 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Utility Conflicts Are Not Global: Surgical Alignment via Head-Level Diagnosis
Jan 07, 2026Safety alignment in Large Language Models (LLMs) inherently presents a multi-objective optimization conflict, often accompanied by an unintended degradation of general capabilities. Existing mitigation strategies typically rely on global gradient geometry to resolve these conflicts, yet they overlook Modular Heterogeneity within Transformers, specifically that the functional sensitivity and degree of conflict vary substantially across different attention heads. Such global approaches impose uniform update rules across all parameters, often resulting in suboptimal trade-offs by indiscriminately updating utility sensitive heads that exhibit intense gradient conflicts. To address this limitation, we propose Conflict-Aware Sparse Tuning (CAST), a framework that integrates head-level diagnosis with sparse fine-tuning. CAST first constructs a pre-alignment conflict map by synthesizing Optimization Conflict and Functional Sensitivity, which then guides the selective update of parameters. Experiments reveal that alignment conflicts in LLMs are not uniformly distributed. We find that the drop in general capabilities mainly comes from updating a small group of ``high-conflict'' heads. By simply skipping these heads during training, we significantly reduce this loss without compromising safety, offering an interpretable and parameter-efficient approach to improving the safety-utility trade-off.
Improving Adversarial Transferability with Spatial Momentum
Mar 25, 2022
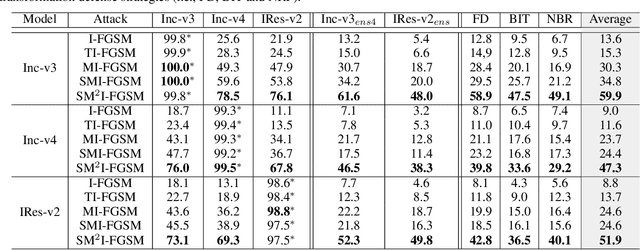
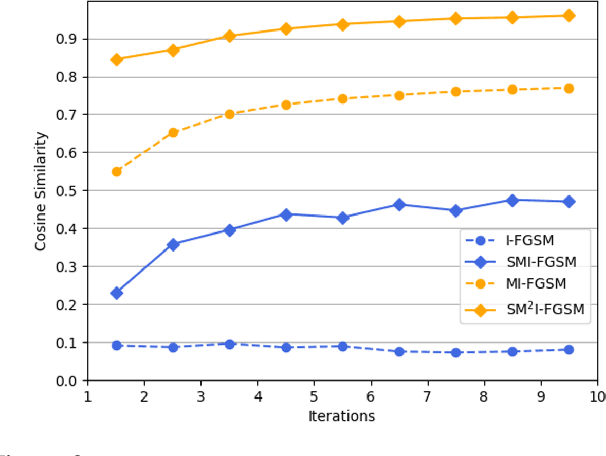

Deep Neural Networks (DNN) are vulnerable to adversarial examples. Although many adversarial attack methods achieve satisfactory attack success rates under the white-box setting, they usually show poor transferability when attacking other DNN models. Momentum-based attack (MI-FGSM) is one effective method to improve transferability. It integrates the momentum term into the iterative process, which can stabilize the update directions by adding the gradients' temporal correlation for each pixel. We argue that only this temporal momentum is not enough, the gradients from the spatial domain within an image, i.e. gradients from the context pixels centered on the target pixel are also important to the stabilization. For that, in this paper, we propose a novel method named Spatial Momentum Iterative FGSM Attack (SMI-FGSM), which introduces the mechanism of momentum accumulation from temporal domain to spatial domain by considering the context gradient information from different regions within the image. SMI-FGSM is then integrated with MI-FGSM to simultaneously stabilize the gradients' update direction from both the temporal and spatial domain. The final method is called SM$^2$I-FGSM. Extensive experiments are conducted on the ImageNet dataset and results show that SM$^2$I-FGSM indeed further enhances the transferability. It achieves the best transferability success rate for multiple mainstream undefended and defended models, which outperforms the state-of-the-art methods by a large margin.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021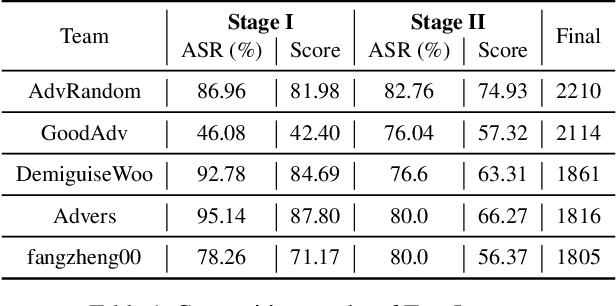
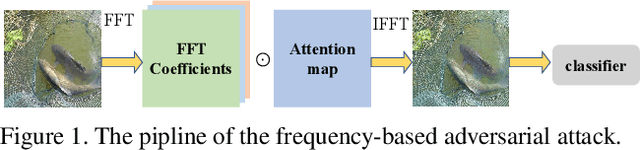
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Improving Adversarial Transferability with Gradient Refining
May 11, 2021

