 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-VLA: Spatially-Aware Flow-Matching for Vision-Language-Action Reinforcement Learning
Jan 31, 2026Vision-Language-Action (VLA) models exhibit strong generalization in robotic manipulation, yet reinforcement learning (RL) fine-tuning often degrades robustness under spatial distribution shifts. For flow-matching VLA policies, this degradation is closely associated with the erosion of spatial inductive bias during RL adaptation, as sparse rewards and spatially agnostic exploration increasingly favor short-horizon visual cues. To address this issue, we propose \textbf{SA-VLA}, a spatially-aware RL adaptation framework that preserves spatial grounding during policy optimization by aligning representation learning, reward design, and exploration with task geometry. SA-VLA fuses implicit spatial representations with visual tokens, provides dense rewards that reflect geometric progress, and employs \textbf{SCAN}, a spatially-conditioned annealed exploration strategy tailored to flow-matching dynamics. Across challenging multi-object and cluttered manipulation benchmarks, SA-VLA enables stable RL fine-tuning and improves zero-shot spatial generalization, yielding more robust and transferable behaviors. Code and project page are available at https://xupan.top/Projects/savla.
Time-Annealed Perturbation Sampling: Diverse Generation for Diffusion Language Models
Jan 30, 2026Diffusion language models (Diffusion-LMs) introduce an explicit temporal dimension into text generation, yet how this structure can be leveraged to control generation diversity for exploring multiple valid semantic or reasoning paths remains underexplored. In this paper, we show that Diffusion-LMs, like diffusion models in image generation, exhibit a temporal division of labor: early denoising steps largely determine the global semantic structure, while later steps focus on local lexical refinement. Building on this insight, we propose Time-Annealed Perturbation Sampling (TAPS), a training-free inference strategy that encourages semantic branching early in the diffusion process while progressively reducing perturbations to preserve fluency and instruction adherence. TAPS is compatible with both non-autoregressive and semi-autoregressive Diffusion backbones, demonstrated on LLaDA and TraDo in our paper, and consistently improves output diversity across creative writing and reasoning benchmarks without compromising generation quality.
Reflection-Driven Control for Trustworthy Code Agents
Dec 22, 2025Contemporary large language model (LLM) agents are remarkably capable, but they still lack reliable safety controls and can produce unconstrained, unpredictable, and even actively harmful outputs. To address this, we introduce Reflection-Driven Control, a standardized and pluggable control module that can be seamlessly integrated into general agent architectures. Reflection-Driven Control elevates "self-reflection" from a post hoc patch into an explicit step in the agent's own reasoning process: during generation, the agent continuously runs an internal reflection loop that monitors and evaluates its own decision path. When potential risks are detected, the system retrieves relevant repair examples and secure coding guidelines from an evolving reflective memory, injecting these evidence-based constraints directly into subsequent reasoning steps. We instantiate Reflection-Driven Control in the setting of secure code generation and systematically evaluate it across eight classes of security-critical programming tasks. Empirical results show that Reflection-Driven Control substantially improves the security and policy compliance of generated code while largely preserving functional correctness, with minimal runtime and token overhead. Taken together, these findings indicate that Reflection-Driven Control is a practical path toward trustworthy AI coding agents: it enables designs that are simultaneously autonomous, safer by construction, and auditable.
Self-Adaptive Gamma Context-Aware SSM-based Model for Metal Defect Detection
Mar 06, 2025Metal defect detection is critical in industrial quality assurance, yet existing methods struggle with grayscale variations and complex defect states, limiting its robustness. To address these challenges, this paper proposes a Self-Adaptive Gamma Context-Aware SSM-based model(GCM-DET). This advanced detection framework integrating a Dynamic Gamma Correction (GC) module to enhance grayscale representation and optimize feature extraction for precise defect reconstruction. A State-Space Search Management (SSM) architecture captures robust multi-scale features, effectively handling defects of varying shapes and scales. Focal Loss is employed to mitigate class imbalance and refine detection accuracy. Additionally, the CD5-DET dataset is introduced, specifically designed for port container maintenance, featuring significant grayscale variations and intricate defect patterns. Experimental results demonstrate that the proposed model achieves substantial improvements, with mAP@0.5 gains of 27.6\%, 6.6\%, and 2.6\% on the CD5-DET, NEU-DET, and GC10-DET datasets.
Imitation from Diverse Behaviors: Wasserstein Quality Diversity Imitation Learning with Single-Step Archive Exploration
Nov 11, 2024Learning diverse and high-performance behaviors from a limited set of demonstrations is a grand challenge. Traditional imitation learning methods usually fail in this task because most of them are designed to learn one specific behavior even with multiple demonstrations. Therefore, novel techniques for quality diversity imitation learning are needed to solve the above challenge. This work introduces Wasserstein Quality Diversity Imitation Learning (WQDIL), which 1) improves the stability of imitation learning in the quality diversity setting with latent adversarial training based on a Wasserstein Auto-Encoder (WAE), and 2) mitigates a behavior-overfitting issue using a measure-conditioned reward function with a single-step archive exploration bonus. Empirically, our method significantly outperforms state-of-the-art IL methods, achieving near-expert or beyond-expert QD performance on the challenging continuous control tasks derived from MuJoCo environments.
Quality Diversity Imitation Learning
Oct 08, 2024Imitation learning (IL) has shown great potential in various applications, such as robot control. However, traditional IL methods are usually designed to learn only one specific type of behavior since demonstrations typically correspond to a single expert. In this work, we introduce the first generic framework for Quality Diversity Imitation Learning (QD-IL), which enables the agent to learn a broad range of skills from limited demonstrations. Our framework integrates the principles of quality diversity with adversarial imitation learning (AIL) methods, and can potentially improve any inverse reinforcement learning (IRL) method. Empirically, our framework significantly improves the QD performance of GAIL and VAIL on the challenging continuous control tasks derived from Mujoco environments. Moreover, our method even achieves 2x expert performance in the most challenging Humanoid environment.
Intrinsic Reward Driven Imitation Learning via Generative Model
Jul 09, 2020



