 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeGNN: Temporal Dynamic Graph Learning for Time Series Forecasting
Jul 27, 2023



Time series forecasting lies at the core of important real-world applications in many fields of science and engineering. The abundance of large time series datasets that consist of complex patterns and long-term dependencies has led to the development of various neural network architectures. Graph neural network approaches, which jointly learn a graph structure based on the correlation of raw values of multivariate time series while forecasting, have recently seen great success. However, such solutions are often costly to train and difficult to scale. In this paper, we propose TimeGNN, a method that learns dynamic temporal graph representations that can capture the evolution of inter-series patterns along with the correlations of multiple series. TimeGNN achieves inference times 4 to 80 times faster than other state-of-the-art graph-based methods while achieving comparable forecasting performance
Time Series Forecasting Models Copy the Past: How to Mitigate
Jul 27, 2022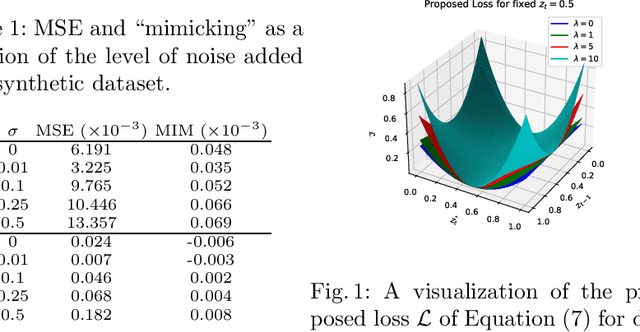
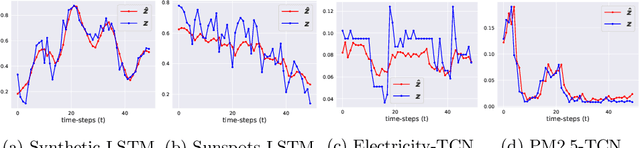
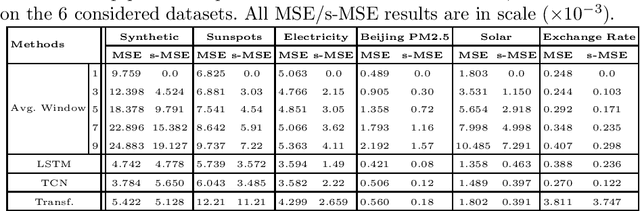
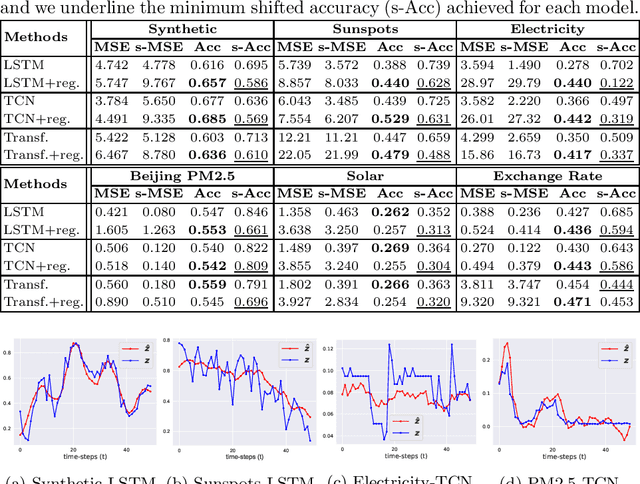
Time series forecasting is at the core of important application domains posing significant challenges to machine learning algorithms. Recently neural network architectures have been widely applied to the problem of time series forecasting. Most of these models are trained by minimizing a loss function that measures predictions' deviation from the real values. Typical loss functions include mean squared error (MSE) and mean absolute error (MAE). In the presence of noise and uncertainty, neural network models tend to replicate the last observed value of the time series, thus limiting their applicability to real-world data. In this paper, we provide a formal definition of the above problem and we also give some examples of forecasts where the problem is observed. We also propose a regularization term penalizing the replication of previously seen values. We evaluate the proposed regularization term both on synthetic and real-world datasets. Our results indicate that the regularization term mitigates to some extent the aforementioned problem and gives rise to more robust models.
