 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Reasoning in Object-Centric Deep Neural Networks: A Comparative Cognition Approach
Paper and Code
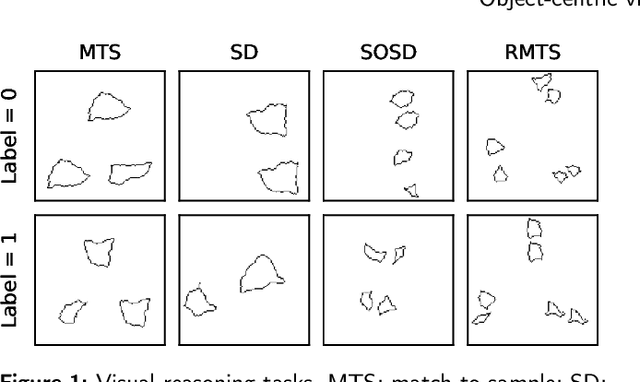

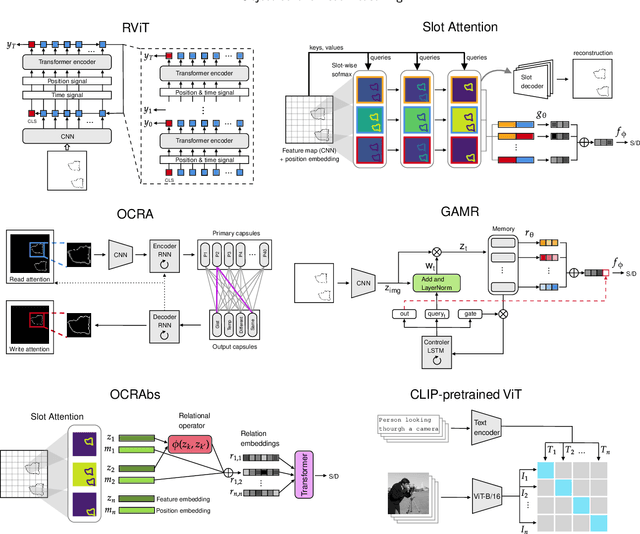
Achieving visual reasoning is a long-term goal of artificial intelligence. In the last decade, several studies have applied deep neural networks (DNNs) to the task of learning visual relations from images, with modest results in terms of generalization of the relations learned. However, in recent years, object-centric representation learning has been put forward as a way to achieve visual reasoning within the deep learning framework. Object-centric models attempt to model input scenes as compositions of objects and relations between them. To this end, these models use several kinds of attention mechanisms to segregate the individual objects in a scene from the background and from other objects. In this work we tested relation learning and generalization in several object-centric models, as well as a ResNet-50 baseline. In contrast to previous research, which has focused heavily in the same-different task in order to asses relational reasoning in DNNs, we use a set of tasks -- with varying degrees of difficulty -- derived from the comparative cognition literature. Our results show that object-centric models are able to segregate the different objects in a scene, even in many out-of-distribution cases. In our simpler tasks, this improves their capacity to learn and generalize visual relations in comparison to the ResNet-50 baseline. However, object-centric models still struggle in our more difficult tasks and conditions. We conclude that abstract visual reasoning remains an open challenge for DNNs, including object-centric models.