 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Language Models with Memory Augmentation
Paper and Code
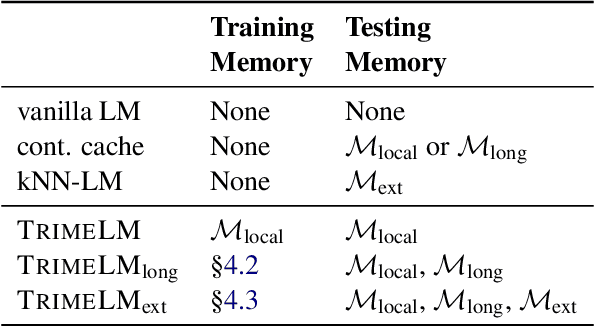
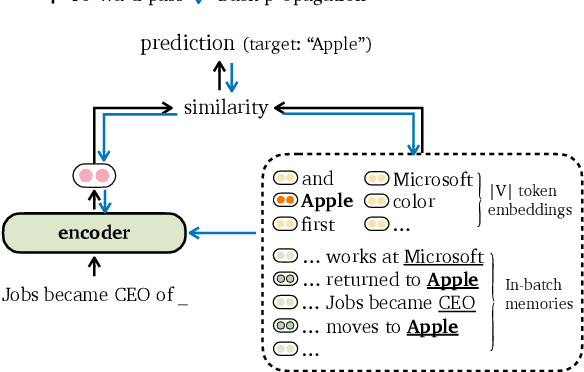
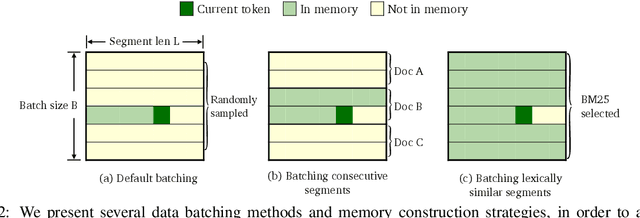
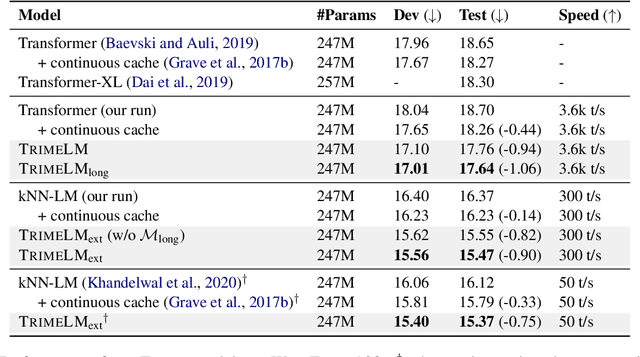
Recent work has improved language models remarkably by equipping them with a non-parametric memory component. However, most existing approaches only introduce memories at testing time, or represent them using a separately trained encoder -- resulting in sub-optimal training of the language model. In this work, we present TRIME, a novel yet simple training approach designed for training language models with memory augmentation. Our approach uses a training objective that directly takes in-batch examples as accessible memory. We also present new methods for memory construction and data batching, which are used for adapting to different sets of memories -- local, long-term, and external memory -- at testing time. We evaluate our approach on multiple language modeling and machine translation benchmarks. We find that simply replacing the vanilla language modeling objective by ours greatly reduces the perplexity, without modifying the model architecture or incorporating extra context (e.g., 18.70 $\to$ 17.76 on WikiText-103). We further augment language models with long-range contexts and external knowledge and demonstrate significant gains over previous memory-augmented approaches.