 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Data Fusion Labeler (dFL): Challenges and Solutions to Data Harmonization, Labeling, and Provenance in Fusion Energy
Nov 12, 2025Fusion energy research increasingly depends on the ability to integrate heterogeneous, multimodal datasets from high-resolution diagnostics, control systems, and multiscale simulations. The sheer volume and complexity of these datasets demand the development of new tools capable of systematically harmonizing and extracting knowledge across diverse modalities. The Data Fusion Labeler (dFL) is introduced as a unified workflow instrument that performs uncertainty-aware data harmonization, schema-compliant data fusion, and provenance-rich manual and automated labeling at scale. By embedding alignment, normalization, and labeling within a reproducible, operator-order-aware framework, dFL reduces time-to-analysis by greater than 50X (e.g., enabling >200 shots/hour to be consistently labeled rather than a handful per day), enhances label (and subsequently training) quality, and enables cross-device comparability. Case studies from DIII-D demonstrate its application to automated ELM detection and confinement regime classification, illustrating its potential as a core component of data-driven discovery, model validation, and real-time control in future burning plasma devices.
KAM -- a Kernel Attention Module for Emotion Classification with EEG Data
Aug 17, 2022
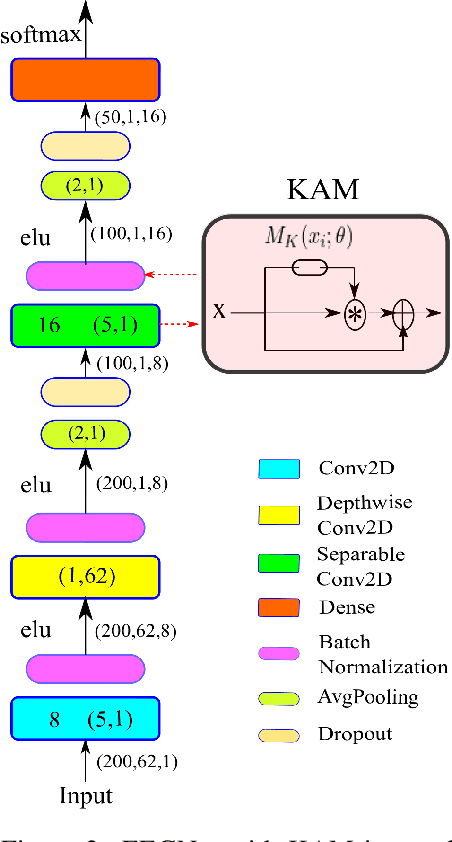
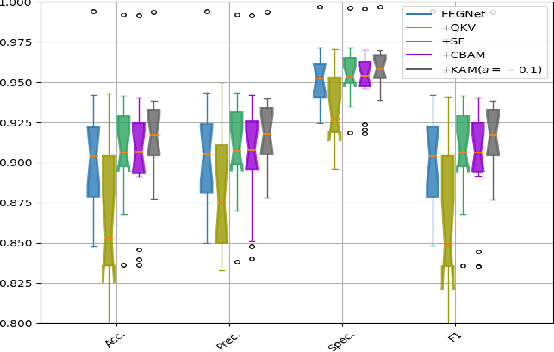
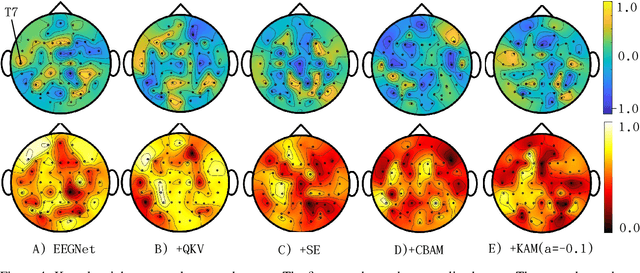
In this work, a kernel attention module is presented for the task of EEG-based emotion classification with neural networks. The proposed module utilizes a self-attention mechanism by performing a kernel trick, demanding significantly fewer trainable parameters and computations than standard attention modules. The design also provides a scalar for quantitatively examining the amount of attention assigned during deep feature refinement, hence help better interpret a trained model. Using EEGNet as the backbone model, extensive experiments are conducted on the SEED dataset to assess the module's performance on within-subject classification tasks compared to other SOTA attention modules. Requiring only one extra parameter, the inserted module is shown to boost the base model's mean prediction accuracy up to more than 1\% across 15 subjects. A key component of the method is the interpretability of solutions, which is addressed using several different techniques, and is included throughout as part of the dependency analysis.