Imitation learning in a high-dimensional environment is challenging. Most inverse reinforcement learning (IRL) methods fail to outperform the demonstrator in such a high-dimensional environment, e.g., Atari domain. To address this challenge, we propose a novel reward learning module to generate intrinsic reward signals via a generative model. Our generative method can perform better forward state transition and backward action encoding, which improves the module's dynamics modeling ability in the environment. Thus, our module provides the imitation agent both the intrinsic intention of the demonstrator and a better exploration ability, which is critical for the agent to outperform the demonstrator. Empirical results show that our method outperforms state-of-the-art IRL methods on multiple Atari games, even with one-life demonstration. Remarkably, our method achieves performance that is up to 5 times the performance of the demonstration.
Deep Adversarial Learning in Intrusion Detection: A Data Augmentation Enhanced Framework
Jan 27, 2019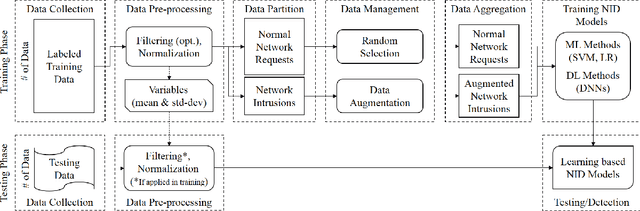

