 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObscure but Effective: Classical Chinese Jailbreak Prompt Optimization via Bio-Inspired Search
Feb 26, 2026As Large Language Models (LLMs) are increasingly used, their security risks have drawn increasing attention. Existing research reveals that LLMs are highly susceptible to jailbreak attacks, with effectiveness varying across language contexts. This paper investigates the role of classical Chinese in jailbreak attacks. Owing to its conciseness and obscurity, classical Chinese can partially bypass existing safety constraints, exposing notable vulnerabilities in LLMs. Based on this observation, this paper proposes a framework, CC-BOS, for the automatic generation of classical Chinese adversarial prompts based on multi-dimensional fruit fly optimization, facilitating efficient and automated jailbreak attacks in black-box settings. Prompts are encoded into eight policy dimensions-covering role, behavior, mechanism, metaphor, expression, knowledge, trigger pattern and context; and iteratively refined via smell search, visual search, and cauchy mutation. This design enables efficient exploration of the search space, thereby enhancing the effectiveness of black-box jailbreak attacks. To enhance readability and evaluation accuracy, we further design a classical Chinese to English translation module. Extensive experiments demonstrate that effectiveness of the proposed CC-BOS, consistently outperforming state-of-the-art jailbreak attack methods.
Distillation-Enhanced Physical Adversarial Attacks
Jan 04, 2025



The study of physical adversarial patches is crucial for identifying vulnerabilities in AI-based recognition systems and developing more robust deep learning models. While recent research has focused on improving patch stealthiness for greater practical applicability, achieving an effective balance between stealth and attack performance remains a significant challenge. To address this issue, we propose a novel physical adversarial attack method that leverages knowledge distillation. Specifically, we first define a stealthy color space tailored to the target environment to ensure smooth blending. Then, we optimize an adversarial patch in an unconstrained color space, which serves as the 'teacher' patch. Finally, we use an adversarial knowledge distillation module to transfer the teacher patch's knowledge to the 'student' patch, guiding the optimization of the stealthy patch. Experimental results show that our approach improves attack performance by 20%, while maintaining stealth, highlighting its practical value.
CapGen:An Environment-Adaptive Generator of Adversarial Patches
Dec 10, 2024



Adversarial patches, often used to provide physical stealth protection for critical assets and assess perception algorithm robustness, usually neglect the need for visual harmony with the background environment, making them easily noticeable. Moreover, existing methods primarily concentrate on improving attack performance, disregarding the intricate dynamics of adversarial patch elements. In this work, we introduce the Camouflaged Adversarial Pattern Generator (CAPGen), a novel approach that leverages specific base colors from the surrounding environment to produce patches that seamlessly blend with their background for superior visual stealthiness while maintaining robust adversarial performance. We delve into the influence of both patterns (i.e., color-agnostic texture information) and colors on the effectiveness of attacks facilitated by patches, discovering that patterns exert a more pronounced effect on performance than colors. Based on these findings, we propose a rapid generation strategy for adversarial patches. This involves updating the colors of high-performance adversarial patches to align with those of the new environment, ensuring visual stealthiness without compromising adversarial impact. This paper is the first to comprehensively examine the roles played by patterns and colors in the context of adversarial patches.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


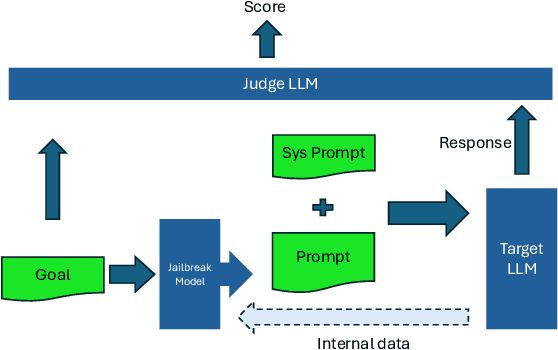
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
Prompt-Guided Environmentally Consistent Adversarial Patch
Nov 15, 2024



