 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Vulnerability Detection: A Counterfactual Explanation
Paper and Code
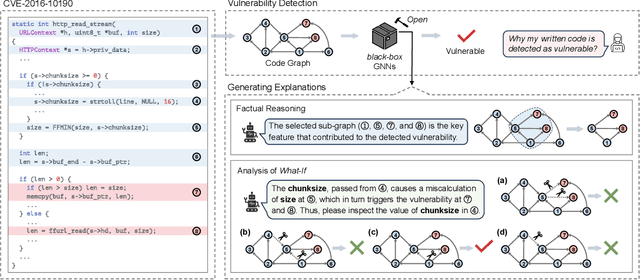
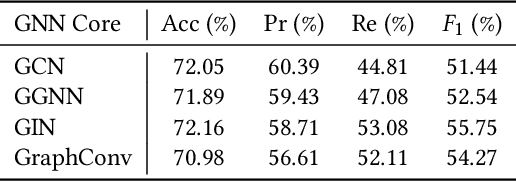
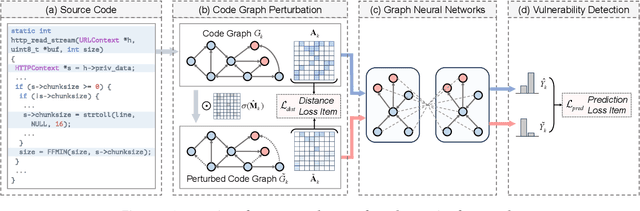
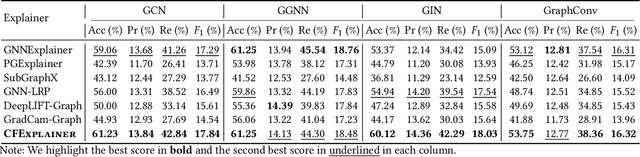
Vulnerability detection is crucial for ensuring the security and reliability of software systems. Recently, Graph Neural Networks (GNNs) have emerged as a prominent code embedding approach for vulnerability detection, owing to their ability to capture the underlying semantic structure of source code. However, GNNs face significant challenges in explainability due to their inherently black-box nature. To this end, several factual reasoning-based explainers have been proposed. These explainers provide explanations for the predictions made by GNNs by analyzing the key features that contribute to the outcomes. We argue that these factual reasoning-based explanations cannot answer critical what-if questions: What would happen to the GNN's decision if we were to alter the code graph into alternative structures? Inspired by advancements of counterfactual reasoning in artificial intelligence, we propose CFExplainer, a novel counterfactual explainer for GNN-based vulnerability detection. Unlike factual reasoning-based explainers, CFExplainer seeks the minimal perturbation to the input code graph that leads to a change in the prediction, thereby addressing the what-if questions for vulnerability detection. We term this perturbation a counterfactual explanation, which can pinpoint the root causes of the detected vulnerability and furnish valuable insights for developers to undertake appropriate actions for fixing the vulnerability. Extensive experiments on four GNN-based vulnerability detection models demonstrate the effectiveness of CFExplainer over existing state-of-the-art factual reasoning-based explainers.