 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming
May 29, 2025Despite the promise of autonomous agentic reasoning, existing workflow generation methods frequently produce fragile, unexecutable plans due to unconstrained LLM-driven construction. We introduce MermaidFlow, a framework that redefines the agentic search space through safety-constrained graph evolution. At its core, MermaidFlow represent workflows as a verifiable intermediate representation using Mermaid, a structured and human-interpretable graph language. We formulate domain-aware evolutionary operators, i.e., crossover, mutation, insertion, and deletion, to preserve semantic correctness while promoting structural diversity, enabling efficient exploration of a high-quality, statically verifiable workflow space. Without modifying task settings or evaluation protocols, MermaidFlow achieves consistent improvements in success rates and faster convergence to executable plans on the agent reasoning benchmark. The experimental results demonstrate that safety-constrained graph evolution offers a scalable, modular foundation for robust and interpretable agentic reasoning systems.
State Chrono Representation for Enhancing Generalization in Reinforcement Learning
Nov 09, 2024



In reinforcement learning with image-based inputs, it is crucial to establish a robust and generalizable state representation. Recent advancements in metric learning, such as deep bisimulation metric approaches, have shown promising results in learning structured low-dimensional representation space from pixel observations, where the distance between states is measured based on task-relevant features. However, these approaches face challenges in demanding generalization tasks and scenarios with non-informative rewards. This is because they fail to capture sufficient long-term information in the learned representations. To address these challenges, we propose a novel State Chrono Representation (SCR) approach. SCR augments state metric-based representations by incorporating extensive temporal information into the update step of bisimulation metric learning. It learns state distances within a temporal framework that considers both future dynamics and cumulative rewards over current and long-term future states. Our learning strategy effectively incorporates future behavioral information into the representation space without introducing a significant number of additional parameters for modeling dynamics. Extensive experiments conducted in DeepMind Control and Meta-World environments demonstrate that SCR achieves better performance comparing to other recent metric-based methods in demanding generalization tasks. The codes of SCR are available in https://github.com/jianda-chen/SCR.
Off-dynamics Conditional Diffusion Planners
Oct 16, 2024

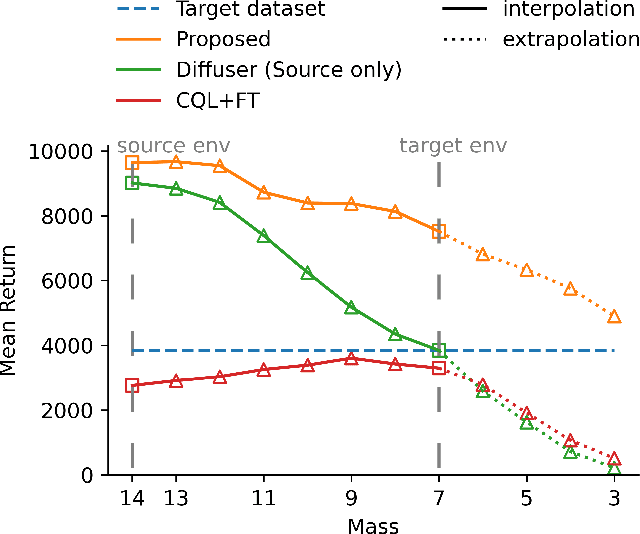
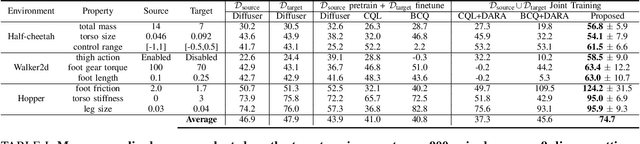
Offline Reinforcement Learning (RL) offers an attractive alternative to interactive data acquisition by leveraging pre-existing datasets. However, its effectiveness hinges on the quantity and quality of the data samples. This work explores the use of more readily available, albeit off-dynamics datasets, to address the challenge of data scarcity in Offline RL. We propose a novel approach using conditional Diffusion Probabilistic Models (DPMs) to learn the joint distribution of the large-scale off-dynamics dataset and the limited target dataset. To enable the model to capture the underlying dynamics structure, we introduce two contexts for the conditional model: (1) a continuous dynamics score allows for partial overlap between trajectories from both datasets, providing the model with richer information; (2) an inverse-dynamics context guides the model to generate trajectories that adhere to the target environment's dynamic constraints. Empirical results demonstrate that our method significantly outperforms several strong baselines. Ablation studies further reveal the critical role of each dynamics context. Additionally, our model demonstrates that by modifying the context, we can interpolate between source and target dynamics, making it more robust to subtle shifts in the environment.
Improving the Generalization of Unseen Crowd Behaviors for Reinforcement Learning based Local Motion Planners
Oct 16, 2024



Deploying a safe mobile robot policy in scenarios with human pedestrians is challenging due to their unpredictable movements. Current Reinforcement Learning-based motion planners rely on a single policy to simulate pedestrian movements and could suffer from the over-fitting issue. Alternatively, framing the collision avoidance problem as a multi-agent framework, where agents generate dynamic movements while learning to reach their goals, can lead to conflicts with human pedestrians due to their homogeneity. To tackle this problem, we introduce an efficient method that enhances agent diversity within a single policy by maximizing an information-theoretic objective. This diversity enriches each agent's experiences, improving its adaptability to unseen crowd behaviors. In assessing an agent's robustness against unseen crowds, we propose diverse scenarios inspired by pedestrian crowd behaviors. Our behavior-conditioned policies outperform existing works in these challenging scenes, reducing potential collisions without additional time or travel.