 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Uniform Clusters on Hypersphere for Deep Graph-level Clustering
Nov 23, 2023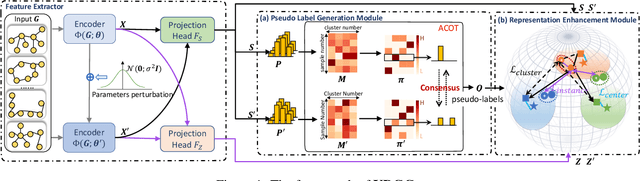



Graph clustering has been popularly studied in recent years. However, most existing graph clustering methods focus on node-level clustering, i.e., grouping nodes in a single graph into clusters. In contrast, graph-level clustering, i.e., grouping multiple graphs into clusters, remains largely unexplored. Graph-level clustering is critical in a variety of real-world applications, such as, properties prediction of molecules and community analysis in social networks. However, graph-level clustering is challenging due to the insufficient discriminability of graph-level representations, and the insufficient discriminability makes deep clustering be more likely to obtain degenerate solutions (cluster collapse). To address the issue, we propose a novel deep graph-level clustering method called Uniform Deep Graph Clustering (UDGC). UDGC assigns instances evenly to different clusters and then scatters those clusters on unit hypersphere, leading to a more uniform cluster-level distribution and a slighter cluster collapse. Specifically, we first propose Augmentation-Consensus Optimal Transport (ACOT) for generating uniformly distributed and reliable pseudo labels for partitioning clusters. Then we adopt contrastive learning to scatter those clusters. Besides, we propose Center Alignment Optimal Transport (CAOT) for guiding the model to learn better parameters, which further promotes the cluster performance. Our empirical study on eight well-known datasets demonstrates that UDGC significantly outperforms the state-of-the-art models.
Joint Local Relational Augmentation and Global Nash Equilibrium for Federated Learning with Non-IID Data
Aug 17, 2023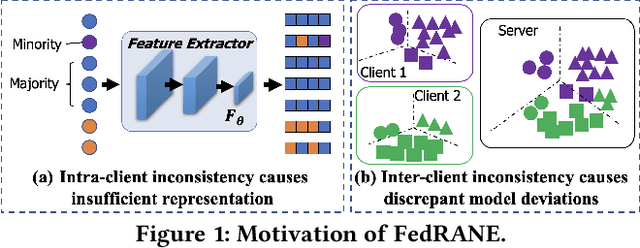
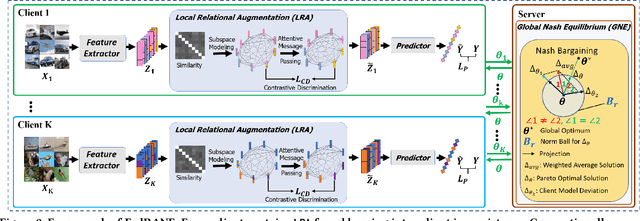
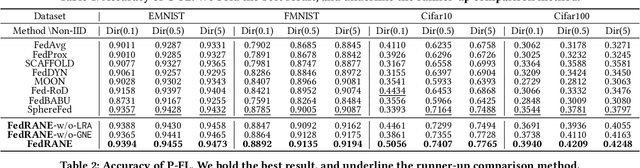
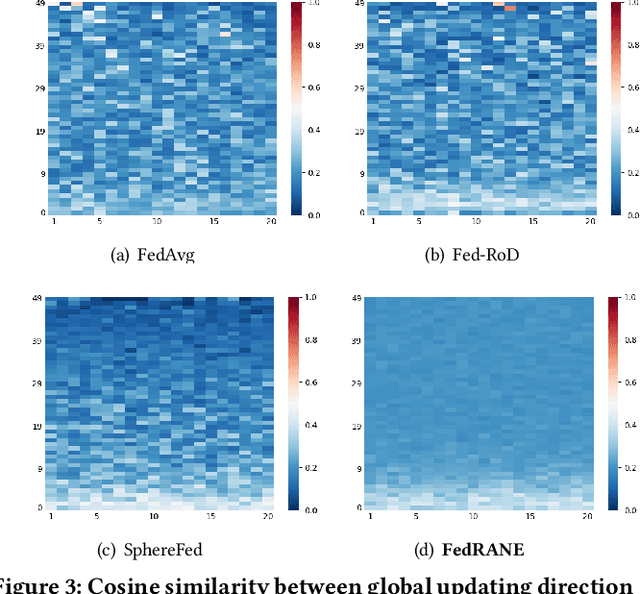
Federated learning (FL) is a distributed machine learning paradigm that needs collaboration between a server and a series of clients with decentralized data. To make FL effective in real-world applications, existing work devotes to improving the modeling of decentralized data with non-independent and identical distributions (non-IID). In non-IID settings, there are intra-client inconsistency that comes from the imbalanced data modeling, and inter-client inconsistency among heterogeneous client distributions, which not only hinders sufficient representation of the minority data, but also brings discrepant model deviations. However, previous work overlooks to tackle the above two coupling inconsistencies together. In this work, we propose FedRANE, which consists of two main modules, i.e., local relational augmentation (LRA) and global Nash equilibrium (GNE), to resolve intra- and inter-client inconsistency simultaneously. Specifically, in each client, LRA mines the similarity relations among different data samples and enhances the minority sample representations with their neighbors using attentive message passing. In server, GNE reaches an agreement among inconsistent and discrepant model deviations from clients to server, which encourages the global model to update in the direction of global optimum without breaking down the clients optimization toward their local optimums. We conduct extensive experiments on four benchmark datasets to show the superiority of FedRANE in enhancing the performance of FL with non-IID data.
