 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPRecon: An Efficient Framework for Real-Time Panoptic 3D Reconstruction from Monocular Video
Sep 03, 2024



Panoptic 3D reconstruction from a monocular video is a fundamental perceptual task in robotic scene understanding. However, existing efforts suffer from inefficiency in terms of inference speed and accuracy, limiting their practical applicability. We present EPRecon, an efficient real-time panoptic 3D reconstruction framework. Current volumetric-based reconstruction methods usually utilize multi-view depth map fusion to obtain scene depth priors, which is time-consuming and poses challenges to real-time scene reconstruction. To end this, we propose a lightweight module to directly estimate scene depth priors in a 3D volume for reconstruction quality improvement by generating occupancy probabilities of all voxels. In addition, to infer richer panoptic features from occupied voxels, EPRecon extracts panoptic features from both voxel features and corresponding image features, obtaining more detailed and comprehensive instance-level semantic information and achieving more accurate segmentation results. Experimental results on the ScanNetV2 dataset demonstrate the superiority of EPRecon over current state-of-the-art methods in terms of both panoptic 3D reconstruction quality and real-time inference. Code is available at https://github.com/zhen6618/EPRecon.
Completely Occluded and Dense Object Instance Segmentation Using Box Prompt-Based Segmentation Foundation Models
Jan 16, 2024Completely occluded and dense object instance segmentation (IS) is an important and challenging task. Although current amodal IS methods can predict invisible regions of occluded objects, they are difficult to directly predict completely occluded objects. For dense object IS, existing box-based methods are overly dependent on the performance of bounding box detection. In this paper, we propose CFNet, a coarse-to-fine IS framework for completely occluded and dense objects, which is based on box prompt-based segmentation foundation models (BSMs). Specifically, CFNet first detects oriented bounding boxes (OBBs) to distinguish instances and provide coarse localization information. Then, it predicts OBB prompt-related masks for fine segmentation. To predict completely occluded object instances, CFNet performs IS on occluders and utilizes prior geometric properties, which overcomes the difficulty of directly predicting completely occluded object instances. Furthermore, based on BSMs, CFNet reduces the dependence on bounding box detection performance, improving dense object IS performance. Moreover, we propose a novel OBB prompt encoder for BSMs. To make CFNet more lightweight, we perform knowledge distillation on it and introduce a Gaussian smoothing method for teacher targets. Experimental results demonstrate that CFNet achieves the best performance on both industrial and publicly available datasets.
Linear Gaussian Bounding Box Representation and Ring-Shaped Rotated Convolution for Oriented Object Detection
Nov 14, 2023In oriented object detection, current representations of oriented bounding boxes (OBBs) often suffer from boundary discontinuity problem. Methods of designing continuous regression losses do not essentially solve this problem. Although Gaussian bounding box (GBB) representation avoids this problem, directly regressing GBB is susceptible to numerical instability. We propose linear GBB (LGBB), a novel OBB representation. By linearly transforming the elements of GBB, LGBB avoids the boundary discontinuity problem and has high numerical stability. In addition, existing convolution-based rotation-sensitive feature extraction methods only have local receptive fields, resulting in slow feature aggregation. We propose ring-shaped rotated convolution (RRC), which adaptively rotates feature maps to arbitrary orientations to extract rotation-sensitive features under a ring-shaped receptive field, rapidly aggregating features and contextual information. Experimental results demonstrate that LGBB and RRC achieve state-of-the-art performance. Furthermore, integrating LGBB and RRC into various models effectively improves detection accuracy.
RegHEC: Hand-Eye Calibration via Simultaneous Multi-view Point Clouds Registration of Arbitrary Object
Apr 27, 2023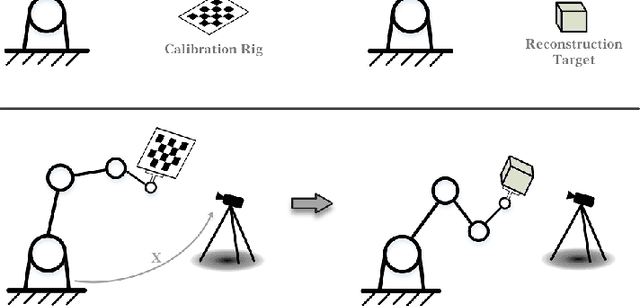



RegHEC is a registration-based hand-eye calibration technique with no need for accurate calibration rig but arbitrary available objects, applicable for both eye-in-hand and eye-to-hand cases. It tries to find the hand-eye relation which brings multi-view point clouds of arbitrary scene into simultaneous registration under a common reference frame. RegHEC first achieves initial alignment of multi-view point clouds via Bayesian optimization, where registration problem is modeled as a Gaussian process over hand-eye relation and the covariance function is modified to be compatible with distance metric in 3-D motion space SE(3), then passes the initial guess of hand-eye relation to an Anderson Accelerated ICP variant for later fine registration and accurate calibration. RegHEC has little requirement on calibration object, it is applicable with sphere, cone, cylinder and even simple plane, which can be quite challenging for correct point cloud registration and sensor motion estimation using existing methods. While suitable for most 3-D vision guided tasks, RegHEC is especially favorable for robotic 3-D reconstruction, as calibration and multi-view point clouds registration of reconstruction target are unified into a single process. Our technique is verified with extensive experiments using varieties of arbitrary objects and real hand-eye system. We release an open-source C++ implementation of RegHEC.