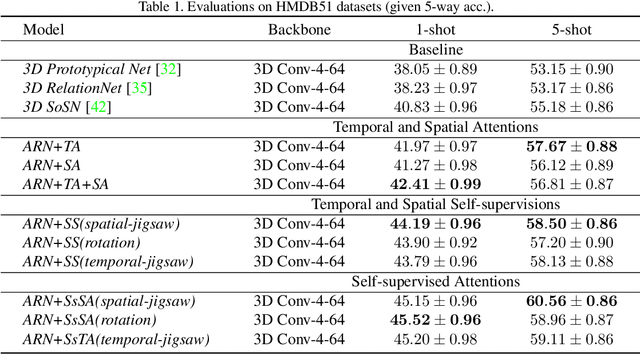
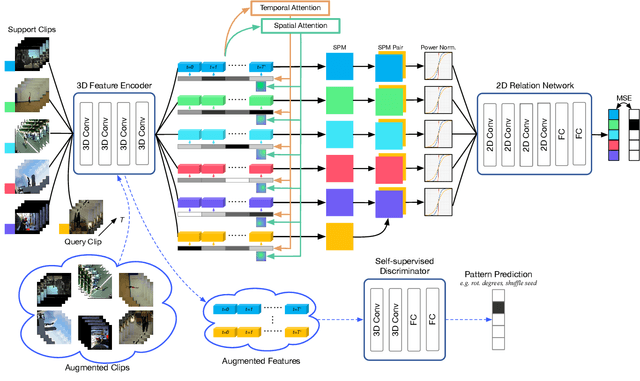
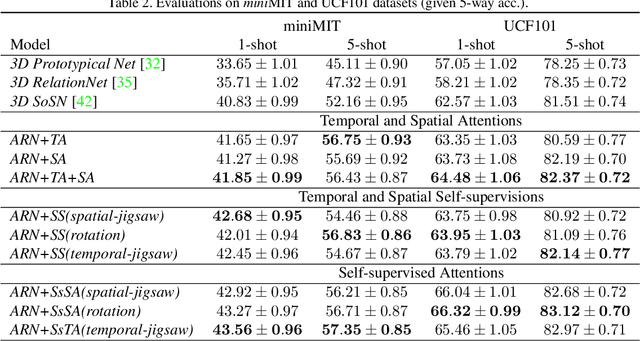
Most existing few-shot learning methods in computer vision focus on class recognition given a few of still images as the input. In contrast, this paper tackles a more challenging task of few-shot action-recognition from video clips. We propose a simple framework which is both flexible and easy to implement. Our approach exploits joint spatial and temporal attention mechanisms in conjunction with self-supervised representation learning on videos. This design encourages the model to discover and encode spatial and temporal attention hotspots important during the similarity learning between dynamic video sequences for which locations of discriminative patterns vary in the spatio-temporal sense. Our method compares favorably with several state-of-the-art baselines on HMDB51, miniMIT and UCF101 datasets, demonstrating its superior performance.
Few-shot Learning with Multi-scale Self-supervision
Jan 06, 2020
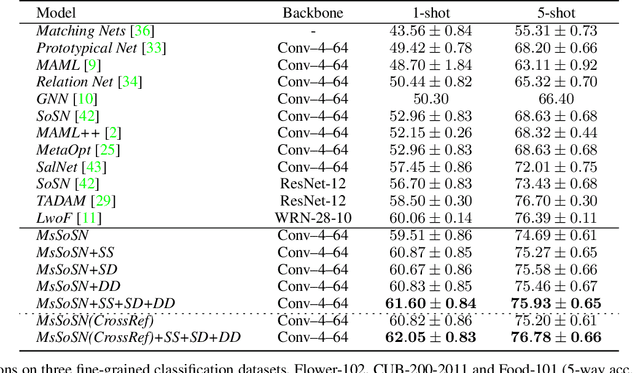
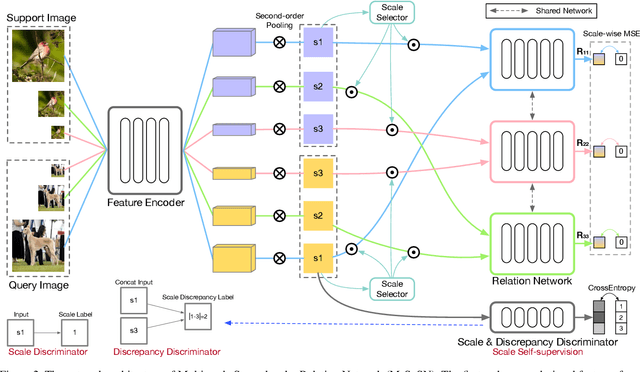
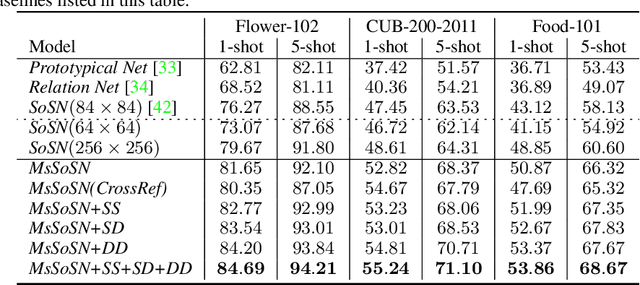
Learning concepts from the limited number of datapoints is a challenging task usually addressed by the so-called one- or few-shot learning. Recently, an application of second-order pooling in few-shot learning demonstrated its superior performance due to the aggregation step handling varying image resolutions without the need of modifying CNNs to fit to specific image sizes, yet capturing highly descriptive co-occurrences. However, using a single resolution per image (even if the resolution varies across a dataset) is suboptimal as the importance of image contents varies across the coarse-to-fine levels depending on the object and its class label e. g., generic objects and scenes rely on their global appearance while fine-grained objects rely more on their localized texture patterns. Multi-scale representations are popular in image deblurring, super-resolution and image recognition but they have not been investigated in few-shot learning due to its relational nature complicating the use of standard techniques. In this paper, we propose a novel multi-scale relation network based on the properties of second-order pooling to estimate image relations in few-shot setting. To optimize the model, we leverage a scale selector to re-weight scale-wise representations based on their second-order features. Furthermore, we propose to a apply self-supervised scale prediction. Specifically, we leverage an extra discriminator to predict the scale labels and the scale discrepancy between pairs of images. Our model achieves state-of-the-art results on standard few-shot learning datasets.