 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOKGIT: Open Knowledge Graph Link Prediction with Implicit Types
Jun 24, 2021
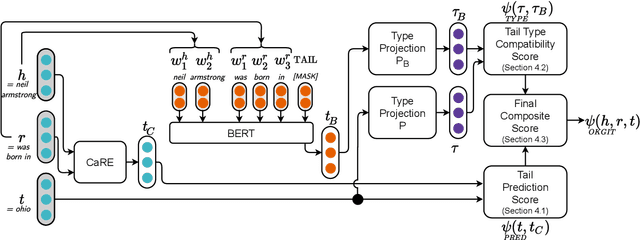
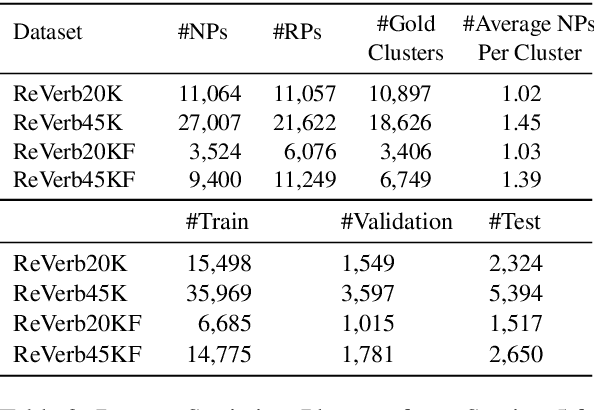
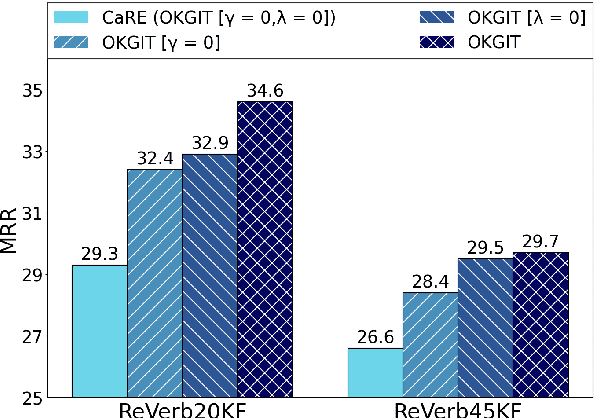
Open Knowledge Graphs (OpenKG) refer to a set of (head noun phrase, relation phrase, tail noun phrase) triples such as (tesla, return to, new york) extracted from a corpus using OpenIE tools. While OpenKGs are easy to bootstrap for a domain, they are very sparse and far from being directly usable in an end task. Therefore, the task of predicting new facts, i.e., link prediction, becomes an important step while using these graphs in downstream tasks such as text comprehension, question answering, and web search query recommendation. Learning embeddings for OpenKGs is one approach for link prediction that has received some attention lately. However, on careful examination, we found that current OpenKG link prediction algorithms often predict noun phrases (NPs) with incompatible types for given noun and relation phrases. We address this problem in this work and propose OKGIT that improves OpenKG link prediction using novel type compatibility score and type regularization. With extensive experiments on multiple datasets, we show that the proposed method achieves state-of-the-art performance while producing type compatible NPs in the link prediction task.
Revisiting Simple Neural Networks for Learning Representations of Knowledge Graphs
Jan 08, 2018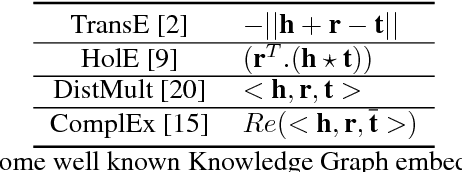
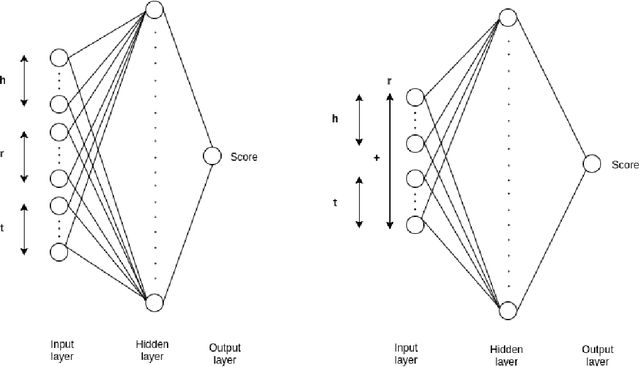


We address the problem of learning vector representations for entities and relations in Knowledge Graphs (KGs) for Knowledge Base Completion (KBC). This problem has received significant attention in the past few years and multiple methods have been proposed. Most of the existing methods in the literature use a predefined characteristic scoring function for evaluating the correctness of KG triples. These scoring functions distinguish correct triples (high score) from incorrect ones (low score). However, their performance vary across different datasets. In this work, we demonstrate that a simple neural network based score function can consistently achieve near start-of-the-art performance on multiple datasets. We also quantitatively demonstrate biases in standard benchmark datasets, and highlight the need to perform evaluation spanning various datasets.
Inducing Interpretability in Knowledge Graph Embeddings
Dec 10, 2017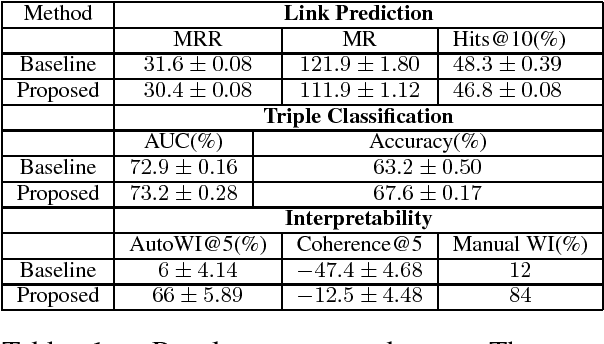
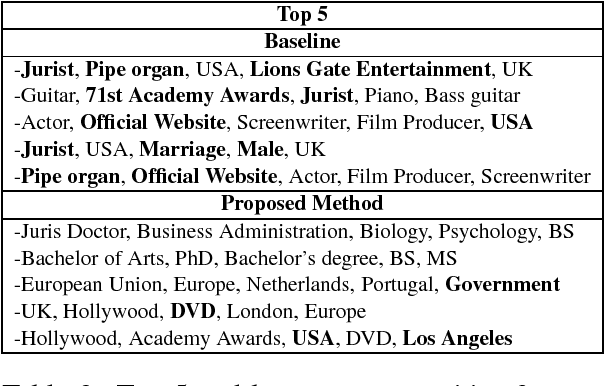
We study the problem of inducing interpretability in KG embeddings. Specifically, we explore the Universal Schema (Riedel et al., 2013) and propose a method to induce interpretability. There have been many vector space models proposed for the problem, however, most of these methods don't address the interpretability (semantics) of individual dimensions. In this work, we study this problem and propose a method for inducing interpretability in KG embeddings using entity co-occurrence statistics. The proposed method significantly improves the interpretability, while maintaining comparable performance in other KG tasks.