 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOKGIT: Open Knowledge Graph Link Prediction with Implicit Types
Jun 24, 2021
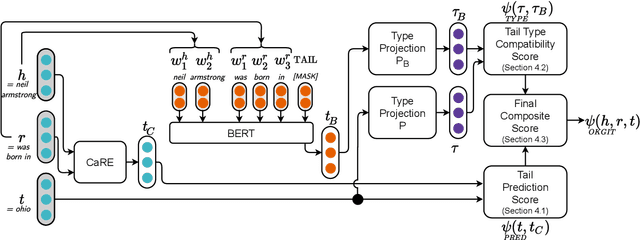
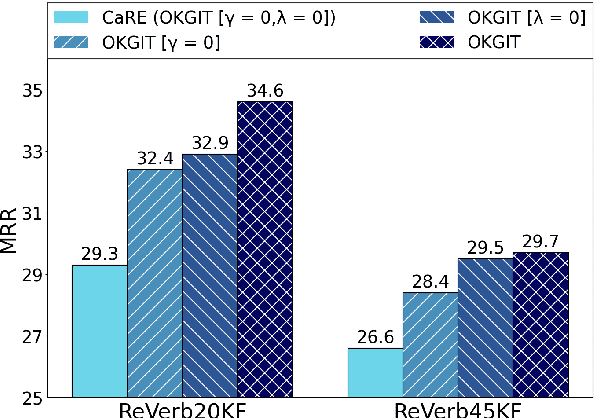
Open Knowledge Graphs (OpenKG) refer to a set of (head noun phrase, relation phrase, tail noun phrase) triples such as (tesla, return to, new york) extracted from a corpus using OpenIE tools. While OpenKGs are easy to bootstrap for a domain, they are very sparse and far from being directly usable in an end task. Therefore, the task of predicting new facts, i.e., link prediction, becomes an important step while using these graphs in downstream tasks such as text comprehension, question answering, and web search query recommendation. Learning embeddings for OpenKGs is one approach for link prediction that has received some attention lately. However, on careful examination, we found that current OpenKG link prediction algorithms often predict noun phrases (NPs) with incompatible types for given noun and relation phrases. We address this problem in this work and propose OKGIT that improves OpenKG link prediction using novel type compatibility score and type regularization. With extensive experiments on multiple datasets, we show that the proposed method achieves state-of-the-art performance while producing type compatible NPs in the link prediction task.
ASAP: Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations
Nov 18, 2019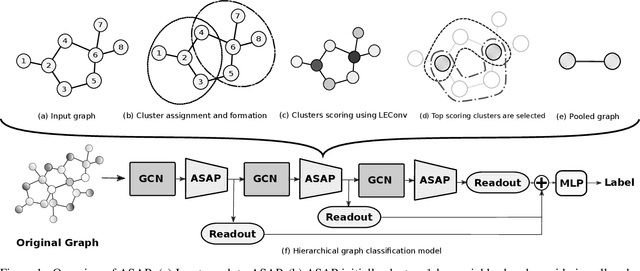

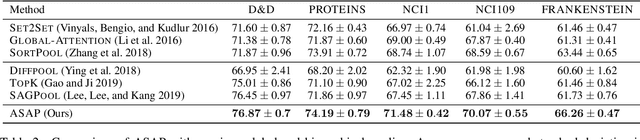
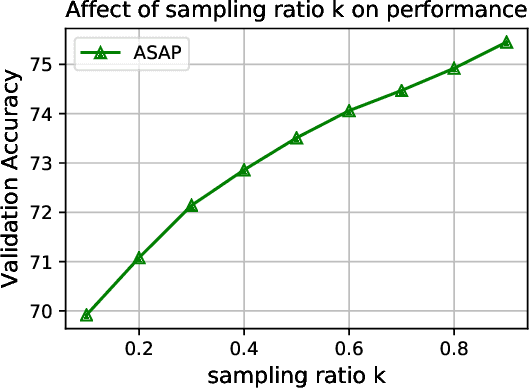
Graph Neural Networks (GNN) have been shown to work effectively for modeling graph structured data to solve tasks such as node classification, link prediction and graph classification. There has been some recent progress in defining the notion of pooling in graphs whereby the model tries to generate a graph level representation by downsampling and summarizing the information present in the nodes. Existing pooling methods either fail to effectively capture the graph substructure or do not easily scale to large graphs. In this work, we propose ASAP (Adaptive Structure Aware Pooling), a sparse and differentiable pooling method that addresses the limitations of previous graph pooling architectures. ASAP utilizes a novel self-attention network along with a modified GNN formulation to capture the importance of each node in a given graph. It also learns a sparse soft cluster assignment for nodes at each layer to effectively pool the subgraphs to form the pooled graph. Through extensive experiments on multiple datasets and theoretical analysis, we motivate our choice of the components used in ASAP. Our experimental results show that combining existing GNN architectures with ASAP leads to state-of-the-art results on multiple graph classification benchmarks. ASAP has an average improvement of 4\%, compared to current sparse hierarchical state-of-the-art method.
