 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
Certifiably Robust RAG against Retrieval Corruption
May 24, 2024



Retrieval-augmented generation (RAG) has been shown vulnerable to retrieval corruption attacks: an attacker can inject malicious passages into retrieval results to induce inaccurate responses. In this paper, we propose RobustRAG as the first defense framework against retrieval corruption attacks. The key insight of RobustRAG is an isolate-then-aggregate strategy: we get LLM responses from each passage in isolation and then securely aggregate these isolated responses. To instantiate RobustRAG, we design keyword-based and decoding-based algorithms for securely aggregating unstructured text responses. Notably, RobustRAG can achieve certifiable robustness: we can formally prove and certify that, for certain queries, RobustRAG can always return accurate responses, even when the attacker has full knowledge of our defense and can arbitrarily inject a small number of malicious passages. We evaluate RobustRAG on open-domain QA and long-form text generation datasets and demonstrate its effectiveness and generalizability across various tasks and datasets.
Lory: Fully Differentiable Mixture-of-Experts for Autoregressive Language Model Pre-training
May 06, 2024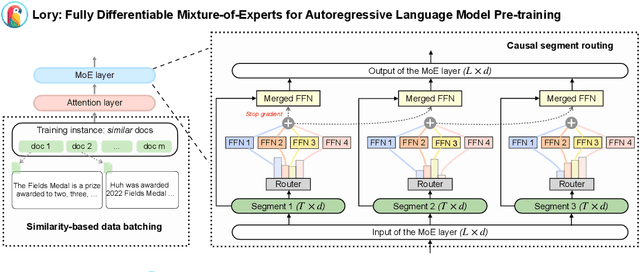



Mixture-of-experts (MoE) models facilitate efficient scaling; however, training the router network introduces the challenge of optimizing a non-differentiable, discrete objective. Recently, a fully-differentiable MoE architecture, SMEAR, was proposed (Muqeeth et al., 2023), which softly merges experts in the parameter space; nevertheless, its effectiveness was only demonstrated in downstream fine-tuning on classification tasks. In this paper, we present Lory, the first approach that scales such architectures to autoregressive language model pre-training. Lory introduces two key techniques: (1) a causal segment routing strategy that achieves high efficiency for expert merging operations while preserving the autoregressive nature of language models; (2) a similarity-based data batching method that encourages expert specialization by grouping similar documents in training instances. We pre-train a series of Lory models on 150B tokens from scratch, with up to 32 experts and 30B (1.5B active) parameters. Experimental results show significant performance gains over parameter-matched dense models on both perplexity (+13.9%) and a variety of downstream tasks (+1.5%-11.1%). Despite segment-level routing, Lory models achieve competitive performance compared to state-of-the-art MoE models with token-level routing. We further demonstrate that the trained experts in Lory capture domain-level specialization without supervision. Our work highlights the potential of fully-differentiable MoE architectures for language model pre-training and advocates future research in this area.
Reliable, Adaptable, and Attributable Language Models with Retrieval
Mar 05, 2024



Parametric language models (LMs), which are trained on vast amounts of web data, exhibit remarkable flexibility and capability. However, they still face practical challenges such as hallucinations, difficulty in adapting to new data distributions, and a lack of verifiability. In this position paper, we advocate for retrieval-augmented LMs to replace parametric LMs as the next generation of LMs. By incorporating large-scale datastores during inference, retrieval-augmented LMs can be more reliable, adaptable, and attributable. Despite their potential, retrieval-augmented LMs have yet to be widely adopted due to several obstacles: specifically, current retrieval-augmented LMs struggle to leverage helpful text beyond knowledge-intensive tasks such as question answering, have limited interaction between retrieval and LM components, and lack the infrastructure for scaling. To address these, we propose a roadmap for developing general-purpose retrieval-augmented LMs. This involves a reconsideration of datastores and retrievers, the exploration of pipelines with improved retriever-LM interaction, and significant investment in infrastructure for efficient training and inference.
REST: Retrieval-Based Speculative Decoding
Nov 14, 2023