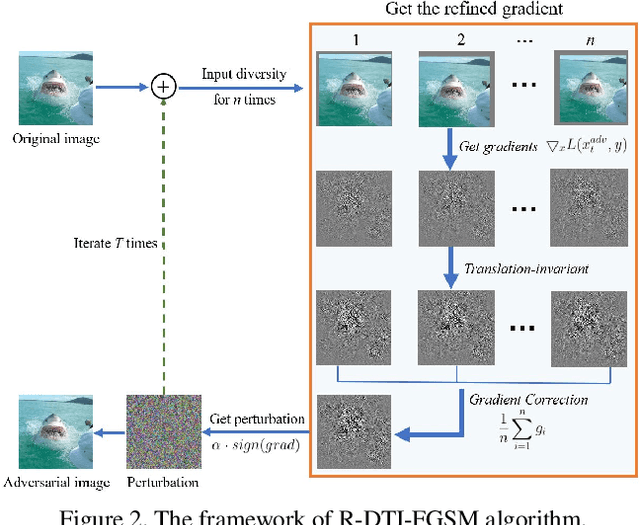
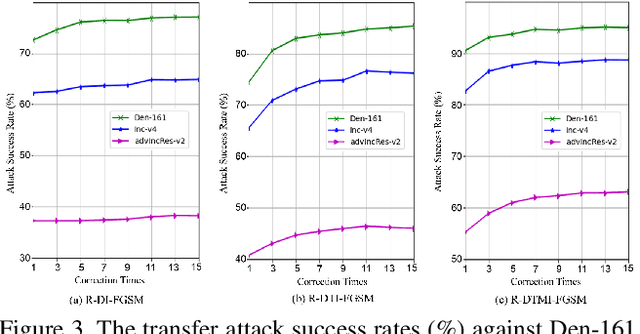
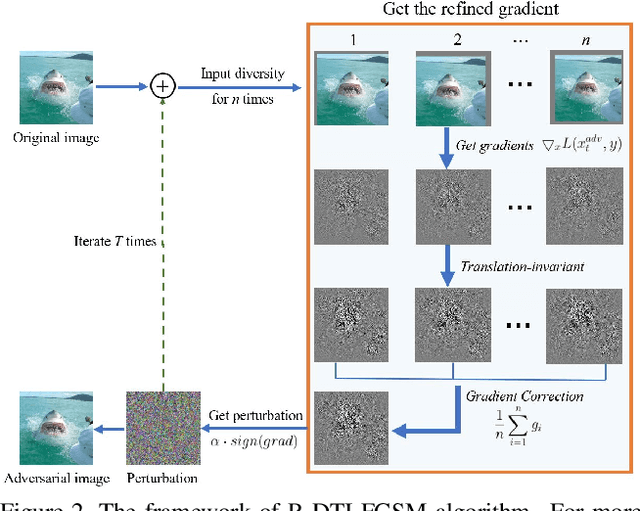
Deep neural networks are vulnerable to adversarial examples, which are crafted by adding human-imperceptible perturbations to original images. Most existing adversarial attack methods achieve nearly 100% attack success rates under the white-box setting, but only achieve relatively low attack success rates under the black-box setting. To improve the transferability of adversarial examples for the black-box setting, several methods have been proposed, e.g., input diversity, translation-invariant attack, and momentum-based attack. In this paper, we propose a method named Gradient Refining, which can further improve the adversarial transferability by correcting useless gradients introduced by input diversity through multiple transformations. Our method is generally applicable to many gradient-based attack methods combined with input diversity. Extensive experiments are conducted on the ImageNet dataset and our method can achieve an average transfer success rate of 82.07% for three different models under single-model setting, which outperforms the other state-of-the-art methods by a large margin of 6.0% averagely. And we have applied the proposed method to the competition CVPR 2021 Unrestricted Adversarial Attacks on ImageNet organized by Alibaba and won the second place in attack success rates among 1558 teams.
Meaningful Adversarial Stickers for Face Recognition in Physical World
Apr 14, 2021



Face recognition (FR) systems have been widely applied in safety-critical fields with the introduction of deep learning. However, the existence of adversarial examples brings potential security risks to FR systems. To identify their vulnerability and help improve their robustness, in this paper, we propose Meaningful Adversarial Stickers, a physically feasible and easily implemented attack method by using meaningful real stickers existing in our life, where the attackers manipulate the pasting parameters of stickers on the face, instead of designing perturbation patterns and then printing them like most existing works. We conduct attacks in the black-box setting with limited information which is more challenging and practical. To effectively solve the pasting position, rotation angle, and other parameters of the stickers, we design Region based Heuristic Differential Algorithm, which utilizes the inbreeding strategy based on regional aggregation of effective solutions and the adaptive adjustment strategy of evaluation criteria. Extensive experiments are conducted on two public datasets including LFW and CelebA with respective to three representative FR models like FaceNet, SphereFace, and CosFace, achieving attack success rates of 81.78%, 72.93%, and 79.26% respectively with only hundreds of queries. The results in the physical world confirm the effectiveness of our method in complex physical conditions. When continuously changing the face posture of testers, the method can still perform successful attacks up to 98.46%, 91.30% and 86.96% in the time series.