Image Keypoint Matching using Graph Neural Networks
May 27, 2022Image matching is a key component of many tasks in computer vision and its main objective is to find correspondences between features extracted from different natural images. When images are represented as graphs, image matching boils down to the problem of graph matching which has been studied intensively in the past. In recent years, graph neural networks have shown great potential in the graph matching task, and have also been applied to image matching. In this paper, we propose a graph neural network for the problem of image matching. The proposed method first generates initial soft correspondences between keypoints using localized node embeddings and then iteratively refines the initial correspondences using a series of graph neural network layers. We evaluate our method on natural image datasets with keypoint annotations and show that, in comparison to a state-of-the-art model, our method speeds up inference times without sacrificing prediction accuracy.
Grounding Open-Domain Instructions to Automate Web Support Tasks
Apr 04, 2021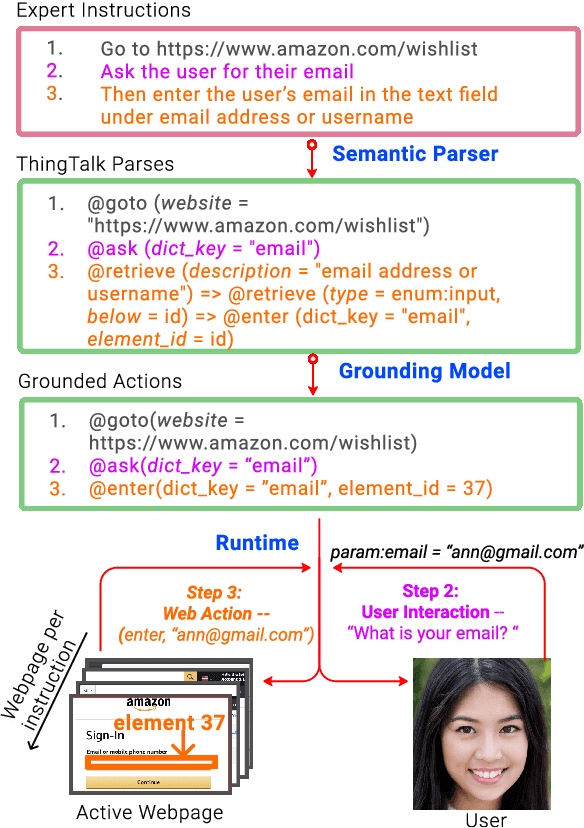
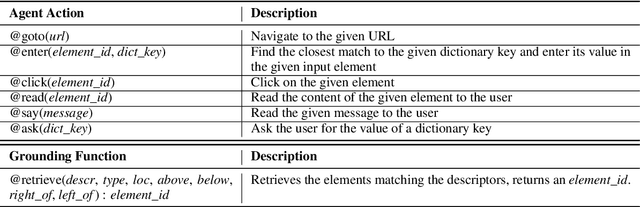
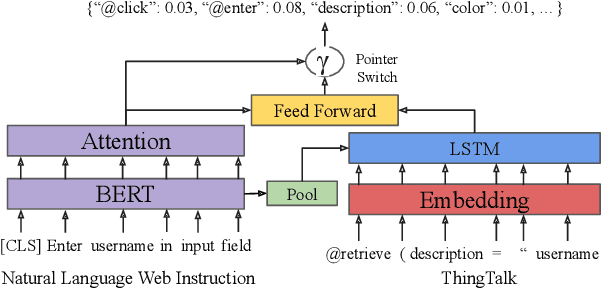

Grounding natural language instructions on the web to perform previously unseen tasks enables accessibility and automation. We introduce a task and dataset to train AI agents from open-domain, step-by-step instructions originally written for people. We build RUSS (Rapid Universal Support Service) to tackle this problem. RUSS consists of two models: First, a BERT-LSTM with pointers parses instructions to ThingTalk, a domain-specific language we design for grounding natural language on the web. Then, a grounding model retrieves the unique IDs of any webpage elements requested in ThingTalk. RUSS may interact with the user through a dialogue (e.g. ask for an address) or execute a web operation (e.g. click a button) inside the web runtime. To augment training, we synthesize natural language instructions mapped to ThingTalk. Our dataset consists of 80 different customer service problems from help websites, with a total of 741 step-by-step instructions and their corresponding actions. RUSS achieves 76.7% end-to-end accuracy predicting agent actions from single instructions. It outperforms state-of-the-art models that directly map instructions to actions without ThingTalk. Our user study shows that RUSS is preferred by actual users over web navigation.