We introduce Retrieval-Based Speculative Decoding (REST), a novel algorithm designed to speed up language model generation. The key insight driving the development of REST is the observation that the process of text generation often includes certain common phases and patterns. Unlike previous methods that rely on a draft language model for speculative decoding, REST harnesses the power of retrieval to generate draft tokens. This method draws from the reservoir of existing knowledge, retrieving and employing relevant tokens based on the current context. Its plug-and-play nature allows for seamless integration and acceleration of any language models, all without necessitating additional training. When benchmarked on 7B and 13B language models in a single-batch setting, REST achieves a significant speedup of 1.62X to 2.36X on code or text generation. The code of REST is available at https://github.com/FasterDecoding/REST.
Poisoning Retrieval Corpora by Injecting Adversarial Passages
Oct 29, 2023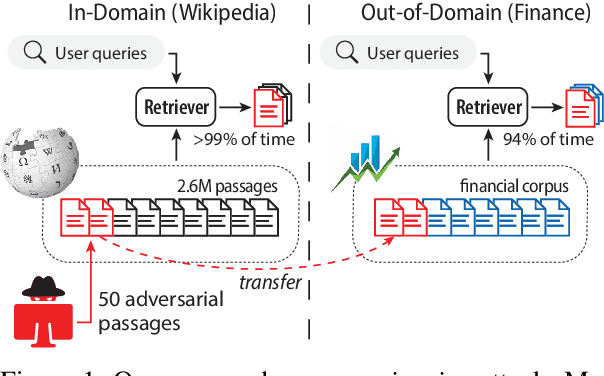
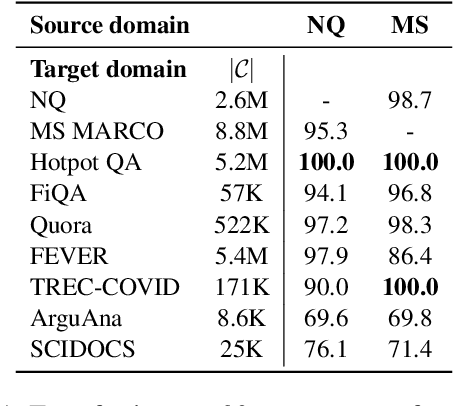
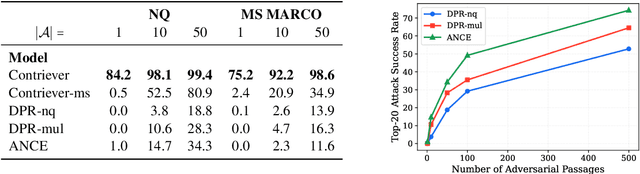
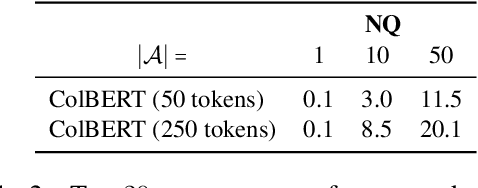
Dense retrievers have achieved state-of-the-art performance in various information retrieval tasks, but to what extent can they be safely deployed in real-world applications? In this work, we propose a novel attack for dense retrieval systems in which a malicious user generates a small number of adversarial passages by perturbing discrete tokens to maximize similarity with a provided set of training queries. When these adversarial passages are inserted into a large retrieval corpus, we show that this attack is highly effective in fooling these systems to retrieve them for queries that were not seen by the attacker. More surprisingly, these adversarial passages can directly generalize to out-of-domain queries and corpora with a high success attack rate -- for instance, we find that 50 generated passages optimized on Natural Questions can mislead >94% of questions posed in financial documents or online forums. We also benchmark and compare a range of state-of-the-art dense retrievers, both unsupervised and supervised. Although different systems exhibit varying levels of vulnerability, we show they can all be successfully attacked by injecting up to 500 passages, a small fraction compared to a retrieval corpus of millions of passages.
MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions
May 24, 2023The information stored in large language models (LLMs) falls out of date quickly, and retraining from scratch is often not an option. This has recently given rise to a range of techniques for injecting new facts through updating model weights. Current evaluation paradigms are extremely limited, mainly validating the recall of edited facts, but changing one fact should cause rippling changes to the model's related beliefs. If we edit the UK Prime Minister to now be Rishi Sunak, then we should get a different answer to Who is married to the British Prime Minister? In this work, we present a benchmark MQuAKE (Multi-hop Question Answering for Knowledge Editing) comprising multi-hop questions that assess whether edited models correctly answer questions where the answer should change as an entailed consequence of edited facts. While we find that current knowledge-editing approaches can recall edited facts accurately, they fail catastrophically on the constructed multi-hop questions. We thus propose a simple memory-based approach, MeLLo, which stores all edited facts externally while prompting the language model iteratively to generate answers that are consistent with the edited facts. While MQuAKE remains challenging, we show that MeLLo scales well with LLMs (up to 175B) and outperforms previous model editors by a large margin.
Privacy Implications of Retrieval-Based Language Models
May 24, 2023



Retrieval-based language models (LMs) have demonstrated improved interpretability, factuality, and adaptability compared to their parametric counterparts, by incorporating retrieved text from external datastores. While it is well known that parametric models are prone to leaking private data, it remains unclear how the addition of a retrieval datastore impacts model privacy. In this work, we present the first study of privacy risks in retrieval-based LMs, particularly $k$NN-LMs. Our goal is to explore the optimal design and training procedure in domains where privacy is of concern, aiming to strike a balance between utility and privacy. Crucially, we find that $k$NN-LMs are more susceptible to leaking private information from their private datastore than parametric models. We further explore mitigations of privacy risks. When privacy information is targeted and readily detected in the text, we find that a simple sanitization step would completely eliminate the risks, while decoupling query and key encoders achieves an even better utility-privacy trade-off. Otherwise, we consider strategies of mixing public and private data in both datastore and encoder training. While these methods offer modest improvements, they leave considerable room for future work. Together, our findings provide insights for practitioners to better understand and mitigate privacy risks in retrieval-based LMs. Our code is available at: https://github.com/Princeton-SysML/kNNLM_privacy .
$k$NN-Adapter: Efficient Domain Adaptation for Black-Box Language Models
Feb 21, 2023