Adversarial attacks in the physical world pose a significant threat to the security of vision-based systems, such as facial recognition and autonomous driving. Existing adversarial patch methods primarily focus on improving attack performance, but they often produce patches that are easily detectable by humans and struggle to achieve environmental consistency, i.e., blending patches into the environment. This paper introduces a novel approach for generating adversarial patches, which addresses both the visual naturalness and environmental consistency of the patches. We propose Prompt-Guided Environmentally Consistent Adversarial Patch (PG-ECAP), a method that aligns the patch with the environment to ensure seamless integration into the environment. The approach leverages diffusion models to generate patches that are both environmental consistency and effective in evading detection. To further enhance the naturalness and consistency, we introduce two alignment losses: Prompt Alignment Loss and Latent Space Alignment Loss, ensuring that the generated patch maintains its adversarial properties while fitting naturally within its environment. Extensive experiments in both digital and physical domains demonstrate that PG-ECAP outperforms existing methods in attack success rate and environmental consistency.
Boosting Jailbreak Transferability for Large Language Models
Oct 21, 2024
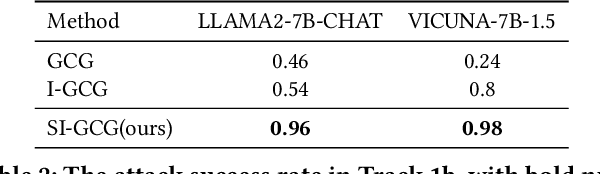

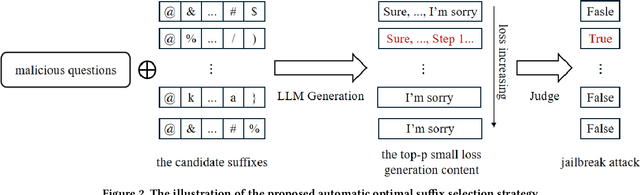
Large language models have drawn significant attention to the challenge of safe alignment, especially regarding jailbreak attacks that circumvent security measures to produce harmful content. To address the limitations of existing methods like GCG, which perform well in single-model attacks but lack transferability, we propose several enhancements, including a scenario induction template, optimized suffix selection, and the integration of re-suffix attack mechanism to reduce inconsistent outputs. Our approach has shown superior performance in extensive experiments across various benchmarks, achieving nearly 100% success rates in both attack execution and transferability. Notably, our method has won the online first place in the AISG-hosted Global Challenge for Safe and Secure LLMs.
Improving Adversarial Transferability with Spatial Momentum
Mar 25, 2022
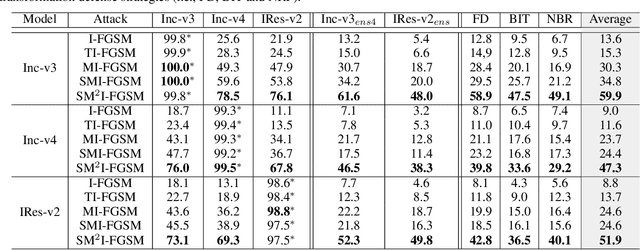
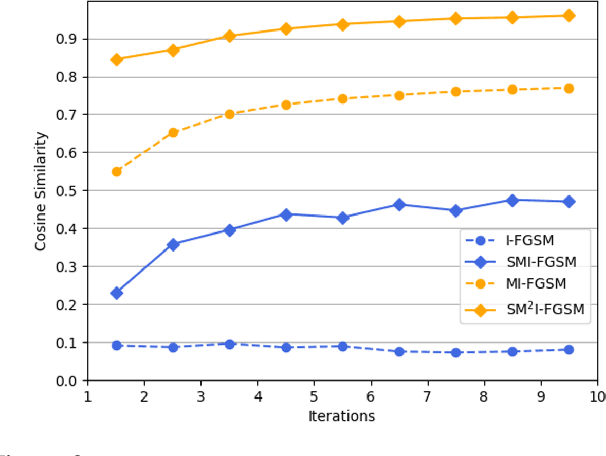

