 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSourceSplice: Source Selection for Machine Learning Tasks
Jul 29, 2025Data quality plays a pivotal role in the predictive performance of machine learning (ML) tasks - a challenge amplified by the deluge of data sources available in modern organizations.Prior work in data discovery largely focus on metadata matching, semantic similarity or identifying tables that should be joined to answer a particular query, but do not consider source quality for high performance of the downstream ML task.This paper addresses the problem of determining the best subset of data sources that must be combined to construct the underlying training dataset for a given ML task.We propose SourceGrasp and SourceSplice, frameworks designed to efficiently select a suitable subset of sources that maximizes the utility of the downstream ML model.Both the algorithms rely on the core idea that sources (or their combinations) contribute differently to the task utility, and must be judiciously chosen.While SourceGrasp utilizes a metaheuristic based on a greediness criterion and randomization, the SourceSplice framework presents a source selection mechanism inspired from gene splicing - a core concept used in protein synthesis.We empirically evaluate our algorithms on three real-world datasets and synthetic datasets and show that, with significantly fewer subset explorations, SourceSplice effectively identifies subsets of data sources leading to high task utility.We also conduct studies reporting the sensitivity of SourceSplice to the decision choices under several settings.
Data Acquisition for Improving Model Fairness using Reinforcement Learning
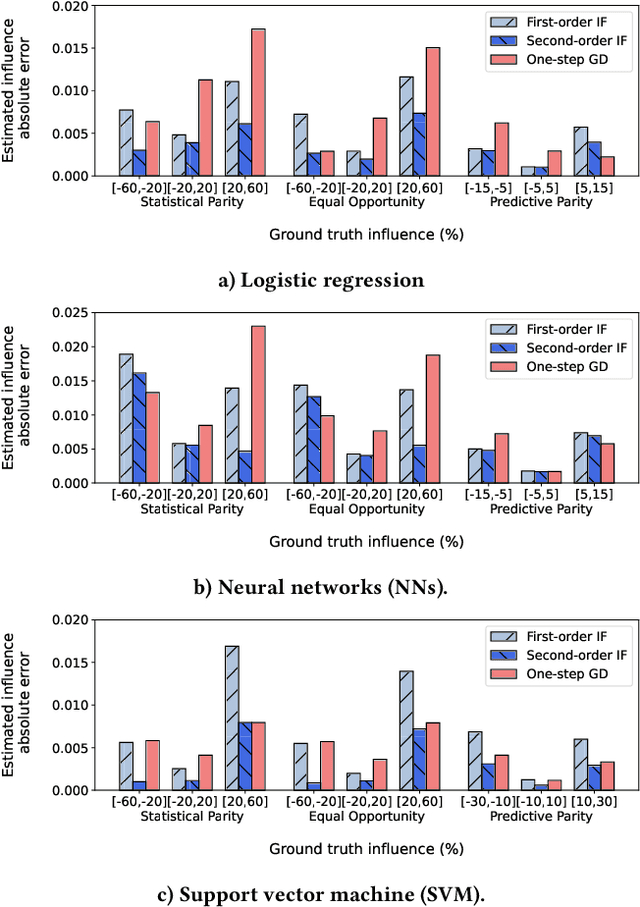
Dec 04, 2024Machine learning systems are increasingly being used in critical decision making such as healthcare, finance, and criminal justice. Concerns around their fairness have resulted in several bias mitigation techniques that emphasize the need for high-quality data to ensure fairer decisions. However, the role of earlier stages of machine learning pipelines in mitigating model bias has not been explored well. In this paper, we focus on the task of acquiring additional labeled data points for training the downstream machine learning model to rapidly improve its fairness. Since not all data points in a data pool are equally beneficial to the task of fairness, we generate an ordering in which data points should be acquired. We present DataSift, a data acquisition framework based on the idea of data valuation that relies on partitioning and multi-armed bandits to determine the most valuable data points to acquire. Over several iterations, DataSift selects a partition and randomly samples a batch of data points from the selected partition, evaluates the benefit of acquiring the batch on model fairness, and updates the utility of partitions depending on the benefit. To further improve the effectiveness and efficiency of evaluating batches, we leverage influence functions that estimate the effect of acquiring a batch without retraining the model. We empirically evaluate DataSift on several real-world and synthetic datasets and show that the fairness of a machine learning model can be significantly improved even while acquiring a few data points.
Example-based Explanations for Random Forests using Machine Unlearning
Feb 07, 2024Tree-based machine learning models, such as decision trees and random forests, have been hugely successful in classification tasks primarily because of their predictive power in supervised learning tasks and ease of interpretation. Despite their popularity and power, these models have been found to produce unexpected or discriminatory outcomes. Given their overwhelming success for most tasks, it is of interest to identify sources of their unexpected and discriminatory behavior. However, there has not been much work on understanding and debugging tree-based classifiers in the context of fairness. We introduce FairDebugger, a system that utilizes recent advances in machine unlearning research to identify training data subsets responsible for instances of fairness violations in the outcomes of a random forest classifier. FairDebugger generates top-$k$ explanations (in the form of coherent training data subsets) for model unfairness. Toward this goal, FairDebugger first utilizes machine unlearning to estimate the change in the tree structures of the random forest when parts of the underlying training data are removed, and then leverages the Apriori algorithm from frequent itemset mining to reduce the subset search space. We empirically evaluate our approach on three real-world datasets, and demonstrate that the explanations generated by FairDebugger are consistent with insights from prior studies on these datasets.
