 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Visual Saliency Methods and Sparse Keypoint Annotations to Providently Detect Vehicles at Night
Paper and Code
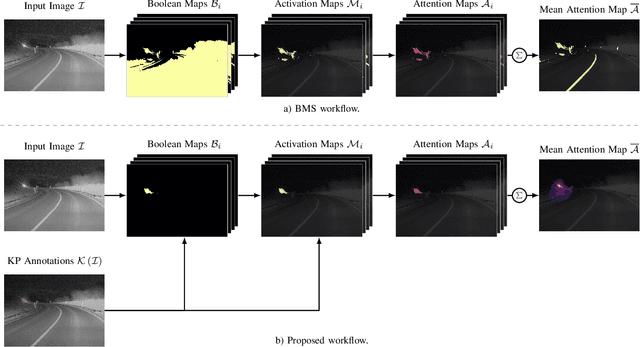



Provident detection of other road users at night has the potential for increasing road safety. For this purpose, humans intuitively use visual cues, such as light cones and light reflections emitted by other road users to be able to react to oncoming traffic at an early stage. This behavior can be imitated by computer vision methods by predicting the appearance of vehicles based on emitted light reflections caused by the vehicle's headlights. Since current object detection algorithms are mainly based on detecting directly visible objects annotated via bounding boxes, the detection and annotation of light reflections without sharp boundaries is challenging. For this reason, the extensive open-source dataset PVDN (Provident Vehicle Detection at Night) was published, which includes traffic scenarios at night with light reflections annotated via keypoints. In this paper, we explore the potential of saliency-based approaches to create different object representations based on the visual saliency and sparse keypoint annotations of the PVDN dataset. For that, we extend the general idea of Boolean map saliency towards a context-aware approach by taking into consideration sparse keypoint annotations by humans. We show that this approach allows for an automated derivation of different object representations, such as binary maps or bounding boxes so that detection models can be trained on different annotation variants and the problem of providently detecting vehicles at night can be tackled from different perspectives. With that, we provide further powerful tools and methods to study the problem of detecting vehicles at night before they are actually visible.