Deep Neural Networks (DNN) are vulnerable to adversarial examples. Although many adversarial attack methods achieve satisfactory attack success rates under the white-box setting, they usually show poor transferability when attacking other DNN models. Momentum-based attack (MI-FGSM) is one effective method to improve transferability. It integrates the momentum term into the iterative process, which can stabilize the update directions by adding the gradients' temporal correlation for each pixel. We argue that only this temporal momentum is not enough, the gradients from the spatial domain within an image, i.e. gradients from the context pixels centered on the target pixel are also important to the stabilization. For that, in this paper, we propose a novel method named Spatial Momentum Iterative FGSM Attack (SMI-FGSM), which introduces the mechanism of momentum accumulation from temporal domain to spatial domain by considering the context gradient information from different regions within the image. SMI-FGSM is then integrated with MI-FGSM to simultaneously stabilize the gradients' update direction from both the temporal and spatial domain. The final method is called SM$^2$I-FGSM. Extensive experiments are conducted on the ImageNet dataset and results show that SM$^2$I-FGSM indeed further enhances the transferability. It achieves the best transferability success rate for multiple mainstream undefended and defended models, which outperforms the state-of-the-art methods by a large margin.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021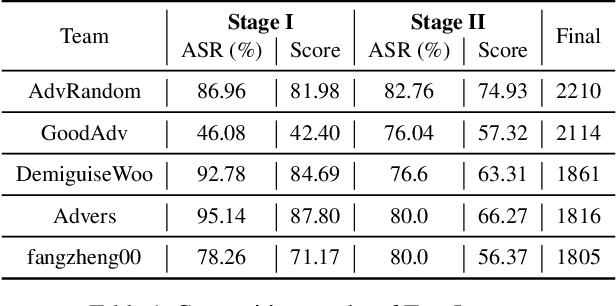
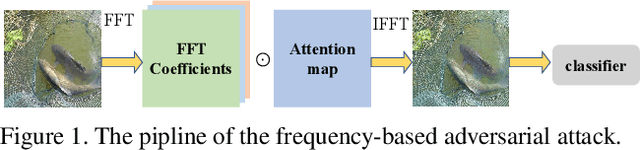
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
An Effective and Robust Detector for Logo Detection
Aug 01, 2021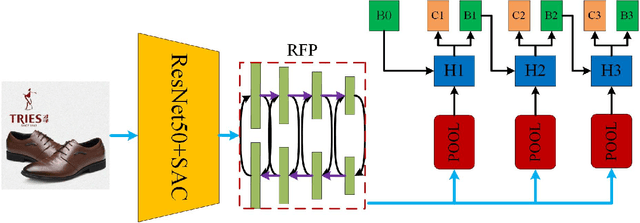


In recent years, intellectual property (IP), which represents literary, inventions, artistic works, etc, gradually attract more and more people's attention. Particularly, with the rise of e-commerce, the IP not only represents the product design and brands, but also represents the images/videos displayed on e-commerce platforms. Unfortunately, some attackers adopt some adversarial methods to fool the well-trained logo detection model for infringement. To overcome this problem, a novel logo detector based on the mechanism of looking and thinking twice is proposed in this paper for robust logo detection. The proposed detector is different from other mainstream detectors, which can effectively detect small objects, long-tail objects, and is robust to adversarial images. In detail, we extend detectoRS algorithm to a cascade schema with an equalization loss function, multi-scale transformations, and adversarial data augmentation. A series of experimental results have shown that the proposed method can effectively improve the robustness of the detection model. Moreover, we have applied the proposed methods to competition ACM MM2021 Robust Logo Detection that is organized by Alibaba on the Tianchi platform and won top 2 in 36489 teams. Code is available at https://github.com/jiaxiaojunQAQ/Robust-Logo-Detection.
Improving Adversarial Transferability with Gradient Refining
May 11, 2021

