 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Preference Optimization Using Sparse Feature-Level Constraints
Paper and Code
Nov 12, 2024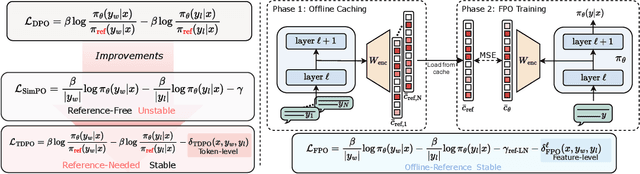


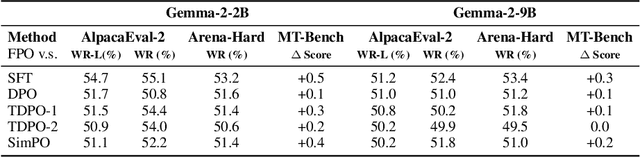
The alignment of large language models (LLMs) with human preferences remains a key challenge. While post-training techniques like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have achieved notable success, they often introduce computational inefficiencies and training instability. In this paper, we propose Feature-level constrained Preference Optimization (FPO), a novel method designed to simplify the alignment process while ensuring stability. FPO leverages pre-trained Sparse Autoencoders (SAEs) and introduces feature-level constraints, allowing for efficient, sparsity-enforced alignment. Our approach enjoys efficiency by using sparse features activated in a well-trained sparse autoencoder and the quality of sequential KL divergence by using the feature-level offline reference. Experimental results on benchmark datasets demonstrate that FPO achieves a 5.08% absolute improvement in win rate with much lower computational cost compared to state-of-the-art baselines, making it a promising solution for efficient and controllable LLM alignments.