Revisiting Simple Neural Networks for Learning Representations of Knowledge Graphs
Jan 08, 2018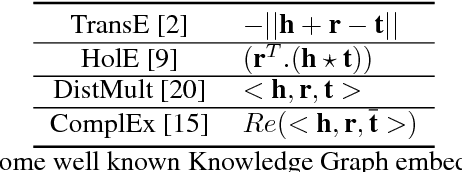
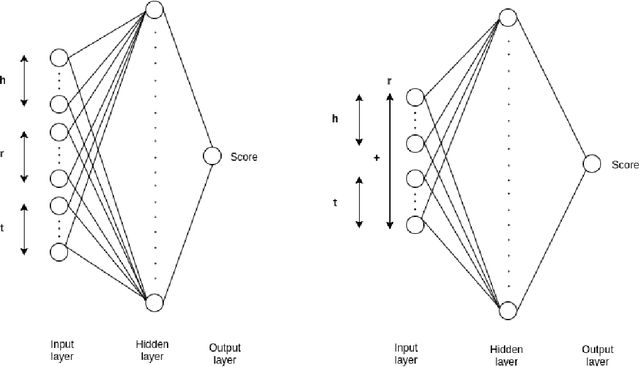


We address the problem of learning vector representations for entities and relations in Knowledge Graphs (KGs) for Knowledge Base Completion (KBC). This problem has received significant attention in the past few years and multiple methods have been proposed. Most of the existing methods in the literature use a predefined characteristic scoring function for evaluating the correctness of KG triples. These scoring functions distinguish correct triples (high score) from incorrect ones (low score). However, their performance vary across different datasets. In this work, we demonstrate that a simple neural network based score function can consistently achieve near start-of-the-art performance on multiple datasets. We also quantitatively demonstrate biases in standard benchmark datasets, and highlight the need to perform evaluation spanning various datasets.
