Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling with Unrestricted Delays
Paper and Code
Feb 24, 2022


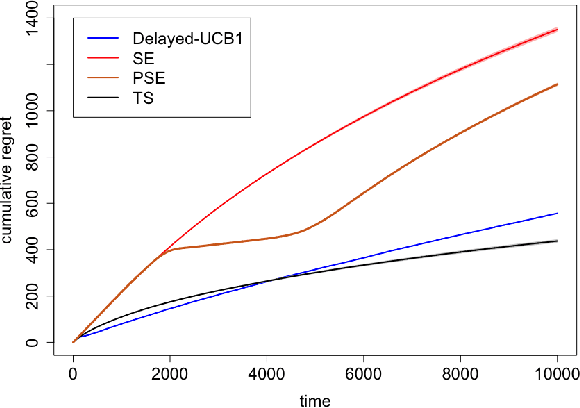
We investigate properties of Thompson Sampling in the stochastic multi-armed bandit problem with delayed feedback. In a setting with i.i.d delays, we establish to our knowledge the first regret bounds for Thompson Sampling with arbitrary delay distributions, including ones with unbounded expectation. Our bounds are qualitatively comparable to the best available bounds derived via ad-hoc algorithms, and only depend on delays via selected quantiles of the delay distributions. Furthermore, in extensive simulation experiments, we find that Thompson Sampling outperforms a number of alternative proposals, including methods specifically designed for settings with delayed feedback.
View paper on