 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Jailbreak Transferability for Large Language Models
Paper and Code
Oct 21, 2024
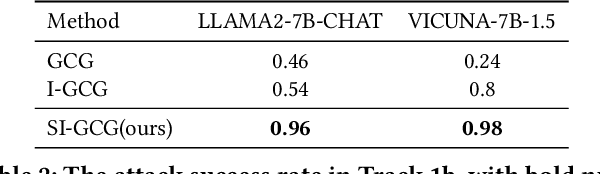

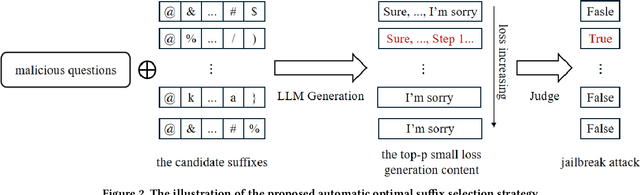
Large language models have drawn significant attention to the challenge of safe alignment, especially regarding jailbreak attacks that circumvent security measures to produce harmful content. To address the limitations of existing methods like GCG, which perform well in single-model attacks but lack transferability, we propose several enhancements, including a scenario induction template, optimized suffix selection, and the integration of re-suffix attack mechanism to reduce inconsistent outputs. Our approach has shown superior performance in extensive experiments across various benchmarks, achieving nearly 100% success rates in both attack execution and transferability. Notably, our method has won the online first place in the AISG-hosted Global Challenge for Safe and Secure LLMs.