 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
Modeling the Heterogeneous Duration of User Interest in Time-Dependent Recommendation: A Hidden Semi-Markov Approach
Dec 15, 2024



Recommender systems are widely used for suggesting books, education materials, and products to users by exploring their behaviors. In reality, users' preferences often change over time, leading to studies on time-dependent recommender systems. However, most existing approaches that deal with time information remain primitive. In this paper, we extend existing methods and propose a hidden semi-Markov model to track the change of users' interests. Particularly, this model allows for capturing the different durations of user stays in a (latent) interest state, which can better model the heterogeneity of user interests and focuses. We derive an expectation maximization algorithm to estimate the parameters of the framework and predict users' actions. Experiments on three real-world datasets show that our model significantly outperforms the state-of-the-art time-dependent and static benchmark methods. Further analyses of the experiment results indicate that the performance improvement is related to the heterogeneity of state durations and the drift of user interests in the dataset.
ControlRec: Bridging the Semantic Gap between Language Model and Personalized Recommendation
Nov 28, 2023



The successful integration of large language models (LLMs) into recommendation systems has proven to be a major breakthrough in recent studies, paving the way for more generic and transferable recommendations. However, LLMs struggle to effectively utilize user and item IDs, which are crucial identifiers for successful recommendations. This is mainly due to their distinct representation in a semantic space that is different from the natural language (NL) typically used to train LLMs. To tackle such issue, we introduce ControlRec, an innovative Contrastive prompt learning framework for Recommendation systems. ControlRec treats user IDs and NL as heterogeneous features and encodes them individually. To promote greater alignment and integration between them in the semantic space, we have devised two auxiliary contrastive objectives: (1) Heterogeneous Feature Matching (HFM) aligning item description with the corresponding ID or user's next preferred ID based on their interaction sequence, and (2) Instruction Contrastive Learning (ICL) effectively merging these two crucial data sources by contrasting probability distributions of output sequences generated by diverse tasks. Experimental results on four public real-world datasets demonstrate the effectiveness of the proposed method on improving model performance.
Localizing Discriminative Visual Landmarks for Place Recognition
Apr 14, 2019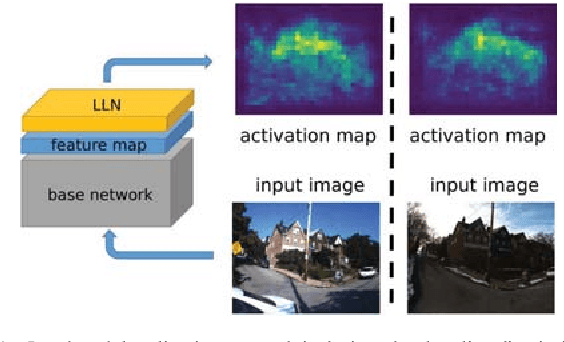
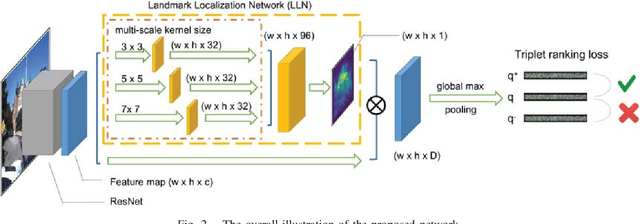
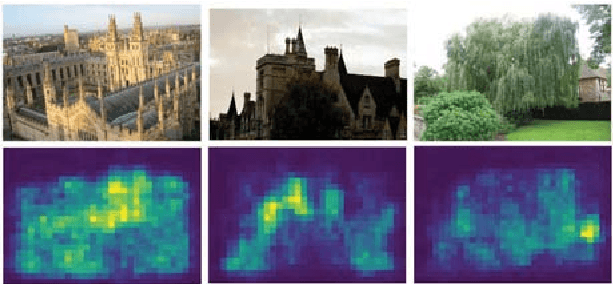
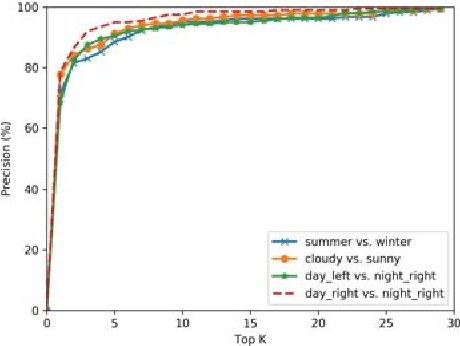
We address the problem of visual place recognition with perceptual changes. The fundamental problem of visual place recognition is generating robust image representations which are not only insensitive to environmental changes but also distinguishable to different places. Taking advantage of the feature extraction ability of Convolutional Neural Networks (CNNs), we further investigate how to localize discriminative visual landmarks that positively contribute to the similarity measurement, such as buildings and vegetations. In particular, a Landmark Localization Network (LLN) is designed to indicate which regions of an image are used for discrimination. Detailed experiments are conducted on open source datasets with varied appearance and viewpoint changes. The proposed approach achieves superior performance against state-of-the-art methods.