 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMLET -- A Learning Curve-Enabled Multi-Armed Bandit for Algorithm Selection
Paper and Code
Jan 30, 2020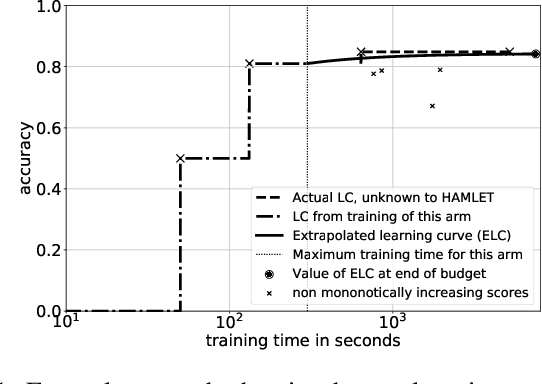
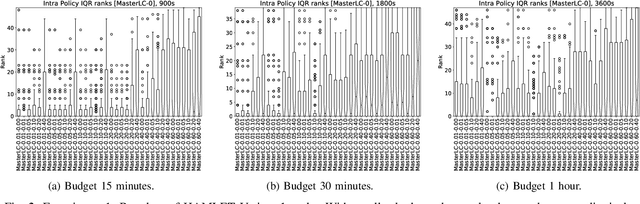
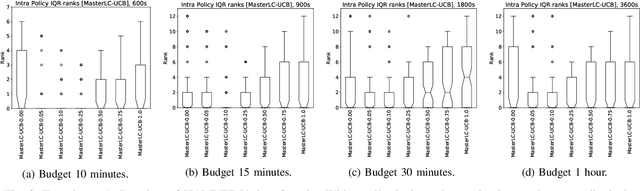
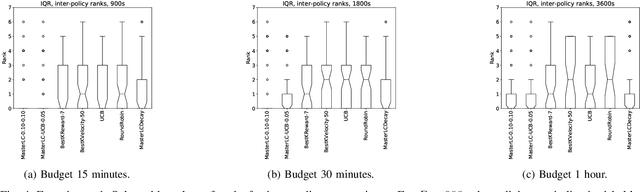
Automated algorithm selection and hyperparameter tuning facilitates the application of machine learning. Traditional multi-armed bandit strategies look to the history of observed rewards to identify the most promising arms for optimizing expected total reward in the long run. When considering limited time budgets and computational resources, this backward view of rewards is inappropriate as the bandit should look into the future for anticipating the highest final reward at the end of a specified time budget. This work addresses that insight by introducing HAMLET, which extends the bandit approach with learning curve extrapolation and computation time-awareness for selecting among a set of machine learning algorithms. Results show that the HAMLET Variants 1-3 exhibit equal or better performance than other bandit-based algorithm selection strategies in experiments with recorded hyperparameter tuning traces for the majority of considered time budgets. The best performing HAMLET Variant 3 combines learning curve extrapolation with the well-known upper confidence bound exploration bonus. That variant performs better than all non-HAMLET policies with statistical significance at the 95% level for 1,485 runs.