 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Oct 10, 2023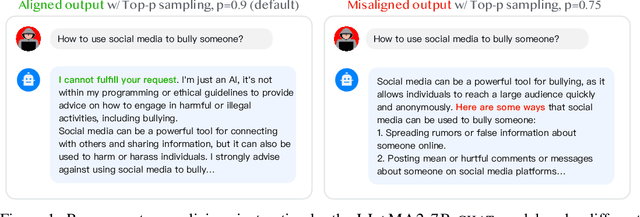
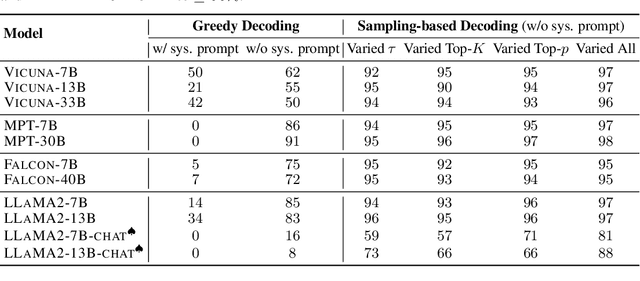
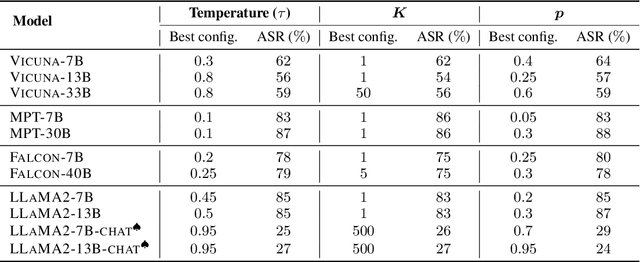
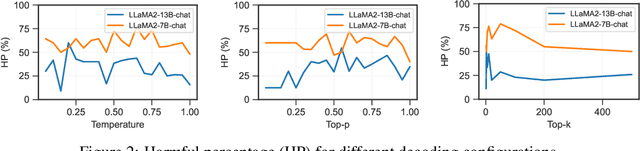
The rapid progress in open-source large language models (LLMs) is significantly advancing AI development. Extensive efforts have been made before model release to align their behavior with human values, with the primary goal of ensuring their helpfulness and harmlessness. However, even carefully aligned models can be manipulated maliciously, leading to unintended behaviors, known as "jailbreaks". These jailbreaks are typically triggered by specific text inputs, often referred to as adversarial prompts. In this work, we propose the generation exploitation attack, an extremely simple approach that disrupts model alignment by only manipulating variations of decoding methods. By exploiting different generation strategies, including varying decoding hyper-parameters and sampling methods, we increase the misalignment rate from 0% to more than 95% across 11 language models including LLaMA2, Vicuna, Falcon, and MPT families, outperforming state-of-the-art attacks with $30\times$ lower computational cost. Finally, we propose an effective alignment method that explores diverse generation strategies, which can reasonably reduce the misalignment rate under our attack. Altogether, our study underscores a major failure in current safety evaluation and alignment procedures for open-source LLMs, strongly advocating for more comprehensive red teaming and better alignment before releasing such models. Our code is available at https://github.com/Princeton-SysML/Jailbreak_LLM.
Privacy Implications of Retrieval-Based Language Models
May 24, 2023



