 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Literature Review of Retrieval-Augmented Generation: Techniques, Metrics, and Challenges
Aug 08, 2025This systematic review of the research literature on retrieval-augmented generation (RAG) provides a focused analysis of the most highly cited studies published between 2020 and May 2025. A total of 128 articles met our inclusion criteria. The records were retrieved from ACM Digital Library, IEEE Xplore, Scopus, ScienceDirect, and the Digital Bibliography and Library Project (DBLP). RAG couples a neural retriever with a generative language model, grounding output in up-to-date, non-parametric memory while retaining the semantic generalisation stored in model weights. Guided by the PRISMA 2020 framework, we (i) specify explicit inclusion and exclusion criteria based on citation count and research questions, (ii) catalogue datasets, architectures, and evaluation practices, and (iii) synthesise empirical evidence on the effectiveness and limitations of RAG. To mitigate citation-lag bias, we applied a lower citation-count threshold to papers published in 2025 so that emerging breakthroughs with naturally fewer citations were still captured. This review clarifies the current research landscape, highlights methodological gaps, and charts priority directions for future research.
SynFinTabs: A Dataset of Synthetic Financial Tables for Information and Table Extraction
Dec 05, 2024Table extraction from document images is a challenging AI problem, and labelled data for many content domains is difficult to come by. Existing table extraction datasets often focus on scientific tables due to the vast amount of academic articles that are readily available, along with their source code. However, there are significant layout and typographical differences between tables found across scientific, financial, and other domains. Current datasets often lack the words, and their positions, contained within the tables, instead relying on unreliable OCR to extract these features for training modern machine learning models on natural language processing tasks. Therefore, there is a need for a more general method of obtaining labelled data. We present SynFinTabs, a large-scale, labelled dataset of synthetic financial tables. Our hope is that our method of generating these synthetic tables is transferable to other domains. To demonstrate the effectiveness of our dataset in training models to extract information from table images, we create FinTabQA, a layout large language model trained on an extractive question-answering task. We test our model using real-world financial tables and compare it to a state-of-the-art generative model and discuss the results. We make the dataset, model, and dataset generation code publicly available.
QUB-Cirdan at "Discharge Me!": Zero shot discharge letter generation by open-source LLM
May 27, 2024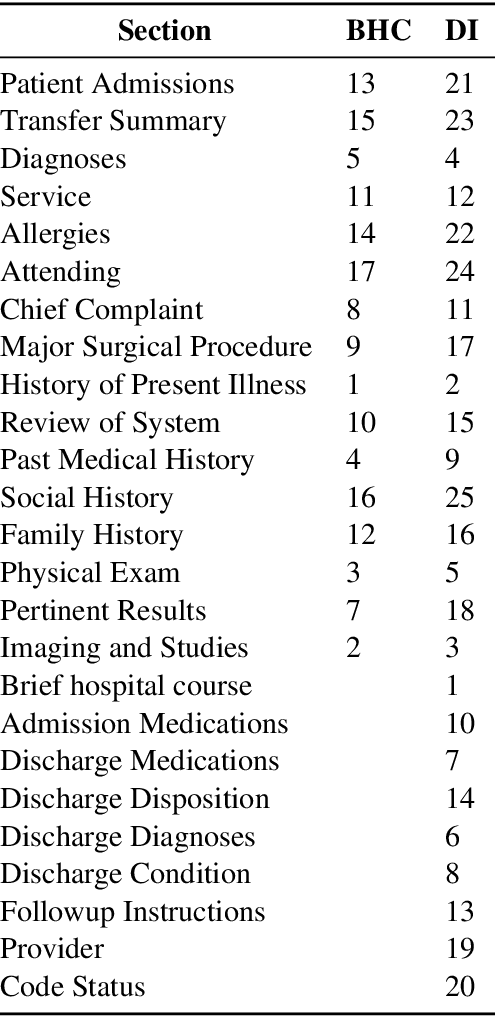
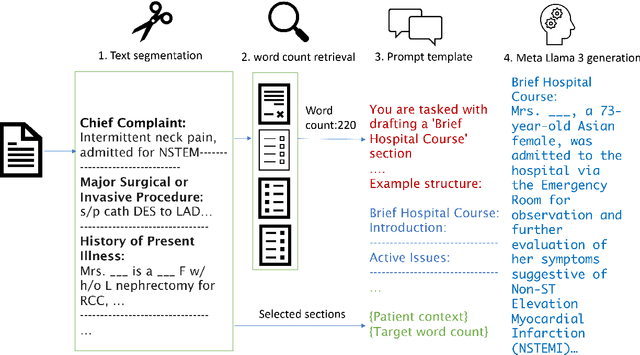
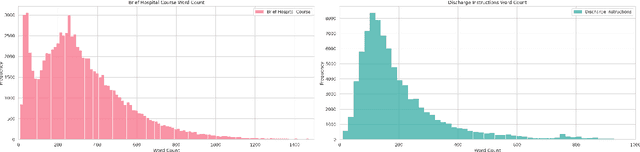