Robust Representation Learning with Reliable Pseudo-labels Generation via Self-Adaptive Optimal Transport for Short Text Clustering
May 23, 2023



Short text clustering is challenging since it takes imbalanced and noisy data as inputs. Existing approaches cannot solve this problem well, since (1) they are prone to obtain degenerate solutions especially on heavy imbalanced datasets, and (2) they are vulnerable to noises. To tackle the above issues, we propose a Robust Short Text Clustering (RSTC) model to improve robustness against imbalanced and noisy data. RSTC includes two modules, i.e., pseudo-label generation module and robust representation learning module. The former generates pseudo-labels to provide supervision for the later, which contributes to more robust representations and correctly separated clusters. To provide robustness against the imbalance in data, we propose self-adaptive optimal transport in the pseudo-label generation module. To improve robustness against the noise in data, we further introduce both class-wise and instance-wise contrastive learning in the robust representation learning module. Our empirical studies on eight short text clustering datasets demonstrate that RSTC significantly outperforms the state-of-the-art models. The code is available at: https://github.com/hmllmh/RSTC.
Exploiting Variational Domain-Invariant User Embedding for Partially Overlapped Cross Domain Recommendation
May 13, 2022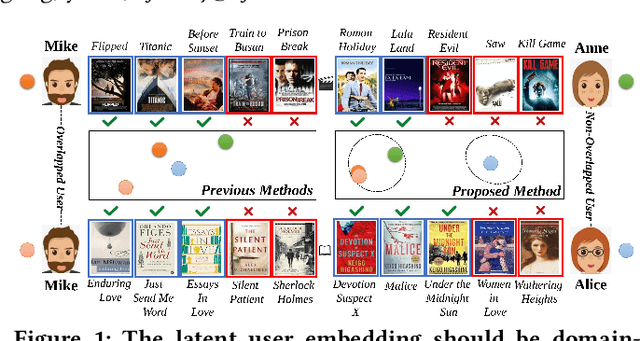



Cross-Domain Recommendation (CDR) has been popularly studied to utilize different domain knowledge to solve the cold-start problem in recommender systems. Most of the existing CDR models assume that both the source and target domains share the same overlapped user set for knowledge transfer. However, only few proportion of users simultaneously activate on both the source and target domains in practical CDR tasks. In this paper, we focus on the Partially Overlapped Cross-Domain Recommendation (POCDR) problem, that is, how to leverage the information of both the overlapped and non-overlapped users to improve recommendation performance. Existing approaches cannot fully utilize the useful knowledge behind the non-overlapped users across domains, which limits the model performance when the majority of users turn out to be non-overlapped. To address this issue, we propose an end-to-end dual-autoencoder with Variational Domain-invariant Embedding Alignment (VDEA) model, a cross-domain recommendation framework for the POCDR problem, which utilizes dual variational autoencoders with both local and global embedding alignment for exploiting domain-invariant user embedding. VDEA first adopts variational inference to capture collaborative user preferences, and then utilizes Gromov-Wasserstein distribution co-clustering optimal transport to cluster the users with similar rating interaction behaviors. Our empirical studies on Douban and Amazon datasets demonstrate that VDEA significantly outperforms the state-of-the-art models, especially under the POCDR setting.
