 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioural vs. Representational Systematicity in End-to-End Models: An Opinionated Survey
Jun 04, 2025A core aspect of compositionality, systematicity is a desirable property in ML models as it enables strong generalization to novel contexts. This has led to numerous studies proposing benchmarks to assess systematic generalization, as well as models and training regimes designed to enhance it. Many of these efforts are framed as addressing the challenge posed by Fodor and Pylyshyn. However, while they argue for systematicity of representations, existing benchmarks and models primarily focus on the systematicity of behaviour. We emphasize the crucial nature of this distinction. Furthermore, building on Hadley's (1994) taxonomy of systematic generalization, we analyze the extent to which behavioural systematicity is tested by key benchmarks in the literature across language and vision. Finally, we highlight ways of assessing systematicity of representations in ML models as practiced in the field of mechanistic interpretability.
Learning Relational Rules from Rewards
Mar 28, 2022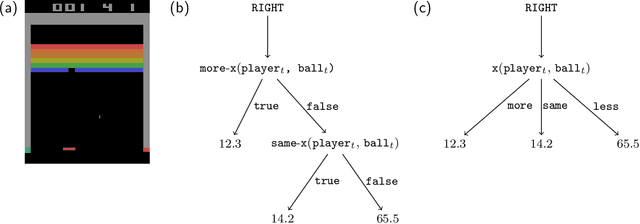

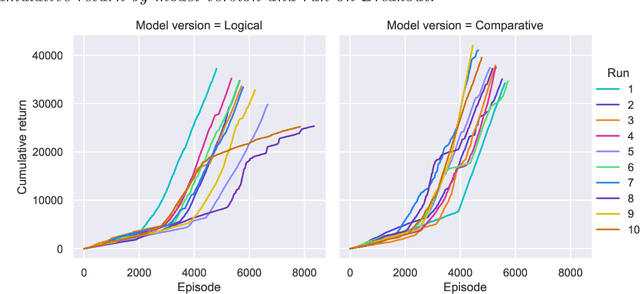
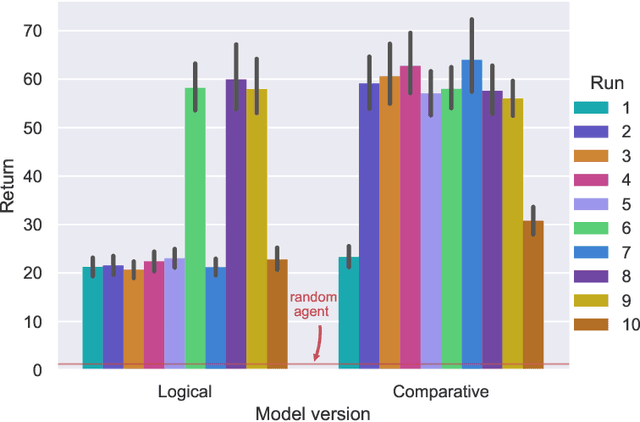
Humans perceive the world in terms of objects and relations between them. In fact, for any given pair of objects, there is a myriad of relations that apply to them. How does the cognitive system learn which relations are useful to characterize the task at hand? And how can it use these representations to build a relational policy to interact effectively with the environment? In this paper we proposed that this problem can be understood through the lens of a sub-field of symbolic machine learning called relational reinforcement learning (RRL). To demonstrate the potential of our approach, we build a simple model of relational policy learning based on a function approximator developed in RRL. We trained and tested our model in three Atari games that required to consider an increasingly number of potential relations: Breakout, Pong and Demon Attack. In each game, our model was able to select adequate relational representations and build a relational policy incrementally. We discuss the relationship between our model with models of relational and analogical reasoning, as well as its limitations and future directions of research.
Relation learning in a neurocomputational architecture supports cross-domain transfer
Oct 11, 2019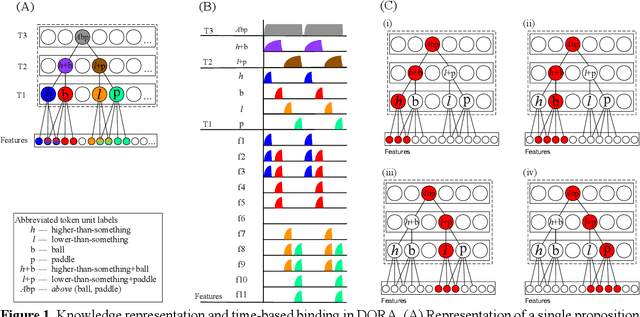


People readily generalise prior knowledge to novel situations and stimuli. Advances in machine learning and artificial intelligence have begun to approximate and even surpass human performance in specific domains, but machine learning systems struggle to generalise information to untrained situations. We present and model that demonstrates human-like extrapolatory generalisation by learning and explicitly representing an open-ended set of relations characterising regularities within the domains it is exposed to. First, when trained to play one video game (e.g., Breakout). the model generalises to a new game (e.g., Pong) with different rules, dimensions, and characteristics in a single shot. Second, the model can learn representations from a different domain (e.g., 3D shape images) that support learning a video game and generalising to a new game in one shot. By exploiting well-established principles from cognitive psychology and neuroscience, the model learns structured representations without feedback, and without requiring knowledge of the relevant relations to be given a priori. We present additional simulations showing that the representations that the model learns support cross-domain generalisation. The model's ability to generalise between different games demonstrates the flexible generalisation afforded by a capacity to learn not only statistical relations, but also other relations that are useful for characterising the domain to be learned. In turn, this kind of flexible, relational generalisation is only possible because the model is capable of representing relations explicitly, a capacity that is notably absent in extant statistical machine learning algorithms.
