 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Underwater, Fault-Tolerant, Laser-Aided Robotic Multi-Modal Dense SLAM System for Continuous Underwater In-Situ Observation
Apr 30, 2025Existing underwater SLAM systems are difficult to work effectively in texture-sparse and geometrically degraded underwater environments, resulting in intermittent tracking and sparse mapping. Therefore, we present Water-DSLAM, a novel laser-aided multi-sensor fusion system that can achieve uninterrupted, fault-tolerant dense SLAM capable of continuous in-situ observation in diverse complex underwater scenarios through three key innovations: Firstly, we develop Water-Scanner, a multi-sensor fusion robotic platform featuring a self-designed Underwater Binocular Structured Light (UBSL) module that enables high-precision 3D perception. Secondly, we propose a fault-tolerant triple-subsystem architecture combining: 1) DP-INS (DVL- and Pressure-aided Inertial Navigation System): fusing inertial measurement unit, doppler velocity log, and pressure sensor based Error-State Kalman Filter (ESKF) to provide high-frequency absolute odometry 2) Water-UBSL: a novel Iterated ESKF (IESKF)-based tight coupling between UBSL and DP-INS to mitigate UBSL's degeneration issues 3) Water-Stereo: a fusion of DP-INS and stereo camera for accurate initialization and tracking. Thirdly, we introduce a multi-modal factor graph back-end that dynamically fuses heterogeneous sensor data. The proposed multi-sensor factor graph maintenance strategy efficiently addresses issues caused by asynchronous sensor frequencies and partial data loss. Experimental results demonstrate Water-DSLAM achieves superior robustness (0.039 m trajectory RMSE and 100\% continuity ratio during partial sensor dropout) and dense mapping (6922.4 points/m^3 in 750 m^3 water volume, approximately 10 times denser than existing methods) in various challenging environments, including pools, dark underwater scenes, 16-meter-deep sinkholes, and field rivers. Our project is available at https://water-scanner.github.io/.
EPRecon: An Efficient Framework for Real-Time Panoptic 3D Reconstruction from Monocular Video
Sep 03, 2024



Panoptic 3D reconstruction from a monocular video is a fundamental perceptual task in robotic scene understanding. However, existing efforts suffer from inefficiency in terms of inference speed and accuracy, limiting their practical applicability. We present EPRecon, an efficient real-time panoptic 3D reconstruction framework. Current volumetric-based reconstruction methods usually utilize multi-view depth map fusion to obtain scene depth priors, which is time-consuming and poses challenges to real-time scene reconstruction. To end this, we propose a lightweight module to directly estimate scene depth priors in a 3D volume for reconstruction quality improvement by generating occupancy probabilities of all voxels. In addition, to infer richer panoptic features from occupied voxels, EPRecon extracts panoptic features from both voxel features and corresponding image features, obtaining more detailed and comprehensive instance-level semantic information and achieving more accurate segmentation results. Experimental results on the ScanNetV2 dataset demonstrate the superiority of EPRecon over current state-of-the-art methods in terms of both panoptic 3D reconstruction quality and real-time inference. Code is available at https://github.com/zhen6618/EPRecon.
Completely Occluded and Dense Object Instance Segmentation Using Box Prompt-Based Segmentation Foundation Models
Jan 16, 2024Completely occluded and dense object instance segmentation (IS) is an important and challenging task. Although current amodal IS methods can predict invisible regions of occluded objects, they are difficult to directly predict completely occluded objects. For dense object IS, existing box-based methods are overly dependent on the performance of bounding box detection. In this paper, we propose CFNet, a coarse-to-fine IS framework for completely occluded and dense objects, which is based on box prompt-based segmentation foundation models (BSMs). Specifically, CFNet first detects oriented bounding boxes (OBBs) to distinguish instances and provide coarse localization information. Then, it predicts OBB prompt-related masks for fine segmentation. To predict completely occluded object instances, CFNet performs IS on occluders and utilizes prior geometric properties, which overcomes the difficulty of directly predicting completely occluded object instances. Furthermore, based on BSMs, CFNet reduces the dependence on bounding box detection performance, improving dense object IS performance. Moreover, we propose a novel OBB prompt encoder for BSMs. To make CFNet more lightweight, we perform knowledge distillation on it and introduce a Gaussian smoothing method for teacher targets. Experimental results demonstrate that CFNet achieves the best performance on both industrial and publicly available datasets.
