 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOV-REK: Governed Reward Engineering Kernels for Designing Robust Multi-Agent Reinforcement Learning Systems
Paper and Code
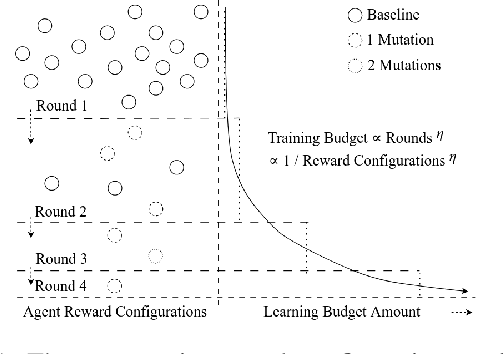
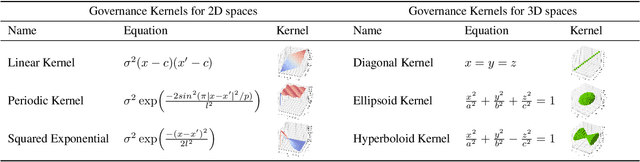
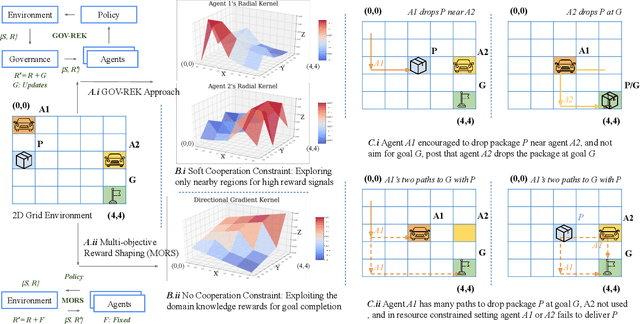
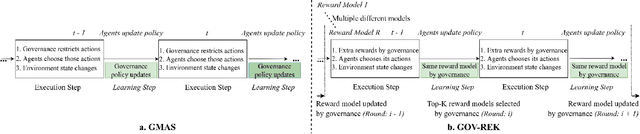
For multi-agent reinforcement learning systems (MARLS), the problem formulation generally involves investing massive reward engineering effort specific to a given problem. However, this effort often cannot be translated to other problems; worse, it gets wasted when system dynamics change drastically. This problem is further exacerbated in sparse reward scenarios, where a meaningful heuristic can assist in the policy convergence task. We propose GOVerned Reward Engineering Kernels (GOV-REK), which dynamically assign reward distributions to agents in MARLS during its learning stage. We also introduce governance kernels, which exploit the underlying structure in either state or joint action space for assigning meaningful agent reward distributions. During the agent learning stage, it iteratively explores different reward distribution configurations with a Hyperband-like algorithm to learn ideal agent reward models in a problem-agnostic manner. Our experiments demonstrate that our meaningful reward priors robustly jumpstart the learning process for effectively learning different MARL problems.