The relational processing limits of classic and contemporary neural network models of language processing
May 12, 2019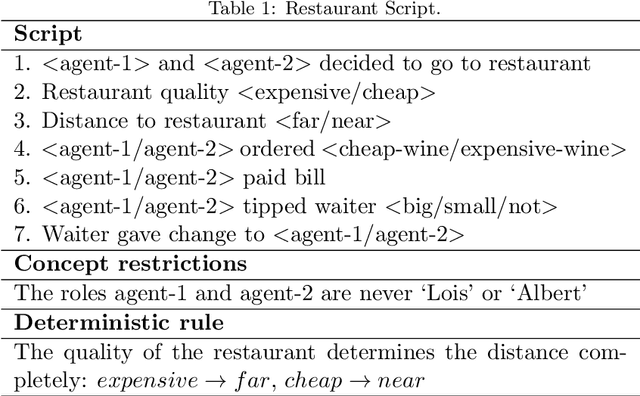
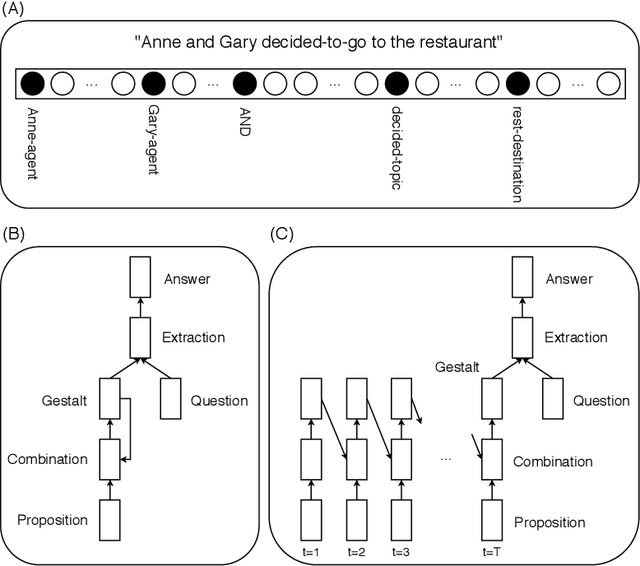
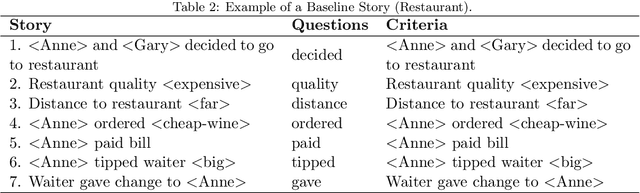
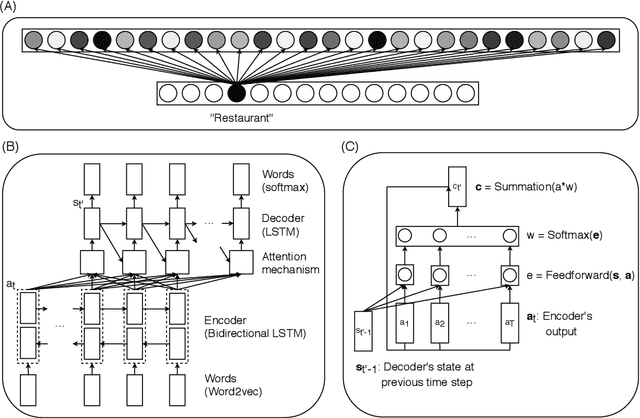
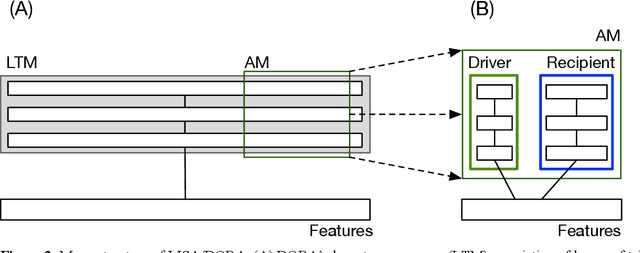
The ability of neural networks to capture relational knowledge is a matter of long-standing controversy. Recently, some researchers in the PDP side of the debate have argued that (1) classic PDP models can handle relational structure (Rogers & McClelland, 2008, 2014) and (2) the success of deep learning approaches to text processing suggests that structured representations are unnecessary to capture the gist of human language (Rabovsky et al., 2018). In the present study we tested the Story Gestalt model (St. John, 1992), a classic PDP model of text comprehension, and a Sequence-to-Sequence with Attention model (Bahdanau et al., 2015), a contemporary deep learning architecture for text processing. Both models were trained to answer questions about stories based on the thematic roles that several concepts played on the stories. In three critical test we varied the statistical structure of new stories while keeping their relational structure constant with respect to the training data. Each model was susceptible to each statistical structure manipulation to a different degree, with their performance failing below chance at least under one manipulation. We argue that the failures of both models are due to the fact that they cannotperform dynamic binding of independent roles and fillers. Ultimately, these results cast doubts onthe suitability of traditional neural networks models for explaining phenomena based on relational reasoning, including language processing.