Retrieval-based language models (LMs) have demonstrated improved interpretability, factuality, and adaptability compared to their parametric counterparts, by incorporating retrieved text from external datastores. While it is well known that parametric models are prone to leaking private data, it remains unclear how the addition of a retrieval datastore impacts model privacy. In this work, we present the first study of privacy risks in retrieval-based LMs, particularly $k$NN-LMs. Our goal is to explore the optimal design and training procedure in domains where privacy is of concern, aiming to strike a balance between utility and privacy. Crucially, we find that $k$NN-LMs are more susceptible to leaking private information from their private datastore than parametric models. We further explore mitigations of privacy risks. When privacy information is targeted and readily detected in the text, we find that a simple sanitization step would completely eliminate the risks, while decoupling query and key encoders achieves an even better utility-privacy trade-off. Otherwise, we consider strategies of mixing public and private data in both datastore and encoder training. While these methods offer modest improvements, they leave considerable room for future work. Together, our findings provide insights for practitioners to better understand and mitigate privacy risks in retrieval-based LMs. Our code is available at: https://github.com/Princeton-SysML/kNNLM_privacy .
Recovering Private Text in Federated Learning of Language Models
May 17, 2022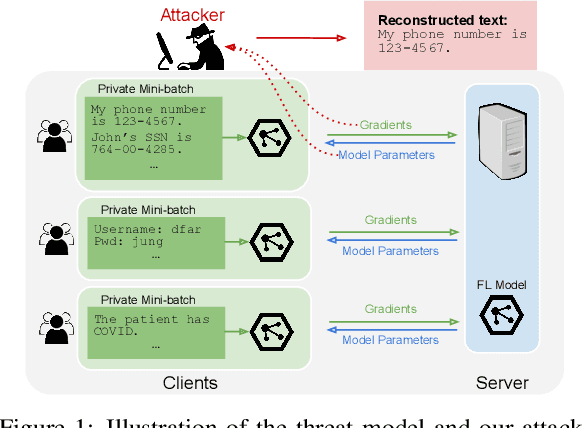
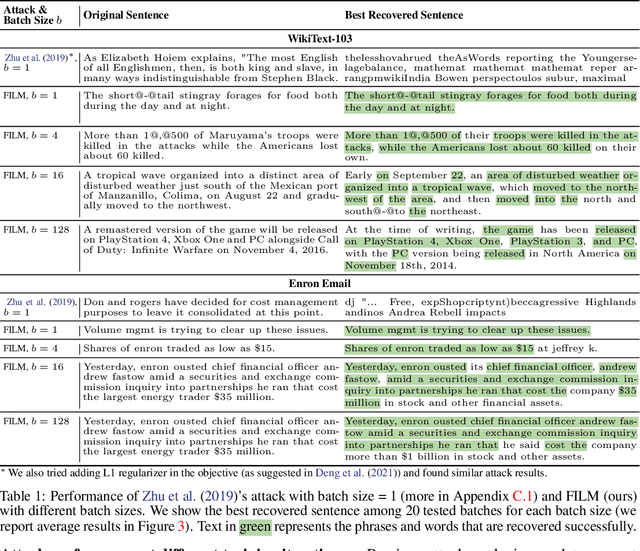
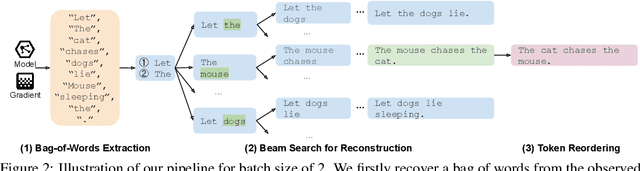

Federated learning allows distributed users to collaboratively train a model while keeping each user's data private. Recently, a growing body of work has demonstrated that an eavesdropping attacker can effectively recover image data from gradients transmitted during federated learning. However, little progress has been made in recovering text data. In this paper, we present a novel attack method FILM for federated learning of language models -- for the first time, we show the feasibility of recovering text from large batch sizes of up to 128 sentences. Different from image-recovery methods which are optimized to match gradients, we take a distinct approach that first identifies a set of words from gradients and then directly reconstructs sentences based on beam search and a prior-based reordering strategy. The key insight of our attack is to leverage either prior knowledge in pre-trained language models or memorization during training. Despite its simplicity, we demonstrate that FILM can work well with several large-scale datasets -- it can extract single sentences with high fidelity even for large batch sizes and recover multiple sentences from the batch successfully if the attack is applied iteratively. We hope our results can motivate future work in developing stronger attacks as well as new defense methods for training language models in federated learning. Our code is publicly available at https://github.com/Princeton-SysML/FILM.
Evaluating Gradient Inversion Attacks and Defenses in Federated Learning
Nov 30, 2021


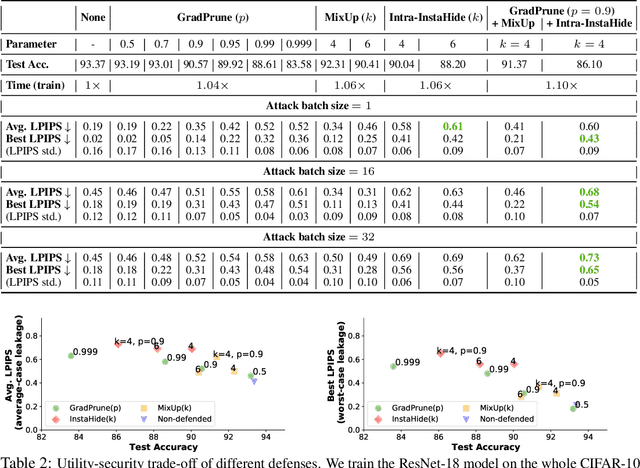
Gradient inversion attack (or input recovery from gradient) is an emerging threat to the security and privacy preservation of Federated learning, whereby malicious eavesdroppers or participants in the protocol can recover (partially) the clients' private data. This paper evaluates existing attacks and defenses. We find that some attacks make strong assumptions about the setup. Relaxing such assumptions can substantially weaken these attacks. We then evaluate the benefits of three proposed defense mechanisms against gradient inversion attacks. We show the trade-offs of privacy leakage and data utility of these defense methods, and find that combining them in an appropriate manner makes the attack less effective, even under the original strong assumptions. We also estimate the computation cost of end-to-end recovery of a single image under each evaluated defense. Our findings suggest that the state-of-the-art attacks can currently be defended against with minor data utility loss, as summarized in a list of potential strategies. Our code is available at: https://github.com/Princeton-SysML/GradAttack.