 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Monotonicity Constrained Attention Module for Emotion Classification with Limited EEG Data
Paper and Code
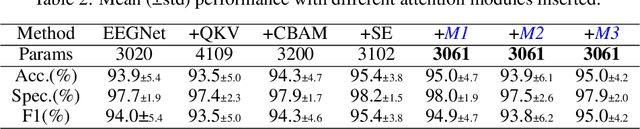
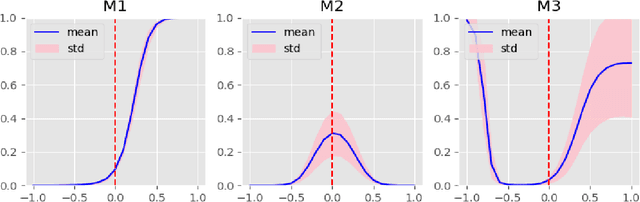
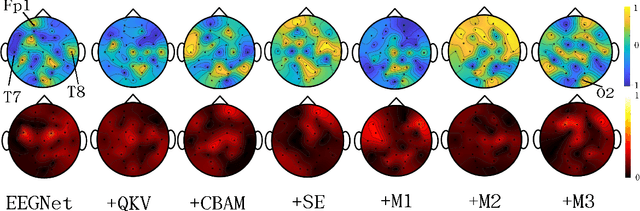
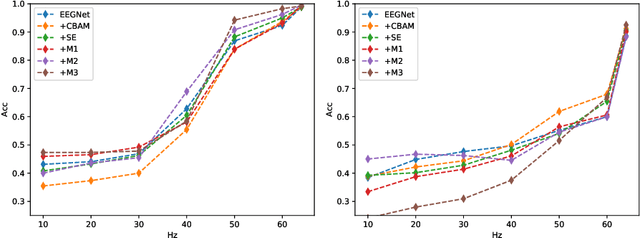
In this work, a parameter-efficient attention module is presented for emotion classification using a limited, or relatively small, number of electroencephalogram (EEG) signals. This module is called the Monotonicity Constrained Attention Module (MCAM) due to its capability of incorporating priors on the monotonicity when converting features' Gram matrices into attention matrices for better feature refinement. Our experiments have shown that MCAM's effectiveness is comparable to state-of-the-art attention modules in boosting the backbone network's performance in prediction while requiring less parameters. Several accompanying sensitivity analyses on trained models' prediction concerning different attacks are also performed. These attacks include various frequency domain filtering levels and gradually morphing between samples associated with multiple labels. Our results can help better understand different modules' behaviour in prediction and can provide guidance in applications where data is limited and are with noises.