A Monotonicity Constrained Attention Module for Emotion Classification with Limited EEG Data
Aug 17, 2022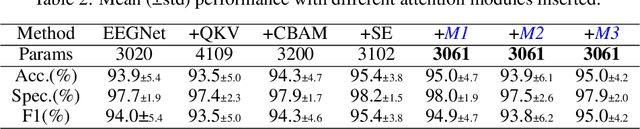
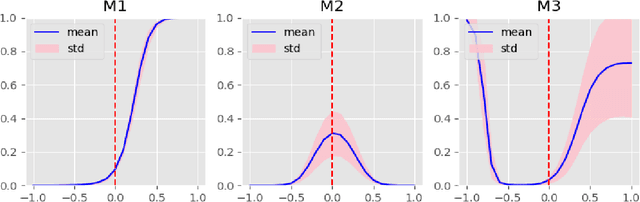
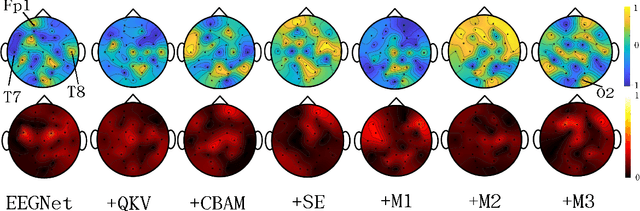
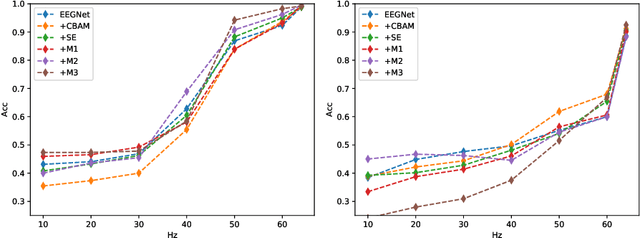
In this work, a parameter-efficient attention module is presented for emotion classification using a limited, or relatively small, number of electroencephalogram (EEG) signals. This module is called the Monotonicity Constrained Attention Module (MCAM) due to its capability of incorporating priors on the monotonicity when converting features' Gram matrices into attention matrices for better feature refinement. Our experiments have shown that MCAM's effectiveness is comparable to state-of-the-art attention modules in boosting the backbone network's performance in prediction while requiring less parameters. Several accompanying sensitivity analyses on trained models' prediction concerning different attacks are also performed. These attacks include various frequency domain filtering levels and gradually morphing between samples associated with multiple labels. Our results can help better understand different modules' behaviour in prediction and can provide guidance in applications where data is limited and are with noises.