Fine-tuning a language model on a new domain is standard practice for domain adaptation. However, it can be infeasible when it comes to modern large-scale language models such as GPT-3, which can only be accessed through APIs, making it difficult to access the internal parameters of the model. In this paper, we propose $k$NN-Adapter, a method to effectively adapt these black-box large language models (LLMs) to a new domain. The $k$NN-Adapter builds on top of the retrieval-augmented language model, and adaptively learns to interpolate the output of the language model with retrieval results from a datastore consisting of the target domain data. Our experiments on four different domains demonstrate that $k$NN-Adapter significantly improves perplexity, and works particularly well in settings with limited access to LLMs. Additionally, we show that $k$NN-Adapter is more effective than fine-tuning when the amount of training data is limited. We also release a dataset to encourage further study.
Training Language Models with Memory Augmentation
May 25, 2022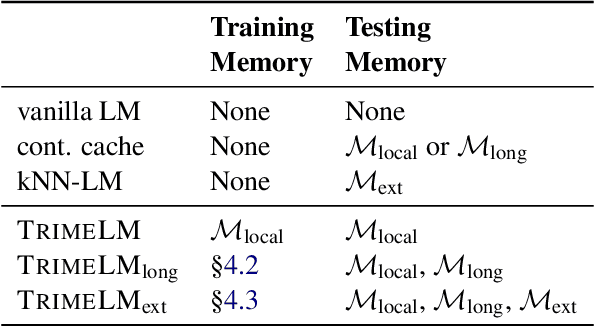
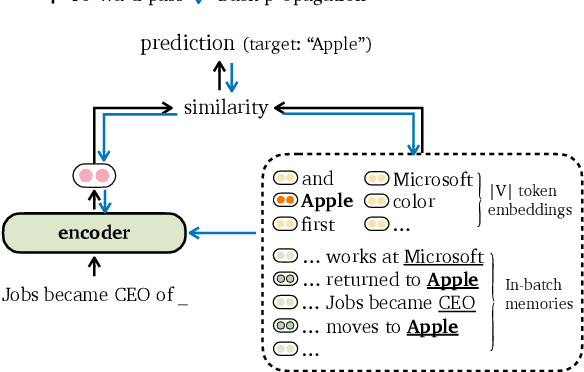
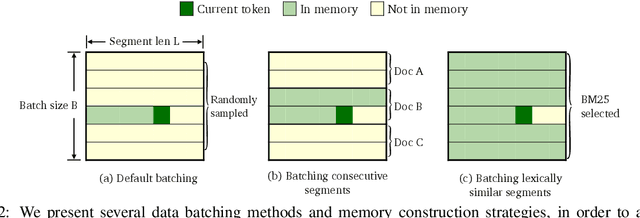
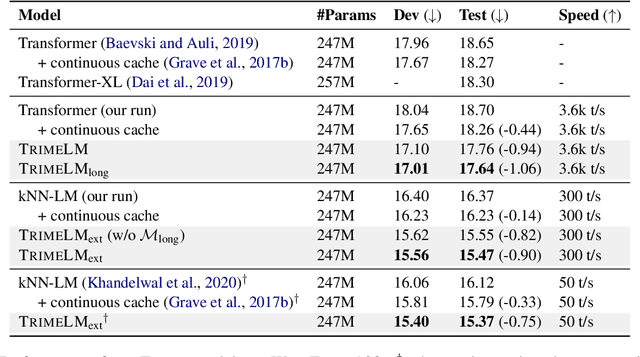
Recent work has improved language models remarkably by equipping them with a non-parametric memory component. However, most existing approaches only introduce memories at testing time, or represent them using a separately trained encoder -- resulting in sub-optimal training of the language model. In this work, we present TRIME, a novel yet simple training approach designed for training language models with memory augmentation. Our approach uses a training objective that directly takes in-batch examples as accessible memory. We also present new methods for memory construction and data batching, which are used for adapting to different sets of memories -- local, long-term, and external memory -- at testing time. We evaluate our approach on multiple language modeling and machine translation benchmarks. We find that simply replacing the vanilla language modeling objective by ours greatly reduces the perplexity, without modifying the model architecture or incorporating extra context (e.g., 18.70 $\to$ 17.76 on WikiText-103). We further augment language models with long-range contexts and external knowledge and demonstrate significant gains over previous memory-augmented approaches.