 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT: Multi-Vector Search Index Tuning
Apr 28, 2025Vector search plays a crucial role in many real-world applications. In addition to single-vector search, multi-vector search becomes important for multi-modal and multi-feature scenarios today. In a multi-vector database, each row is an item, each column represents a feature of items, and each cell is a high-dimensional vector. In multi-vector databases, the choice of indexes can have a significant impact on performance. Although index tuning for relational databases has been extensively studied, index tuning for multi-vector search remains unclear and challenging. In this paper, we define multi-vector search index tuning and propose a framework to solve it. Specifically, given a multi-vector search workload, we develop algorithms to find indexes that minimize latency and meet storage and recall constraints. Compared to the baseline, our latency achieves 2.1X to 8.3X speedup.
Learning from Uncertain Data: From Possible Worlds to Possible Models
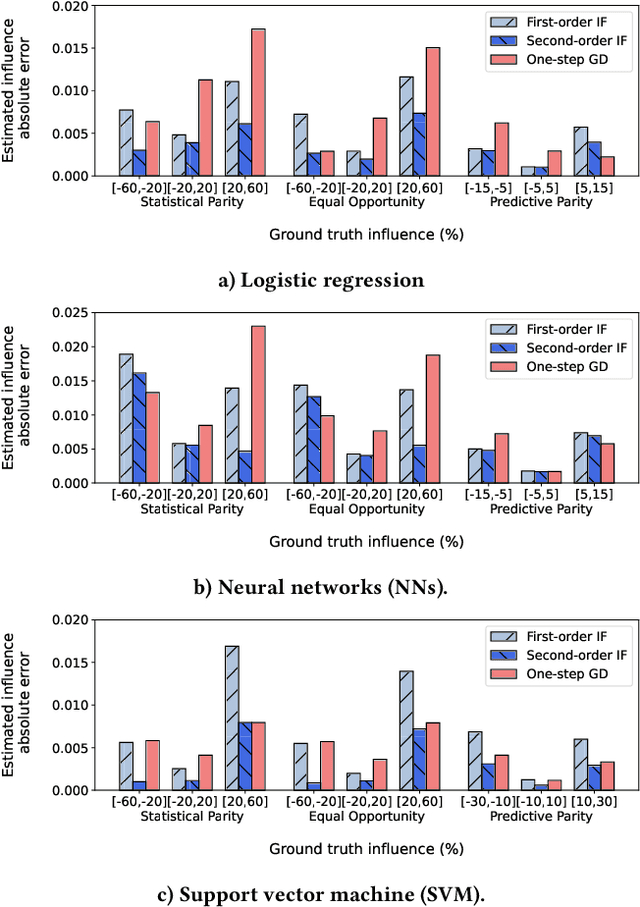
May 28, 2024We introduce an efficient method for learning linear models from uncertain data, where uncertainty is represented as a set of possible variations in the data, leading to predictive multiplicity. Our approach leverages abstract interpretation and zonotopes, a type of convex polytope, to compactly represent these dataset variations, enabling the symbolic execution of gradient descent on all possible worlds simultaneously. We develop techniques to ensure that this process converges to a fixed point and derive closed-form solutions for this fixed point. Our method provides sound over-approximations of all possible optimal models and viable prediction ranges. We demonstrate the effectiveness of our approach through theoretical and empirical analysis, highlighting its potential to reason about model and prediction uncertainty due to data quality issues in training data.
Crab: Learning Certifiably Fair Predictive Models in the Presence of Selection Bias
Dec 21, 2022A recent explosion of research focuses on developing methods and tools for building fair predictive models. However, most of this work relies on the assumption that the training and testing data are representative of the target population on which the model will be deployed. However, real-world training data often suffer from selection bias and are not representative of the target population for many reasons, including the cost and feasibility of collecting and labeling data, historical discrimination, and individual biases. In this paper, we introduce a new framework for certifying and ensuring the fairness of predictive models trained on biased data. We take inspiration from query answering over incomplete and inconsistent databases to present and formalize the problem of consistent range approximation (CRA) of answers to queries about aggregate information for the target population. We aim to leverage background knowledge about the data collection process, biased data, and limited or no auxiliary data sources to compute a range of answers for aggregate queries over the target population that are consistent with available information. We then develop methods that use CRA of such aggregate queries to build predictive models that are certifiably fair on the target population even when no external information about that population is available during training. We evaluate our methods on real data and demonstrate improvements over state of the art. Significantly, we show that enforcing fairness using our methods can lead to predictive models that are not only fair, but more accurate on the target population.
Interpretable Data-Based Explanations for Fairness Debugging
Dec 17, 2021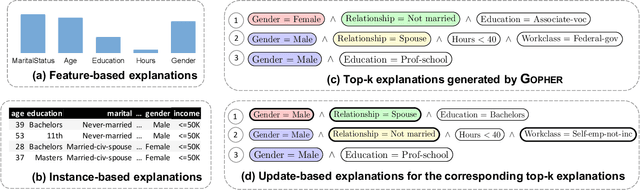
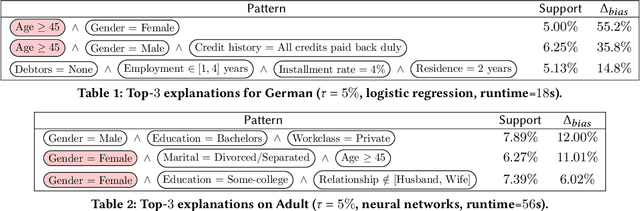
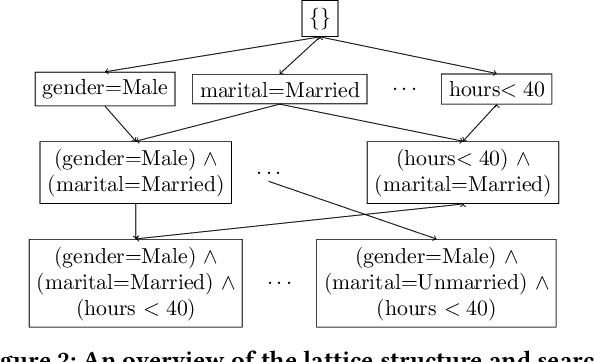
A wide variety of fairness metrics and eXplainable Artificial Intelligence (XAI) approaches have been proposed in the literature to identify bias in machine learning models that are used in critical real-life contexts. However, merely reporting on a model's bias, or generating explanations using existing XAI techniques is insufficient to locate and eventually mitigate sources of bias. In this work, we introduce Gopher, a system that produces compact, interpretable, and causal explanations for bias or unexpected model behavior by identifying coherent subsets of the training data that are root-causes for this behavior. Specifically, we introduce the concept of causal responsibility that quantifies the extent to which intervening on training data by removing or updating subsets of it can resolve the bias. Building on this concept, we develop an efficient approach for generating the top-k patterns that explain model bias that utilizes techniques from the ML community to approximate causal responsibility and uses pruning rules to manage the large search space for patterns. Our experimental evaluation demonstrates the effectiveness of Gopher in generating interpretable explanations for identifying and debugging sources of bias.