Linear Gaussian Bounding Box Representation and Ring-Shaped Rotated Convolution for Oriented Object Detection
Nov 14, 2023In oriented object detection, current representations of oriented bounding boxes (OBBs) often suffer from boundary discontinuity problem. Methods of designing continuous regression losses do not essentially solve this problem. Although Gaussian bounding box (GBB) representation avoids this problem, directly regressing GBB is susceptible to numerical instability. We propose linear GBB (LGBB), a novel OBB representation. By linearly transforming the elements of GBB, LGBB avoids the boundary discontinuity problem and has high numerical stability. In addition, existing convolution-based rotation-sensitive feature extraction methods only have local receptive fields, resulting in slow feature aggregation. We propose ring-shaped rotated convolution (RRC), which adaptively rotates feature maps to arbitrary orientations to extract rotation-sensitive features under a ring-shaped receptive field, rapidly aggregating features and contextual information. Experimental results demonstrate that LGBB and RRC achieve state-of-the-art performance. Furthermore, integrating LGBB and RRC into various models effectively improves detection accuracy.
SEEK: model extraction attack against hybrid secure inference protocols
Sep 14, 2022
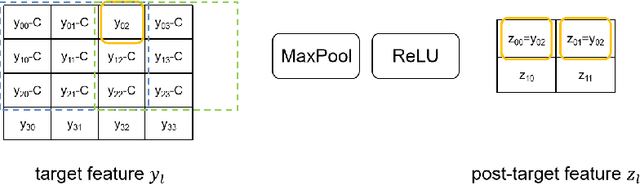
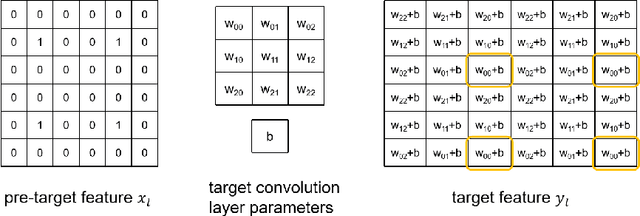

Security concerns about a machine learning model used in a prediction-as-a-service include the privacy of the model, the query and the result. Secure inference solutions based on homomorphic encryption (HE) and/or multiparty computation (MPC) have been developed to protect all the sensitive information. One of the most efficient type of solution utilizes HE for linear layers, and MPC for non-linear layers. However, for such hybrid protocols with semi-honest security, an adversary can malleate the intermediate features in the inference process, and extract model information more effectively than methods against inference service in plaintext. In this paper, we propose SEEK, a general extraction method for hybrid secure inference services outputing only class labels. This method can extract each layer of the target model independently, and is not affected by the depth of the model. For ResNet-18, SEEK can extract a parameter with less than 50 queries on average, with average error less than $0.03\%$.