Inducing Interpretability in Knowledge Graph Embeddings
Dec 10, 2017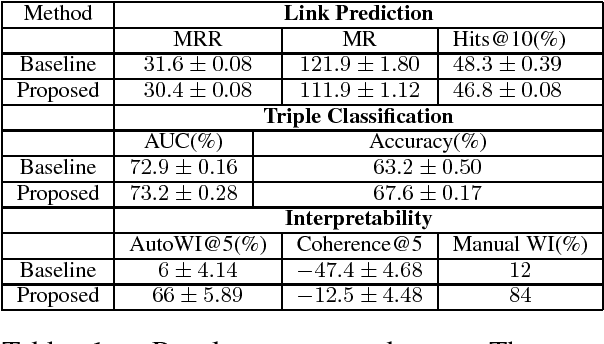
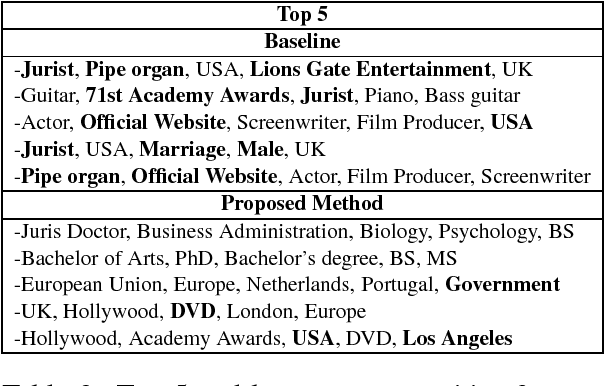
We study the problem of inducing interpretability in KG embeddings. Specifically, we explore the Universal Schema (Riedel et al., 2013) and propose a method to induce interpretability. There have been many vector space models proposed for the problem, however, most of these methods don't address the interpretability (semantics) of individual dimensions. In this work, we study this problem and propose a method for inducing interpretability in KG embeddings using entity co-occurrence statistics. The proposed method significantly improves the interpretability, while maintaining comparable performance in other KG tasks.
Scaling Graph-based Semi Supervised Learning to Large Number of Labels Using Count-Min Sketch
Feb 27, 2014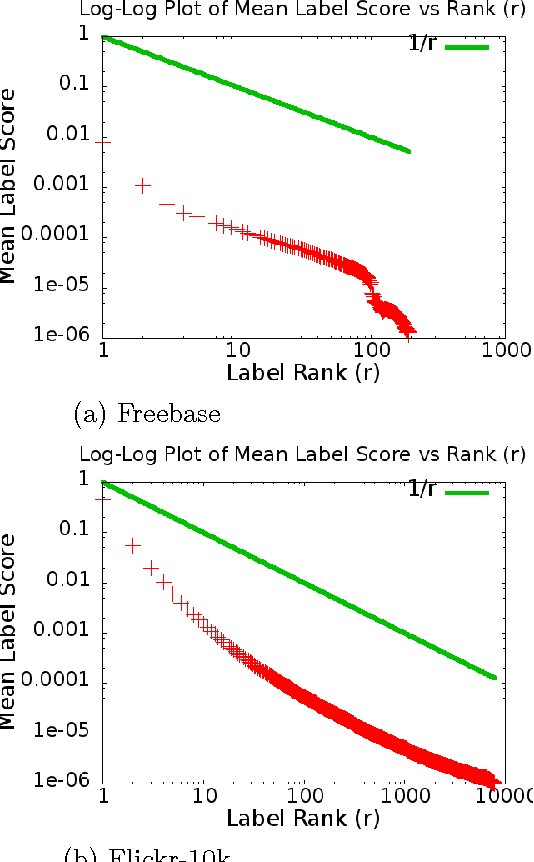

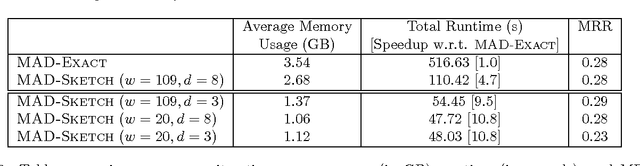
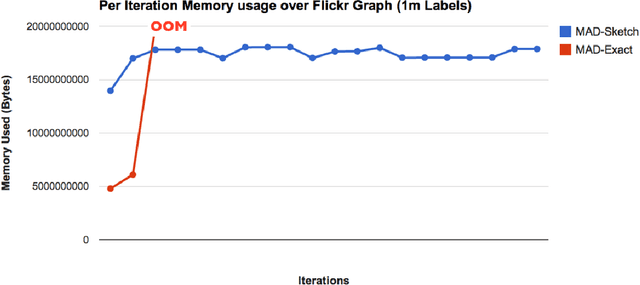
Graph-based Semi-supervised learning (SSL) algorithms have been successfully used in a large number of applications. These methods classify initially unlabeled nodes by propagating label information over the structure of graph starting from seed nodes. Graph-based SSL algorithms usually scale linearly with the number of distinct labels (m), and require O(m) space on each node. Unfortunately, there exist many applications of practical significance with very large m over large graphs, demanding better space and time complexity. In this paper, we propose MAD-SKETCH, a novel graph-based SSL algorithm which compactly stores label distribution on each node using Count-min Sketch, a randomized data structure. We present theoretical analysis showing that under mild conditions, MAD-SKETCH can reduce space complexity at each node from O(m) to O(log m), and achieve similar savings in time complexity as well. We support our analysis through experiments on multiple real world datasets. We observe that MAD-SKETCH achieves similar performance as existing state-of-the-art graph- based SSL algorithms, while requiring smaller memory footprint and at the same time achieving up to 10x speedup. We find that MAD-SKETCH is able to scale to datasets with one million labels, which is beyond the scope of existing graph- based SSL algorithms.
