 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Action Recognition via Improved Attention with Self-supervision
Paper and Code
Jan 12, 2020
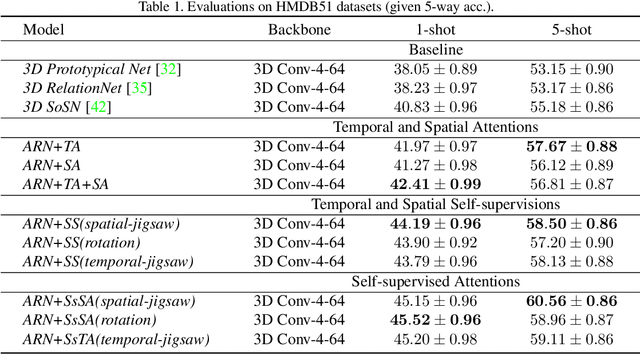
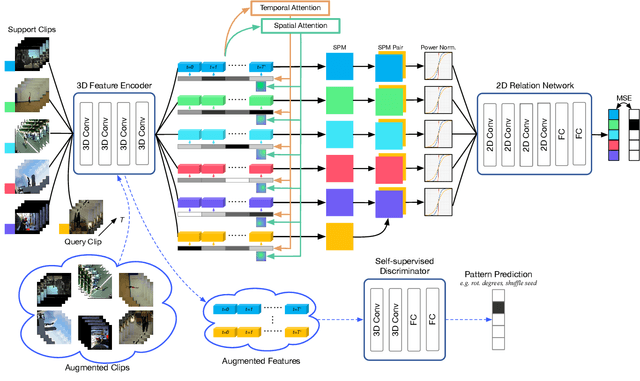
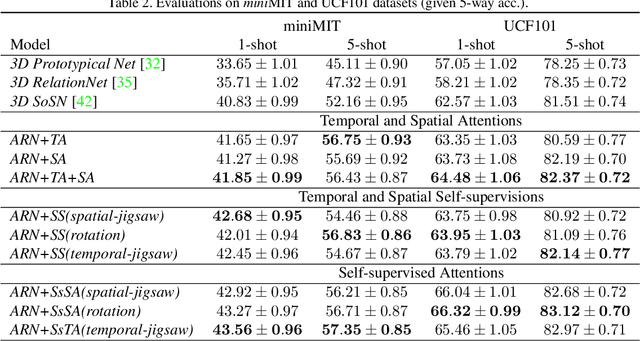
Most existing few-shot learning methods in computer vision focus on class recognition given a few of still images as the input. In contrast, this paper tackles a more challenging task of few-shot action-recognition from video clips. We propose a simple framework which is both flexible and easy to implement. Our approach exploits joint spatial and temporal attention mechanisms in conjunction with self-supervised representation learning on videos. This design encourages the model to discover and encode spatial and temporal attention hotspots important during the similarity learning between dynamic video sequences for which locations of discriminative patterns vary in the spatio-temporal sense. Our method compares favorably with several state-of-the-art baselines on HMDB51, miniMIT and UCF101 datasets, demonstrating its superior performance.