 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Labeling Functions with Limited Labeled Data
May 29, 2025Programmatic weak supervision (PWS) significantly reduces human effort for labeling data by combining the outputs of user-provided labeling functions (LFs) on unlabeled datapoints. However, the quality of the generated labels depends directly on the accuracy of the LFs. In this work, we study the problem of fixing LFs based on a small set of labeled examples. Towards this goal, we develop novel techniques for repairing a set of LFs by minimally changing their results on the labeled examples such that the fixed LFs ensure that (i) there is sufficient evidence for the correct label of each labeled datapoint and (ii) the accuracy of each repaired LF is sufficiently high. We model LFs as conditional rules which enables us to refine them, i.e., to selectively change their output for some inputs. We demonstrate experimentally that our system improves the quality of LFs based on surprisingly small sets of labeled datapoints.
Learning from Uncertain Data: From Possible Worlds to Possible Models
May 28, 2024We introduce an efficient method for learning linear models from uncertain data, where uncertainty is represented as a set of possible variations in the data, leading to predictive multiplicity. Our approach leverages abstract interpretation and zonotopes, a type of convex polytope, to compactly represent these dataset variations, enabling the symbolic execution of gradient descent on all possible worlds simultaneously. We develop techniques to ensure that this process converges to a fixed point and derive closed-form solutions for this fixed point. Our method provides sound over-approximations of all possible optimal models and viable prediction ranges. We demonstrate the effectiveness of our approach through theoretical and empirical analysis, highlighting its potential to reason about model and prediction uncertainty due to data quality issues in training data.
Interpretable Data-Based Explanations for Fairness Debugging
Dec 17, 2021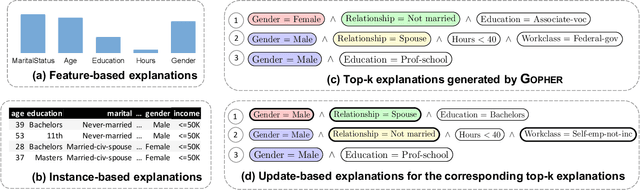
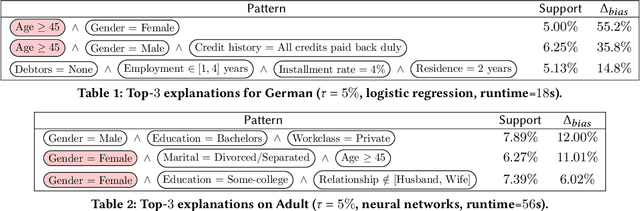
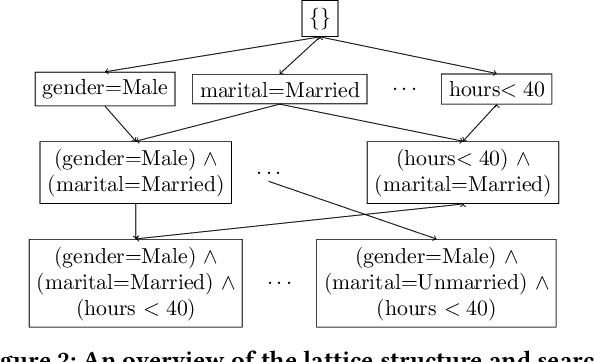
A wide variety of fairness metrics and eXplainable Artificial Intelligence (XAI) approaches have been proposed in the literature to identify bias in machine learning models that are used in critical real-life contexts. However, merely reporting on a model's bias, or generating explanations using existing XAI techniques is insufficient to locate and eventually mitigate sources of bias. In this work, we introduce Gopher, a system that produces compact, interpretable, and causal explanations for bias or unexpected model behavior by identifying coherent subsets of the training data that are root-causes for this behavior. Specifically, we introduce the concept of causal responsibility that quantifies the extent to which intervening on training data by removing or updating subsets of it can resolve the bias. Building on this concept, we develop an efficient approach for generating the top-k patterns that explain model bias that utilizes techniques from the ML community to approximate causal responsibility and uses pruning rules to manage the large search space for patterns. Our experimental evaluation demonstrates the effectiveness of Gopher in generating interpretable explanations for identifying and debugging sources of bias.