Solving Irregular and Data-enriched Differential Equations using Deep Neural Networks
May 10, 2019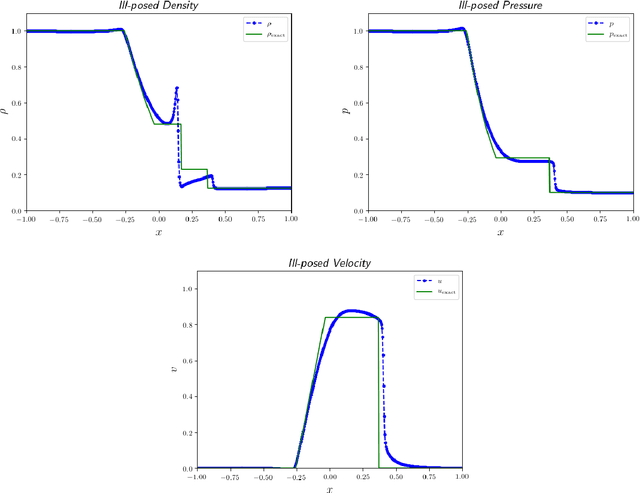
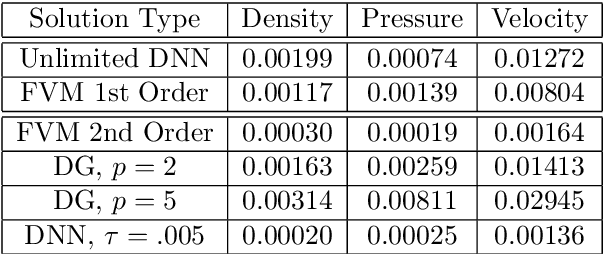
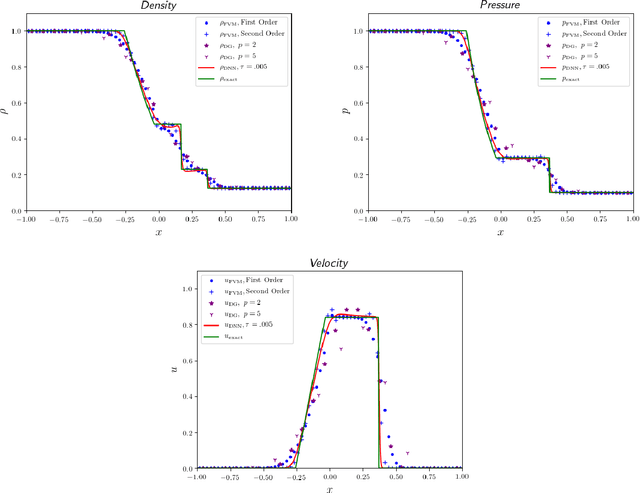
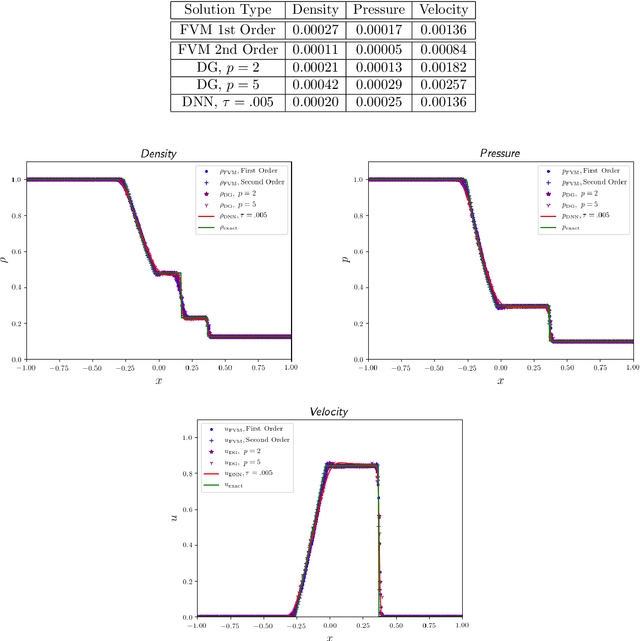
Recent work has introduced a simple numerical method for solving partial differential equations (PDEs) with deep neural networks (DNNs). This paper reviews and extends the method while applying it to analyze one of the most fundamental features in numerical PDEs and nonlinear analysis: irregular solutions. First, the Sod shock tube solution to compressible Euler equations is discussed, analyzed, and then compared to conventional finite element and finite volume methods. These methods are extended to consider performance improvements and simultaneous parameter space exploration. Next, a shock solution to compressible magnetohydrodynamics (MHD) is solved for, and used in a scenario where experimental data is utilized to enhance a PDE system that is \emph{a priori} insufficient to validate against the observed/experimental data. This is accomplished by enriching the model PDE system with source terms and using supervised training on synthetic experimental data. The resulting DNN framework for PDEs seems to demonstrate almost fantastical ease of system prototyping, natural integration of large data sets (be they synthetic or experimental), all while simultaneously enabling single-pass exploration of the entire parameter space.