Collaborative Filtering with Attribution Alignment for Review-based Non-overlapped Cross Domain Recommendation
Feb 10, 2022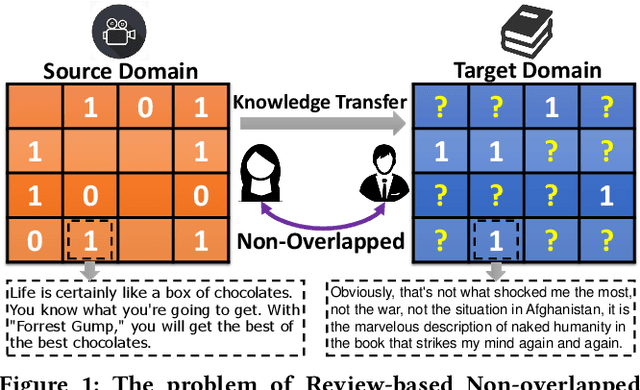
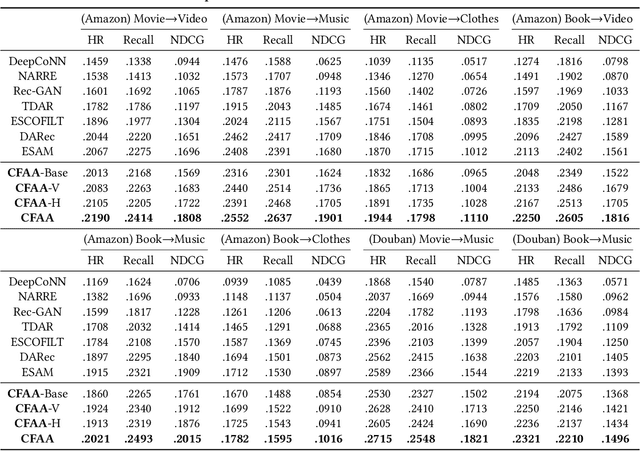
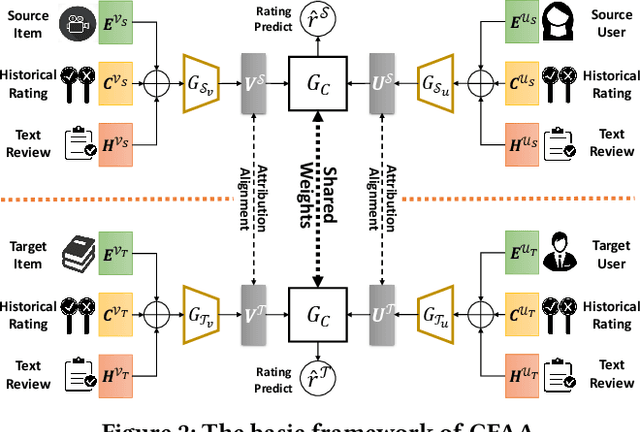
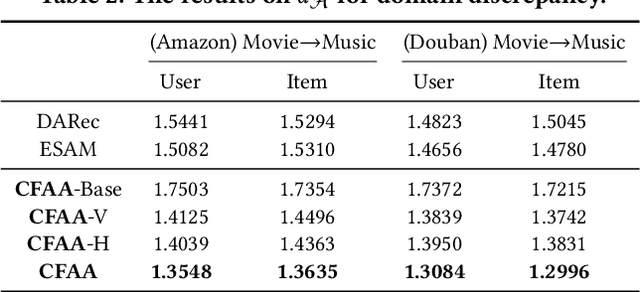
Cross-Domain Recommendation (CDR) has been popularly studied to utilize different domain knowledge to solve the data sparsity and cold-start problem in recommender systems. In this paper, we focus on the Review-based Non-overlapped Recommendation (RNCDR) problem. The problem is commonly-existed and challenging due to two main aspects, i.e, there are only positive user-item ratings on the target domain and there is no overlapped user across different domains. Most previous CDR approaches cannot solve the RNCDR problem well, since (1) they cannot effectively combine review with other information (e.g., ID or ratings) to obtain expressive user or item embedding, (2) they cannot reduce the domain discrepancy on users and items. To fill this gap, we propose Collaborative Filtering with Attribution Alignment model (CFAA), a cross-domain recommendation framework for the RNCDR problem. CFAA includes two main modules, i.e., rating prediction module and embedding attribution alignment module. The former aims to jointly mine review, one-hot ID, and multi-hot historical ratings to generate expressive user and item embeddings. The later includes vertical attribution alignment and horizontal attribution alignment, tending to reduce the discrepancy based on multiple perspectives. Our empirical study on Douban and Amazon datasets demonstrates that CFAA significantly outperforms the state-of-the-art models under the RNCDR setting.