 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Uncertain Data: From Possible Worlds to Possible Models
May 28, 2024We introduce an efficient method for learning linear models from uncertain data, where uncertainty is represented as a set of possible variations in the data, leading to predictive multiplicity. Our approach leverages abstract interpretation and zonotopes, a type of convex polytope, to compactly represent these dataset variations, enabling the symbolic execution of gradient descent on all possible worlds simultaneously. We develop techniques to ensure that this process converges to a fixed point and derive closed-form solutions for this fixed point. Our method provides sound over-approximations of all possible optimal models and viable prediction ranges. We demonstrate the effectiveness of our approach through theoretical and empirical analysis, highlighting its potential to reason about model and prediction uncertainty due to data quality issues in training data.
Learning content and context with language bias for Visual Question Answering
Dec 21, 2020
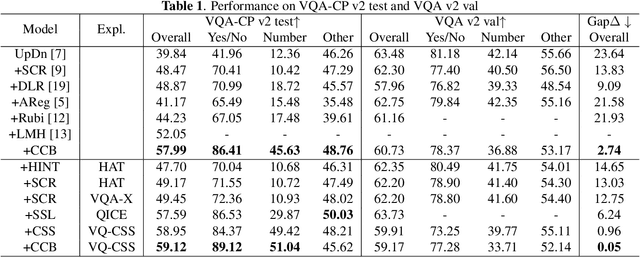
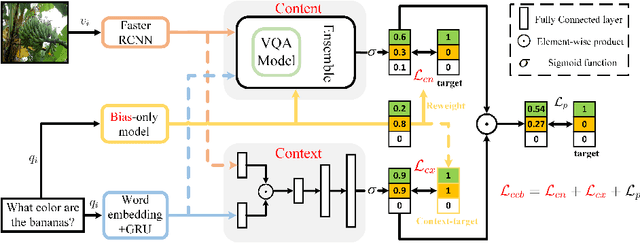

Visual Question Answering (VQA) is a challenging multimodal task to answer questions about an image. Many works concentrate on how to reduce language bias which makes models answer questions ignoring visual content and language context. However, reducing language bias also weakens the ability of VQA models to learn context prior. To address this issue, we propose a novel learning strategy named CCB, which forces VQA models to answer questions relying on Content and Context with language Bias. Specifically, CCB establishes Content and Context branches on top of a base VQA model and forces them to focus on local key content and global effective context respectively. Moreover, a joint loss function is proposed to reduce the importance of biased samples and retain their beneficial influence on answering questions. Experiments show that CCB outperforms the state-of-the-art methods in terms of accuracy on VQA-CP v2.
PPGN: Phrase-Guided Proposal Generation Network For Referring Expression Comprehension
Dec 20, 2020
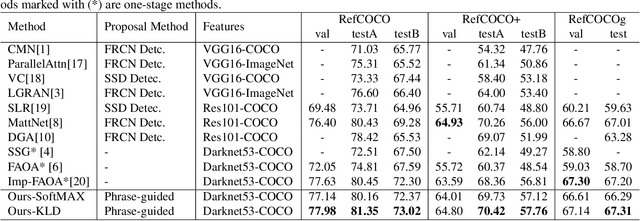
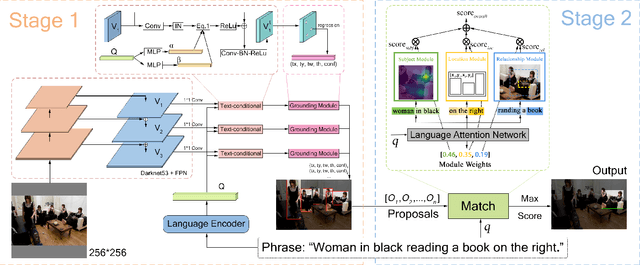
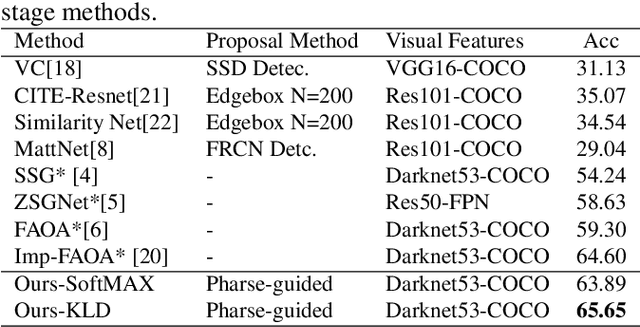
Reference expression comprehension (REC) aims to find the location that the phrase refer to in a given image. Proposal generation and proposal representation are two effective techniques in many two-stage REC methods. However, most of the existing works only focus on proposal representation and neglect the importance of proposal generation. As a result, the low-quality proposals generated by these methods become the performance bottleneck in REC tasks. In this paper, we reconsider the problem of proposal generation, and propose a novel phrase-guided proposal generation network (PPGN). The main implementation principle of PPGN is refining visual features with text and generate proposals through regression. Experiments show that our method is effective and achieve SOTA performance in benchmark datasets.