Robust and accurate depth estimation by fusing LiDAR and Stereo
Jul 13, 2022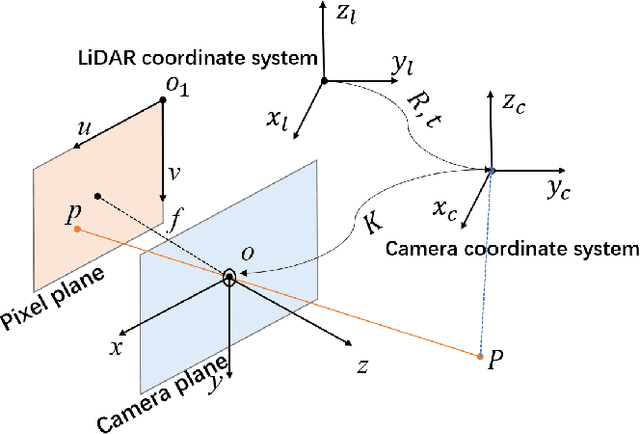
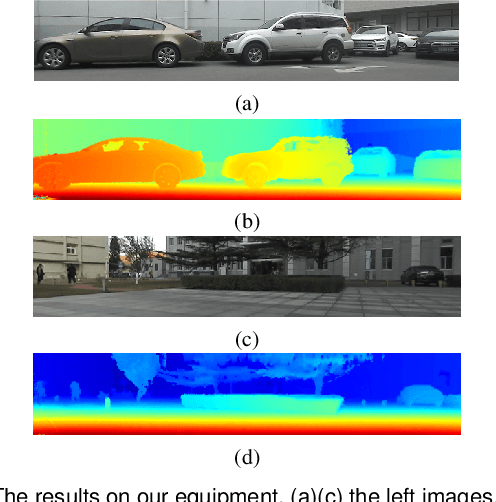
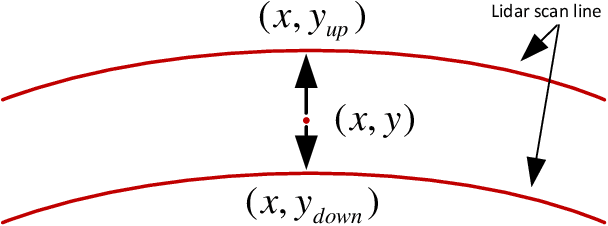
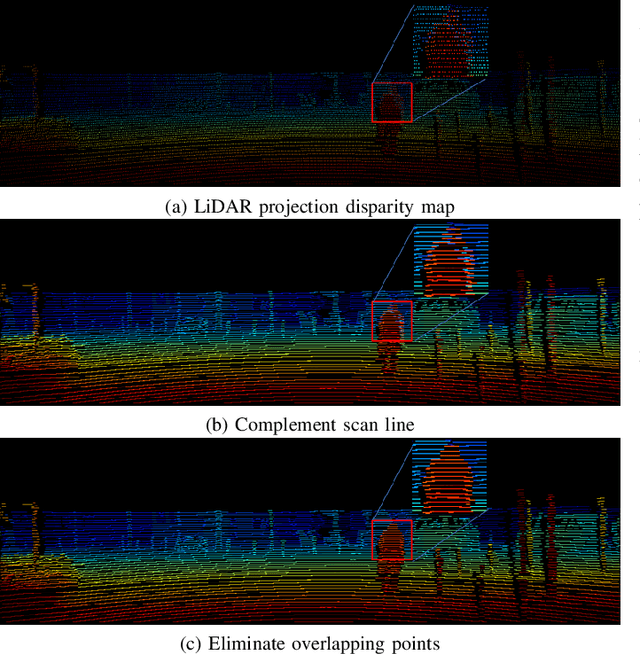
Depth estimation is one of the key technologies in some fields such as autonomous driving and robot navigation. However, the traditional method of using a single sensor is inevitably limited by the performance of the sensor. Therefore, a precision and robust method for fusing the LiDAR and stereo cameras is proposed. This method fully combines the advantages of the LiDAR and stereo camera, which can retain the advantages of the high precision of the LiDAR and the high resolution of images respectively. Compared with the traditional stereo matching method, the texture of the object and lighting conditions have less influence on the algorithm. Firstly, the depth of the LiDAR data is converted to the disparity of the stereo camera. Because the density of the LiDAR data is relatively sparse on the y-axis, the converted disparity map is up-sampled using the interpolation method. Secondly, in order to make full use of the precise disparity map, the disparity map and stereo matching are fused to propagate the accurate disparity. Finally, the disparity map is converted to the depth map. Moreover, the converted disparity map can also increase the speed of the algorithm. We evaluate the proposed pipeline on the KITTI benchmark. The experiment demonstrates that our algorithm has higher accuracy than several classic methods.