 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPipeline: Synthesize Data Pipelines By-Target Using Reinforcement Learning and Search
Paper and Code


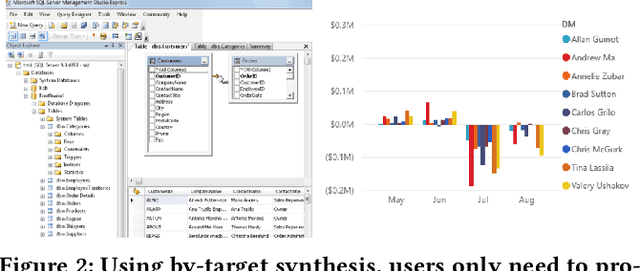

Recent work has made significant progress in helping users to automate single data preparation steps, such as string-transformations and table-manipulation operators (e.g., Join, GroupBy, Pivot, etc.). We in this work propose to automate multiple such steps end-to-end, by synthesizing complex data pipelines with both string transformations and table-manipulation operators. We propose a novel "by-target" paradigm that allows users to easily specify the desired pipeline, which is a significant departure from the traditional by-example paradigm. Using by-target, users would provide input tables (e.g., csv or json files), and point us to a "target table" (e.g., an existing database table or BI dashboard) to demonstrate how the output from the desired pipeline would schematically "look like". While the problem is seemingly underspecified, our unique insight is that implicit table constraints such as FDs and keys can be exploited to significantly constrain the space to make the problem tractable. We develop an Auto-Pipeline system that learns to synthesize pipelines using reinforcement learning and search. Experiments on large numbers of real pipelines crawled from GitHub suggest that Auto-Pipeline can successfully synthesize 60-70% of these complex pipelines (up to 10 steps) in 10-20 seconds on average.