 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-dynamics Conditional Diffusion Planners
Paper and Code
Oct 16, 2024

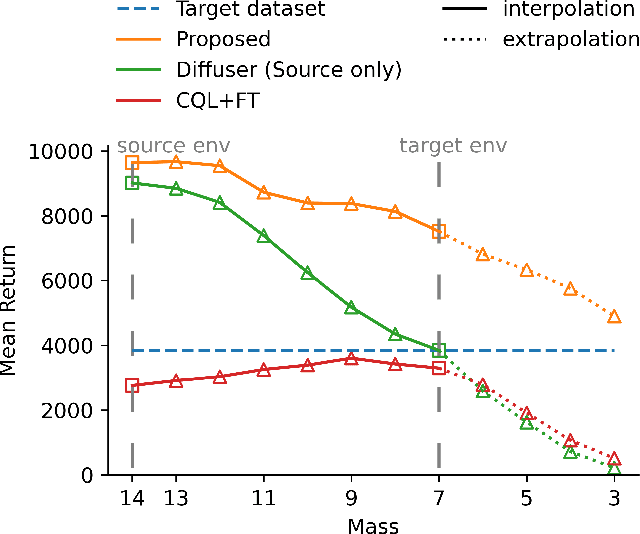
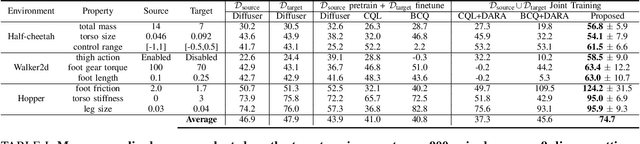
Offline Reinforcement Learning (RL) offers an attractive alternative to interactive data acquisition by leveraging pre-existing datasets. However, its effectiveness hinges on the quantity and quality of the data samples. This work explores the use of more readily available, albeit off-dynamics datasets, to address the challenge of data scarcity in Offline RL. We propose a novel approach using conditional Diffusion Probabilistic Models (DPMs) to learn the joint distribution of the large-scale off-dynamics dataset and the limited target dataset. To enable the model to capture the underlying dynamics structure, we introduce two contexts for the conditional model: (1) a continuous dynamics score allows for partial overlap between trajectories from both datasets, providing the model with richer information; (2) an inverse-dynamics context guides the model to generate trajectories that adhere to the target environment's dynamic constraints. Empirical results demonstrate that our method significantly outperforms several strong baselines. Ablation studies further reveal the critical role of each dynamics context. Additionally, our model demonstrates that by modifying the context, we can interpolate between source and target dynamics, making it more robust to subtle shifts in the environment.