 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatient level simulation and reinforcement learning to discover novel strategies for treating ovarian cancer
Oct 22, 2021



The prognosis for patients with epithelial ovarian cancer remains dismal despite improvements in survival for other cancers. Treatment involves multiple lines of chemotherapy and becomes increasingly heterogeneous after first-line therapy. Reinforcement learning with real-world outcomes data has the potential to identify novel treatment strategies to improve overall survival. We design a reinforcement learning environment to model epithelial ovarian cancer treatment trajectories and use model free reinforcement learning to investigate therapeutic regimens for simulated patients.
Using Sparse Semantic Embeddings Learned from Multimodal Text and Image Data to Model Human Conceptual Knowledge
Sep 18, 2018
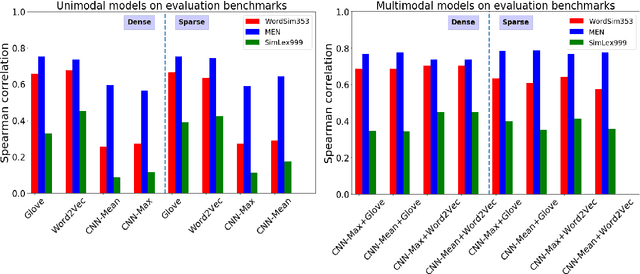

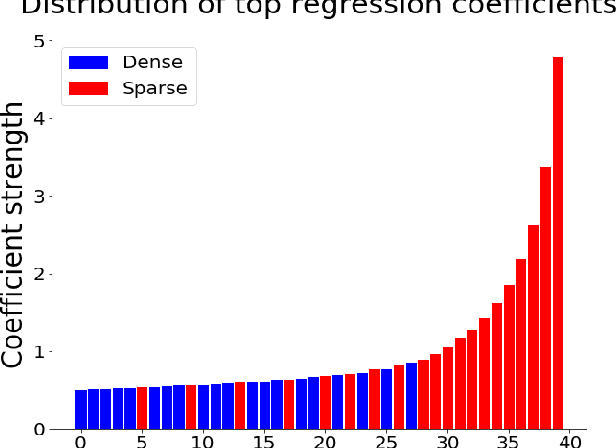
Distributional models provide a convenient way to model semantics using dense embedding spaces derived from unsupervised learning algorithms. However, the dimensions of dense embedding spaces are not designed to resemble human semantic knowledge. Moreover, embeddings are often built from a single source of information (typically text data), even though neurocognitive research suggests that semantics is deeply linked to both language and perception. In this paper, we combine multimodal information from both text and image-based representations derived from state-of-the-art distributional models to produce sparse, interpretable vectors using Joint Non-Negative Sparse Embedding. Through in-depth analyses comparing these sparse models to human-derived behavioural and neuroimaging data, we demonstrate their ability to predict interpretable linguistic descriptions of human ground-truth semantic knowledge.
NIPS 2016 Workshop on Representation Learning in Artificial and Biological Neural Networks (MLINI 2016)
Apr 10, 2017This workshop explores the interface between cognitive neuroscience and recent advances in AI fields that aim to reproduce human performance such as natural language processing and computer vision, and specifically deep learning approaches to such problems. When studying the cognitive capabilities of the brain, scientists follow a system identification approach in which they present different stimuli to the subjects and try to model the response that different brain areas have of that stimulus. The goal is to understand the brain by trying to find the function that expresses the activity of brain areas in terms of different properties of the stimulus. Experimental stimuli are becoming increasingly complex with more and more people being interested in studying real life phenomena such as the perception of natural images or natural sentences. There is therefore a need for a rich and adequate vector representation of the properties of the stimulus, that we can obtain using advances in machine learning. In parallel, new ML approaches, many of which in deep learning, are inspired to a certain extent by human behavior or biological principles. Neural networks for example were originally inspired by biological neurons. More recently, processes such as attention are being used which have are inspired by human behavior. However, the large bulk of these methods are independent of findings about brain function, and it is unclear whether it is at all beneficial for machine learning to try to emulate brain function in order to achieve the same tasks that the brain achieves.