Interpretable Data-Based Explanations for Fairness Debugging
Dec 17, 2021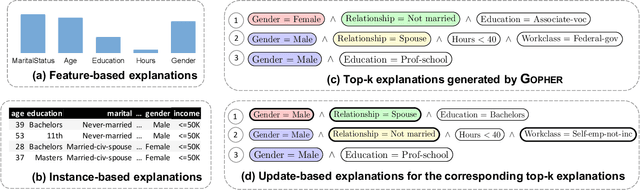
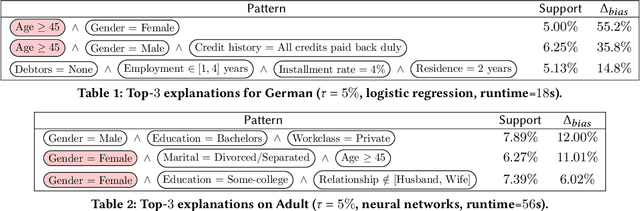
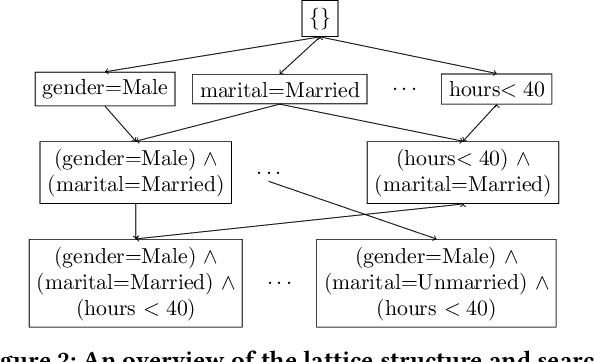
A wide variety of fairness metrics and eXplainable Artificial Intelligence (XAI) approaches have been proposed in the literature to identify bias in machine learning models that are used in critical real-life contexts. However, merely reporting on a model's bias, or generating explanations using existing XAI techniques is insufficient to locate and eventually mitigate sources of bias. In this work, we introduce Gopher, a system that produces compact, interpretable, and causal explanations for bias or unexpected model behavior by identifying coherent subsets of the training data that are root-causes for this behavior. Specifically, we introduce the concept of causal responsibility that quantifies the extent to which intervening on training data by removing or updating subsets of it can resolve the bias. Building on this concept, we develop an efficient approach for generating the top-k patterns that explain model bias that utilizes techniques from the ML community to approximate causal responsibility and uses pruning rules to manage the large search space for patterns. Our experimental evaluation demonstrates the effectiveness of Gopher in generating interpretable explanations for identifying and debugging sources of bias.
Explaining Black-Box Algorithms Using Probabilistic Contrastive Counterfactuals
Mar 22, 2021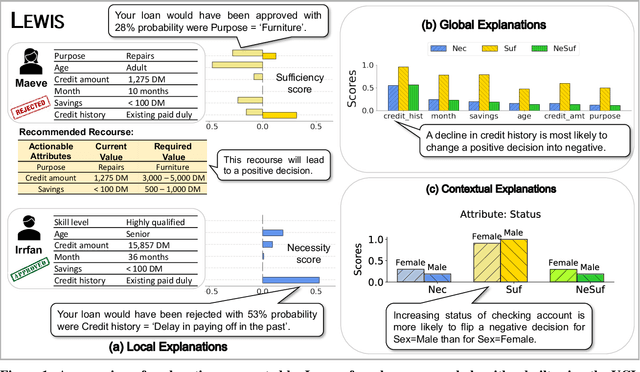

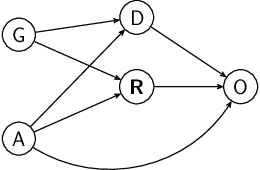
There has been a recent resurgence of interest in explainable artificial intelligence (XAI) that aims to reduce the opaqueness of AI-based decision-making systems, allowing humans to scrutinize and trust them. Prior work in this context has focused on the attribution of responsibility for an algorithm's decisions to its inputs wherein responsibility is typically approached as a purely associational concept. In this paper, we propose a principled causality-based approach for explaining black-box decision-making systems that addresses limitations of existing methods in XAI. At the core of our framework lies probabilistic contrastive counterfactuals, a concept that can be traced back to philosophical, cognitive, and social foundations of theories on how humans generate and select explanations. We show how such counterfactuals can quantify the direct and indirect influences of a variable on decisions made by an algorithm, and provide actionable recourse for individuals negatively affected by the algorithm's decision. Unlike prior work, our system, LEWIS: (1)can compute provably effective explanations and recourse at local, global and contextual levels (2)is designed to work with users with varying levels of background knowledge of the underlying causal model and (3)makes no assumptions about the internals of an algorithmic system except for the availability of its input-output data. We empirically evaluate LEWIS on three real-world datasets and show that it generates human-understandable explanations that improve upon state-of-the-art approaches in XAI, including the popular LIME and SHAP. Experiments on synthetic data further demonstrate the correctness of LEWIS's explanations and the scalability of its recourse algorithm.