The BioNLP ACL'24 Shared Task on Streamlining Discharge Documentation aims to reduce the administrative burden on clinicians by automating the creation of critical sections of patient discharge letters. This paper presents our approach using the Llama3 8B quantized model to generate the "Brief Hospital Course" and "Discharge Instructions" sections. We employ a zero-shot method combined with Retrieval-Augmented Generation (RAG) to produce concise, contextually accurate summaries. Our contributions include the development of a curated template-based approach to ensure reliability and consistency, as well as the integration of RAG for word count prediction. We also describe several unsuccessful experiments to provide insights into our pathway for the competition. Our results demonstrate the effectiveness and efficiency of our approach, achieving high scores across multiple evaluation metrics.
Feature2Vec: Distributional semantic modelling of human property knowledge
Aug 29, 2019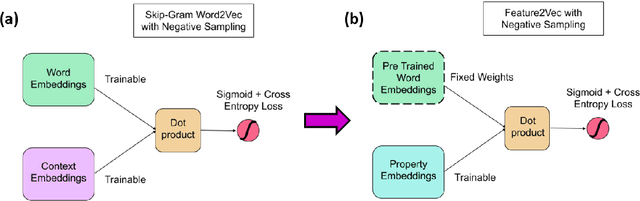
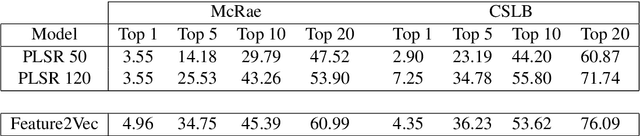
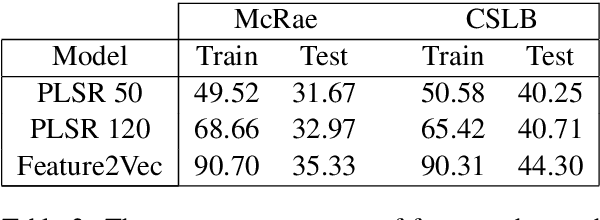

Feature norm datasets of human conceptual knowledge, collected in surveys of human volunteers, yield highly interpretable models of word meaning and play an important role in neurolinguistic research on semantic cognition. However, these datasets are limited in size due to practical obstacles associated with exhaustively listing properties for a large number of words. In contrast, the development of distributional modelling techniques and the availability of vast text corpora have allowed researchers to construct effective vector space models of word meaning over large lexicons. However, this comes at the cost of interpretable, human-like information about word meaning. We propose a method for mapping human property knowledge onto a distributional semantic space, which adapts the word2vec architecture to the task of modelling concept features. Our approach gives a measure of concept and feature affinity in a single semantic space, which makes for easy and efficient ranking of candidate human-derived semantic properties for arbitrary words. We compare our model with a previous approach, and show that it performs better on several evaluation tasks. Finally, we discuss how our method could be used to develop efficient sampling techniques to extend existing feature norm datasets in a reliable way.
* 7 pages, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP 2019)
Using Sparse Semantic Embeddings Learned from Multimodal Text and Image Data to Model Human Conceptual Knowledge
Sep 18, 2018
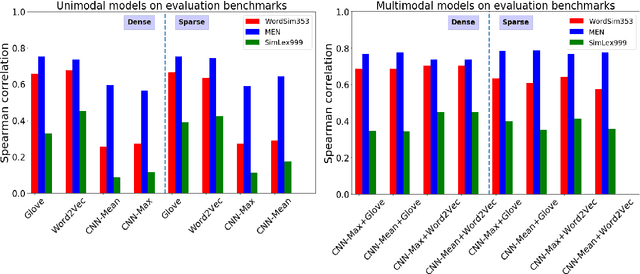

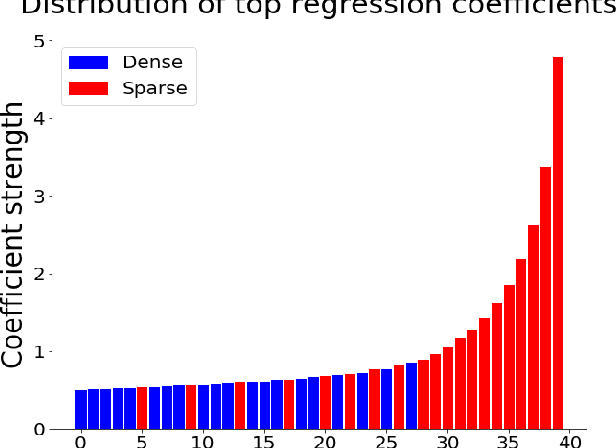
Distributional models provide a convenient way to model semantics using dense embedding spaces derived from unsupervised learning algorithms. However, the dimensions of dense embedding spaces are not designed to resemble human semantic knowledge. Moreover, embeddings are often built from a single source of information (typically text data), even though neurocognitive research suggests that semantics is deeply linked to both language and perception. In this paper, we combine multimodal information from both text and image-based representations derived from state-of-the-art distributional models to produce sparse, interpretable vectors using Joint Non-Negative Sparse Embedding. Through in-depth analyses comparing these sparse models to human-derived behavioural and neuroimaging data, we demonstrate their ability to predict interpretable linguistic descriptions of human ground-truth semantic knowledge.