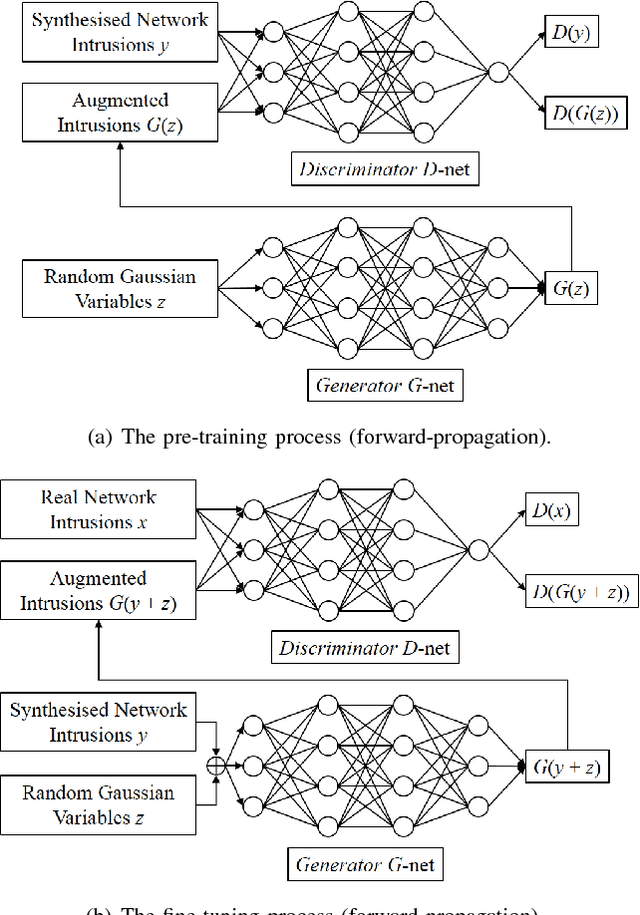

Intrusion detection systems (IDSs) play an important role in identifying malicious attacks and threats in networking systems. As fundamental tools of IDSs, learning based classification methods have been widely employed. When it comes to detecting network intrusions in small sample sizes (e.g., emerging intrusions), the limited number and imbalanced proportion of training samples usually cause significant challenges in training supervised and semi-supervised classifiers. In this paper, we propose a general network intrusion detection framework to address the challenges of both \emph{data scarcity} and \emph{data imbalance}. The novelty of the proposed framework focuses on incorporating deep adversarial learning with statistical learning and exploiting learning based data augmentation. Given a small set of network intrusion samples, it first derives a Poisson-Gamma joint probabilistic generative model to generate synthesised intrusion data using Monte Carlo methods. Those synthesised data are then augmented by deep generative neural networks through adversarial learning. Finally, it adopts the augmented intrusion data to train supervised models for detecting network intrusions. Comprehensive experimental validations on KDD Cup 99 dataset show that the proposed framework outperforms the existing learning based IDSs in terms of improved accuracy, precision, recall, and F1-score.
How does Disagreement Help Generalization against Label Corruption?
Jan 26, 2019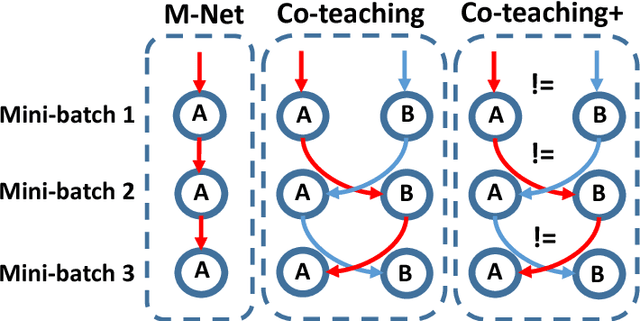
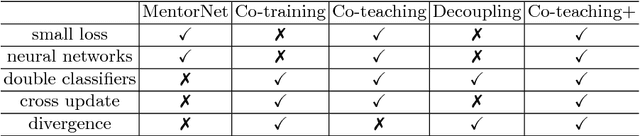


Learning with noisy labels is one of the hottest problems in weakly-supervised learning. Based on memorization effects of deep neural networks, training on small-loss instances becomes very promising for handling noisy labels. This fosters the state-of-the-art approach "Co-teaching" that cross-trains two deep neural networks using the small-loss trick. However, with the increase of epochs, two networks converge to a consensus and Co-teaching reduces to the self-training MentorNet. To tackle this issue, we propose a robust learning paradigm called Co-teaching+, which bridges the "Update by Disagreement" strategy with the original Co-teaching. First, two networks feed forward and predict all data, but keep prediction disagreement data only. Then, among such disagreement data, each network selects its small-loss data, but back propagates the small-loss data from its peer network and updates its own parameters. Empirical results on benchmark datasets demonstrate that Co-teaching+ is much superior to many state-of-the-art methods in the robustness of trained models.
Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels
Oct 30, 2018


Deep learning with noisy labels is practically challenging, as the capacity of deep models is so high that they can totally memorize these noisy labels sooner or later during training. Nonetheless, recent studies on the memorization effects of deep neural networks show that they would first memorize training data of clean labels and then those of noisy labels. Therefore in this paper, we propose a new deep learning paradigm called Co-teaching for combating with noisy labels. Namely, we train two deep neural networks simultaneously, and let them teach each other given every mini-batch: firstly, each network feeds forward all data and selects some data of possibly clean labels; secondly, two networks communicate with each other what data in this mini-batch should be used for training; finally, each network back propagates the data selected by its peer network and updates itself. Empirical results on noisy versions of MNIST, CIFAR-10 and CIFAR-100 demonstrate that Co-teaching is much superior to the state-of-the-art methods in the robustness of trained deep models.