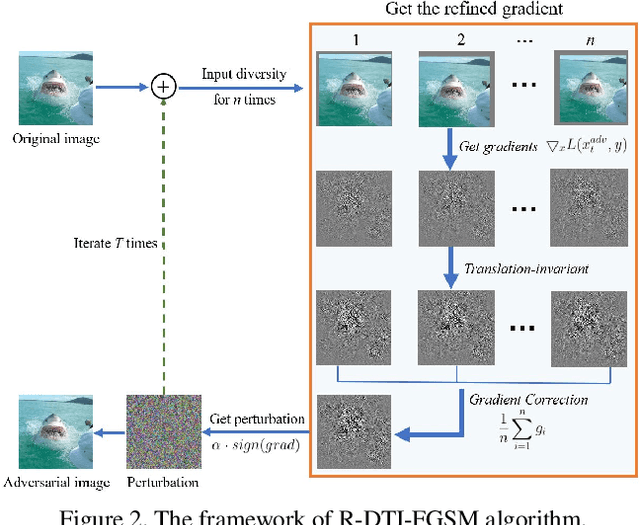
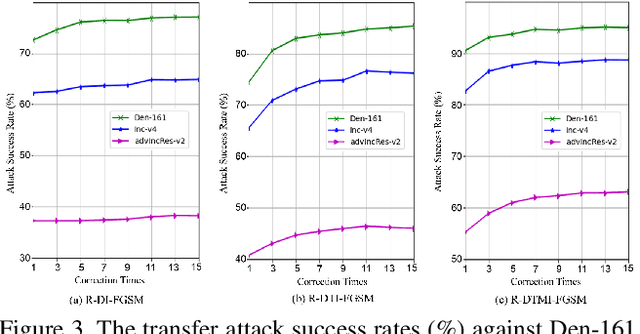
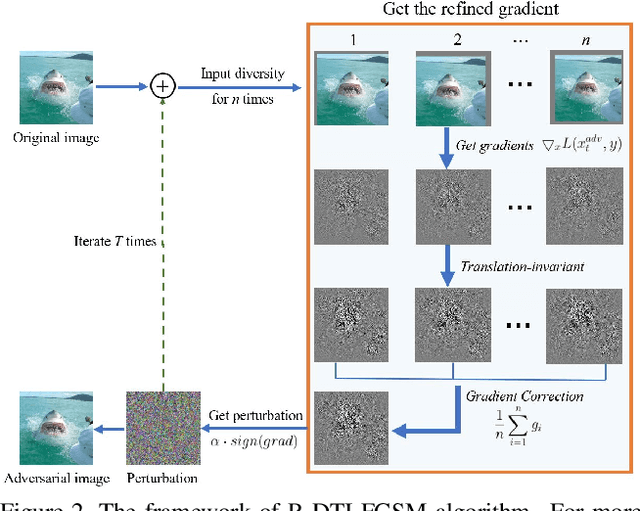
Deep neural networks are vulnerable to adversarial examples, which are crafted by adding human-imperceptible perturbations to original images. Most existing adversarial attack methods achieve nearly 100% attack success rates under the white-box setting, but only achieve relatively low attack success rates under the black-box setting. To improve the transferability of adversarial examples for the black-box setting, several methods have been proposed, e.g., input diversity, translation-invariant attack, and momentum-based attack. In this paper, we propose a method named Gradient Refining, which can further improve the adversarial transferability by correcting useless gradients introduced by input diversity through multiple transformations. Our method is generally applicable to many gradient-based attack methods combined with input diversity. Extensive experiments are conducted on the ImageNet dataset and our method can achieve an average transfer success rate of 82.07% for three different models under single-model setting, which outperforms the other state-of-the-art methods by a large margin of 6.0% averagely. And we have applied the proposed method to the competition CVPR 2021 Unrestricted Adversarial Attacks on ImageNet organized by Alibaba and won the second place in attack success rates among 1558 teams.