Scoup-SMT: Scalable Coupled Sparse Matrix-Tensor Factorization
Feb 28, 2013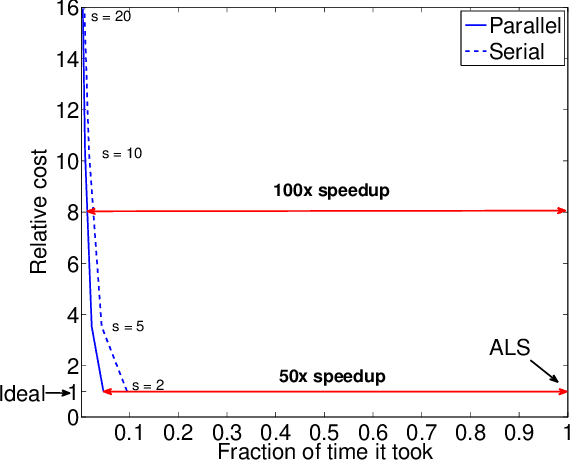
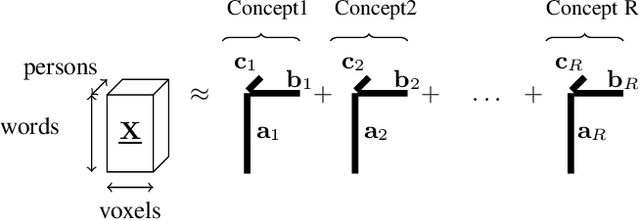
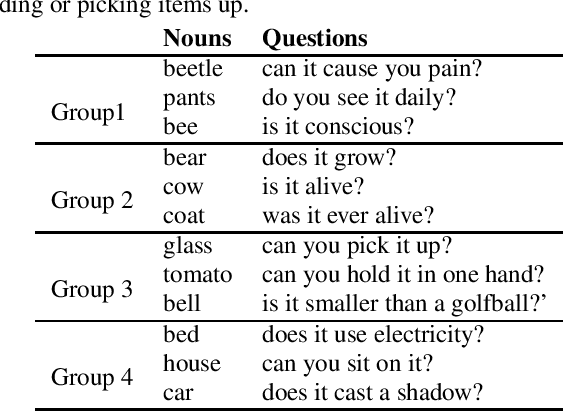
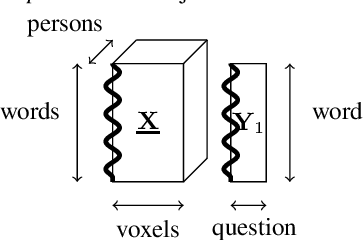
How can we correlate neural activity in the human brain as it responds to words, with behavioral data expressed as answers to questions about these same words? In short, we want to find latent variables, that explain both the brain activity, as well as the behavioral responses. We show that this is an instance of the Coupled Matrix-Tensor Factorization (CMTF) problem. We propose Scoup-SMT, a novel, fast, and parallel algorithm that solves the CMTF problem and produces a sparse latent low-rank subspace of the data. In our experiments, we find that Scoup-SMT is 50-100 times faster than a state-of-the-art algorithm for CMTF, along with a 5 fold increase in sparsity. Moreover, we extend Scoup-SMT to handle missing data without degradation of performance. We apply Scoup-SMT to BrainQ, a dataset consisting of a (nouns, brain voxels, human subjects) tensor and a (nouns, properties) matrix, with coupling along the nouns dimension. Scoup-SMT is able to find meaningful latent variables, as well as to predict brain activity with competitive accuracy. Finally, we demonstrate the generality of Scoup-SMT, by applying it on a Facebook dataset (users, friends, wall-postings); there, Scoup-SMT spots spammer-like anomalies.