 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Acquisition for Improving Model Fairness using Reinforcement Learning
Dec 04, 2024Machine learning systems are increasingly being used in critical decision making such as healthcare, finance, and criminal justice. Concerns around their fairness have resulted in several bias mitigation techniques that emphasize the need for high-quality data to ensure fairer decisions. However, the role of earlier stages of machine learning pipelines in mitigating model bias has not been explored well. In this paper, we focus on the task of acquiring additional labeled data points for training the downstream machine learning model to rapidly improve its fairness. Since not all data points in a data pool are equally beneficial to the task of fairness, we generate an ordering in which data points should be acquired. We present DataSift, a data acquisition framework based on the idea of data valuation that relies on partitioning and multi-armed bandits to determine the most valuable data points to acquire. Over several iterations, DataSift selects a partition and randomly samples a batch of data points from the selected partition, evaluates the benefit of acquiring the batch on model fairness, and updates the utility of partitions depending on the benefit. To further improve the effectiveness and efficiency of evaluating batches, we leverage influence functions that estimate the effect of acquiring a batch without retraining the model. We empirically evaluate DataSift on several real-world and synthetic datasets and show that the fairness of a machine learning model can be significantly improved even while acquiring a few data points.
Optimizing Large Language Models through Quantization: A Comparative Analysis of PTQ and QAT Techniques
Nov 09, 2024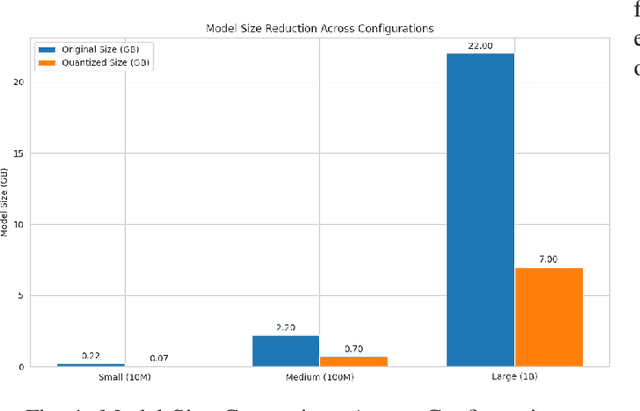



This paper presents a comprehensive analysis of quantization techniques for optimizing Large Language Models (LLMs), specifically focusing on Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT). Through empirical evaluation across models ranging from 10M to 1B parameters, we demonstrate that quantization can achieve up to 68% reduction in model size while maintaining performance within 6% of full-precision baselines when utilizing our proposed scaling factor {\gamma}. Our experiments show that INT8 quantization delivers a 40% reduction in computational cost and power consumption, while INT4 quantization further improves these metrics by 60%. We introduce a novel theoretical framework for mixed-precision quantization, deriving optimal bit allocation strategies based on layer sensitivity and weight variance. Hardware efficiency evaluations on edge devices reveal that our quantization approach enables up to 2.4x throughput improvement for INT8 and 3x for INT4, with 60% power reduction compared to full-precision models.
Security and Privacy Issues of Federated Learning
Jul 22, 2023Federated Learning (FL) has emerged as a promising approach to address data privacy and confidentiality concerns by allowing multiple participants to construct a shared model without centralizing sensitive data. However, this decentralized paradigm introduces new security challenges, necessitating a comprehensive identification and classification of potential risks to ensure FL's security guarantees. This paper presents a comprehensive taxonomy of security and privacy challenges in Federated Learning (FL) across various machine learning models, including large language models. We specifically categorize attacks performed by the aggregator and participants, focusing on poisoning attacks, backdoor attacks, membership inference attacks, generative adversarial network (GAN) based attacks, and differential privacy attacks. Additionally, we propose new directions for future research, seeking innovative solutions to fortify FL systems against emerging security risks and uphold sensitive data confidentiality in distributed learning environments.