Predicate learning in neural systems: Discovering latent generative structures
Oct 02, 2018Humans learn complex latent structures from their environments (e.g., natural language, mathematics, music, social hierarchies). In cognitive science and cognitive neuroscience, models that infer higher-order structures from sensory or first-order representations have been proposed to account for the complexity and flexibility of human behavior. But how do the structures that these models invoke arise in neural systems in the first place? To answer this question, we explain how a system can learn latent representational structures (i.e., predicates) from experience with wholly unstructured data. During the process of predicate learning, an artificial neural network exploits the naturally occurring dynamic properties of distributed computing across neuronal assemblies in order to learn predicates, but also to combine them compositionally, two computational aspects which appear to be necessary for human behavior as per formal theories in multiple domains. We describe how predicates can be combined generatively using neural oscillations to achieve human-like extrapolation and compositionality in an artificial neural network. The ability to learn predicates from experience, to represent structures compositionally, and to extrapolate to unseen data offers an inroads to understanding and modeling the most complex human behaviors.
Human-like generalization in a machine through predicate learning
Jun 06, 2018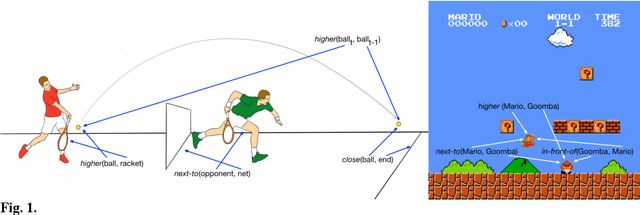
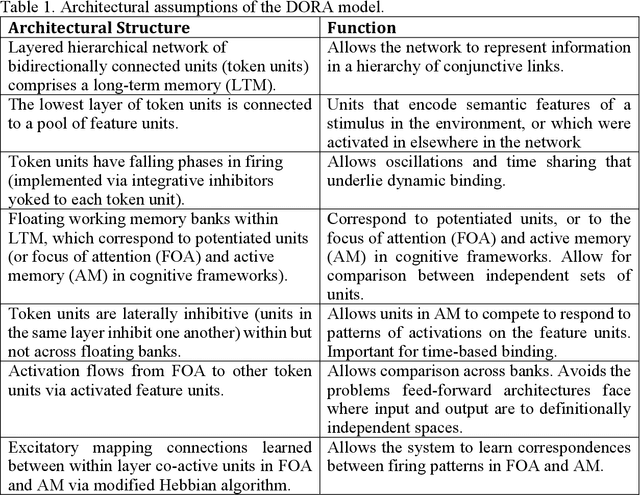
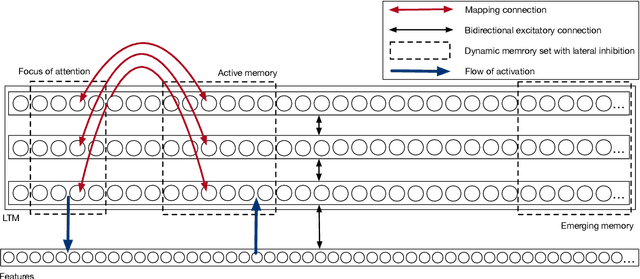

Humans readily generalize, applying prior knowledge to novel situations and stimuli. Advances in machine learning and artificial intelligence have begun to approximate and even surpass human performance, but machine systems reliably struggle to generalize information to untrained situations. We describe a neural network model that is trained to play one video game (Breakout) and demonstrates one-shot generalization to a new game (Pong). The model generalizes by learning representations that are functionally and formally symbolic from training data, without feedback, and without requiring that structured representations be specified a priori. The model uses unsupervised comparison to discover which characteristics of the input are invariant, and to learn relational predicates; it then applies these predicates to arguments in a symbolic fashion, using oscillatory regularities in network firing to dynamically bind predicates to arguments. We argue that models of human cognition must account for far- reaching and flexible generalization, and that in order to do so, models must be able to discover symbolic representations from unstructured data, a process we call predicate learning. Only then can models begin to adequately explain where human-like representations come from, why human cognition is the way it is, and why it continues to differ from machine intelligence in crucial ways.