Scoup-SMT: Scalable Coupled Sparse Matrix-Tensor Factorization
Feb 28, 2013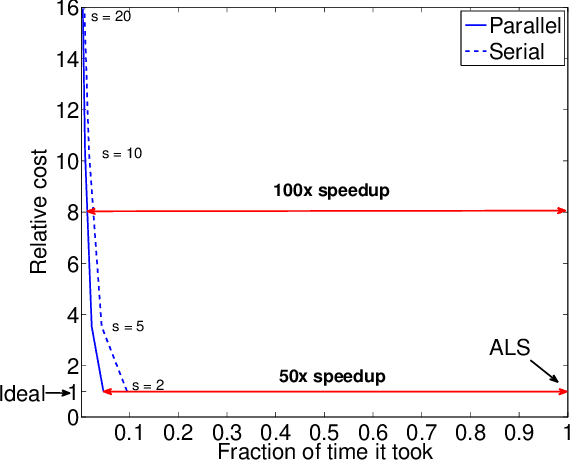
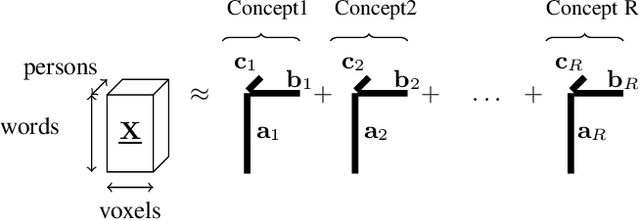
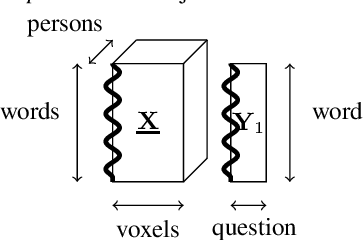
How can we correlate neural activity in the human brain as it responds to words, with behavioral data expressed as answers to questions about these same words? In short, we want to find latent variables, that explain both the brain activity, as well as the behavioral responses. We show that this is an instance of the Coupled Matrix-Tensor Factorization (CMTF) problem. We propose Scoup-SMT, a novel, fast, and parallel algorithm that solves the CMTF problem and produces a sparse latent low-rank subspace of the data. In our experiments, we find that Scoup-SMT is 50-100 times faster than a state-of-the-art algorithm for CMTF, along with a 5 fold increase in sparsity. Moreover, we extend Scoup-SMT to handle missing data without degradation of performance. We apply Scoup-SMT to BrainQ, a dataset consisting of a (nouns, brain voxels, human subjects) tensor and a (nouns, properties) matrix, with coupling along the nouns dimension. Scoup-SMT is able to find meaningful latent variables, as well as to predict brain activity with competitive accuracy. Finally, we demonstrate the generality of Scoup-SMT, by applying it on a Facebook dataset (users, friends, wall-postings); there, Scoup-SMT spots spammer-like anomalies.