 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Data-Based Explanations for Fairness Debugging
Paper and Code
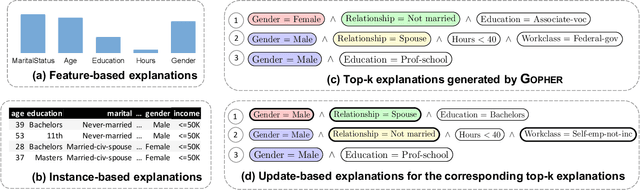
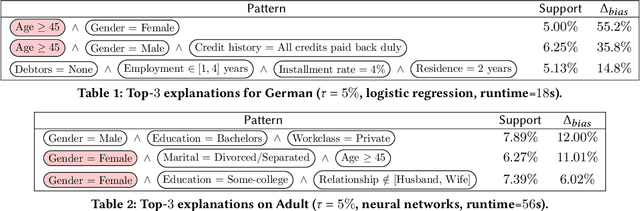
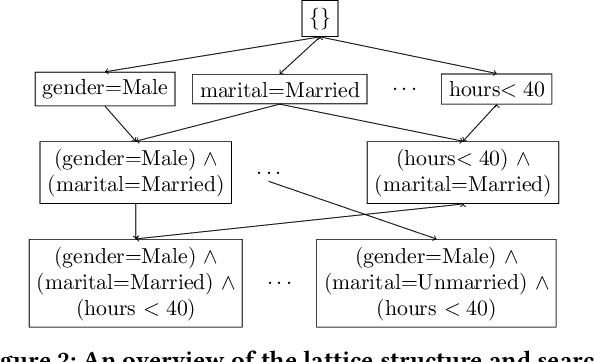
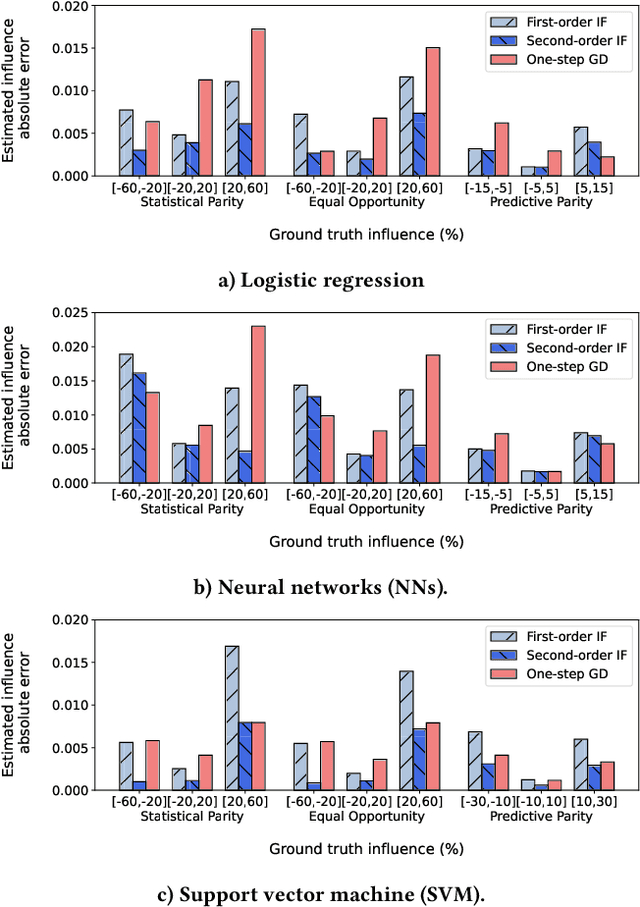
A wide variety of fairness metrics and eXplainable Artificial Intelligence (XAI) approaches have been proposed in the literature to identify bias in machine learning models that are used in critical real-life contexts. However, merely reporting on a model's bias, or generating explanations using existing XAI techniques is insufficient to locate and eventually mitigate sources of bias. In this work, we introduce Gopher, a system that produces compact, interpretable, and causal explanations for bias or unexpected model behavior by identifying coherent subsets of the training data that are root-causes for this behavior. Specifically, we introduce the concept of causal responsibility that quantifies the extent to which intervening on training data by removing or updating subsets of it can resolve the bias. Building on this concept, we develop an efficient approach for generating the top-k patterns that explain model bias that utilizes techniques from the ML community to approximate causal responsibility and uses pruning rules to manage the large search space for patterns. Our experimental evaluation demonstrates the effectiveness of Gopher in generating interpretable explanations for identifying and debugging sources of bias.