 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirrorCBO: A consensus-based optimization method in the spirit of mirror descent
Jan 21, 2025



In this work we propose MirrorCBO, a consensus-based optimization (CBO) method which generalizes standard CBO in the same way that mirror descent generalizes gradient descent. For this we apply the CBO methodology to a swarm of dual particles and retain the primal particle positions by applying the inverse of the mirror map, which we parametrize as the subdifferential of a strongly convex function $\phi$. In this way, we combine the advantages of a derivative-free non-convex optimization algorithm with those of mirror descent. As a special case, the method extends CBO to optimization problems with convex constraints. Assuming bounds on the Bregman distance associated to $\phi$, we provide asymptotic convergence results for MirrorCBO with explicit exponential rate. Another key contribution is an exploratory numerical study of this new algorithm across different application settings, focusing on (i) sparsity-inducing optimization, and (ii) constrained optimization, demonstrating the competitive performance of MirrorCBO. We observe empirically that the method can also be used for optimization on (non-convex) submanifolds of Euclidean space, can be adapted to mirrored versions of other recent CBO variants, and that it inherits from mirror descent the capability to select desirable minimizers, like sparse ones. We also include an overview of recent CBO approaches for constrained optimization and compare their performance to MirrorCBO.
Graph Laplacian-based Bayesian Multi-fidelity Modeling
Sep 12, 2024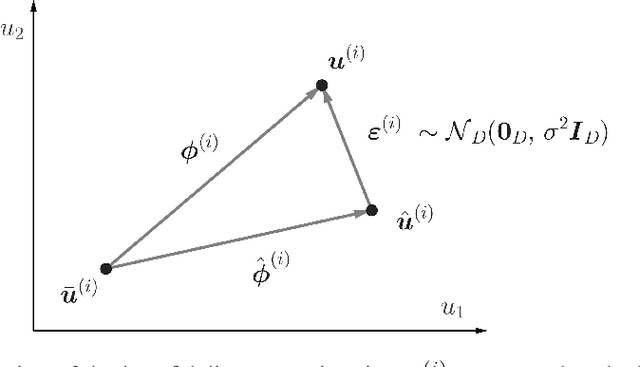


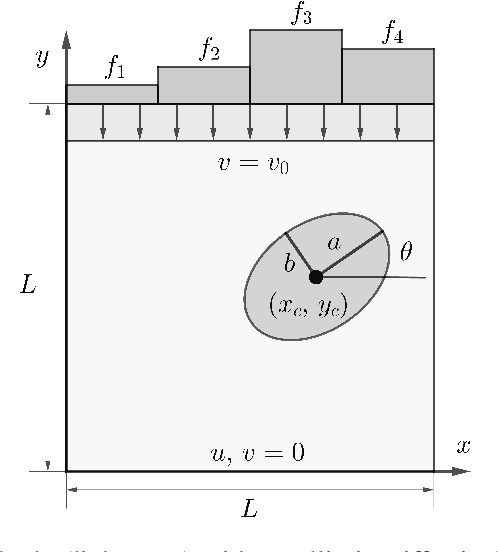
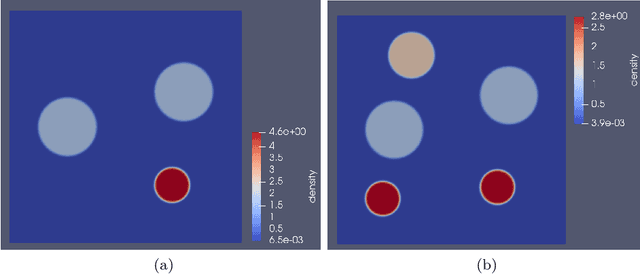
We present a novel probabilistic approach for generating multi-fidelity data while accounting for errors inherent in both low- and high-fidelity data. In this approach a graph Laplacian constructed from the low-fidelity data is used to define a multivariate Gaussian prior density for the coordinates of the true data points. In addition, few high-fidelity data points are used to construct a conjugate likelihood term. Thereafter, Bayes rule is applied to derive an explicit expression for the posterior density which is also multivariate Gaussian. The maximum \textit{a posteriori} (MAP) estimate of this density is selected to be the optimal multi-fidelity estimate. It is shown that the MAP estimate and the covariance of the posterior density can be determined through the solution of linear systems of equations. Thereafter, two methods, one based on spectral truncation and another based on a low-rank approximation, are developed to solve these equations efficiently. The multi-fidelity approach is tested on a variety of problems in solid and fluid mechanics with data that represents vectors of quantities of interest and discretized spatial fields in one and two dimensions. The results demonstrate that by utilizing a small fraction of high-fidelity data, the multi-fidelity approach can significantly improve the accuracy of a large collection of low-fidelity data points.
Coupled Gradient Flows for Strategic Non-Local Distribution Shift
Jul 07, 2023We propose a novel framework for analyzing the dynamics of distribution shift in real-world systems that captures the feedback loop between learning algorithms and the distributions on which they are deployed. Prior work largely models feedback-induced distribution shift as adversarial or via an overly simplistic distribution-shift structure. In contrast, we propose a coupled partial differential equation model that captures fine-grained changes in the distribution over time by accounting for complex dynamics that arise due to strategic responses to algorithmic decision-making, non-local endogenous population interactions, and other exogenous sources of distribution shift. We consider two common settings in machine learning: cooperative settings with information asymmetries, and competitive settings where a learner faces strategic users. For both of these settings, when the algorithm retrains via gradient descent, we prove asymptotic convergence of the retraining procedure to a steady-state, both in finite and in infinite dimensions, obtaining explicit rates in terms of the model parameters. To do so we derive new results on the convergence of coupled PDEs that extends what is known on multi-species systems. Empirically, we show that our approach captures well-documented forms of distribution shifts like polarization and disparate impacts that simpler models cannot capture.
Bayesian Posterior Perturbation Analysis with Integral Probability Metrics
Mar 02, 2023In recent years, Bayesian inference in large-scale inverse problems found in science, engineering and machine learning has gained significant attention. This paper examines the robustness of the Bayesian approach by analyzing the stability of posterior measures in relation to perturbations in the likelihood potential and the prior measure. We present new stability results using a family of integral probability metrics (divergences) akin to dual problems that arise in optimal transport. Our results stand out from previous works in three directions: (1) We construct new families of integral probability metrics that are adapted to the problem at hand; (2) These new metrics allow us to study both likelihood and prior perturbations in a convenient way; and (3) our analysis accommodates likelihood potentials that are only locally Lipschitz, making them applicable to a wide range of nonlinear inverse problems. Our theoretical findings are further reinforced through specific and novel examples where the approximation rates of posterior measures are obtained for different types of perturbations and provide a path towards the convergence analysis of recently adapted machine learning techniques for Bayesian inverse problems such as data-driven priors and neural network surrogates.
Spectral Analysis Of Weighted Laplacians Arising In Data Clustering
Sep 13, 2019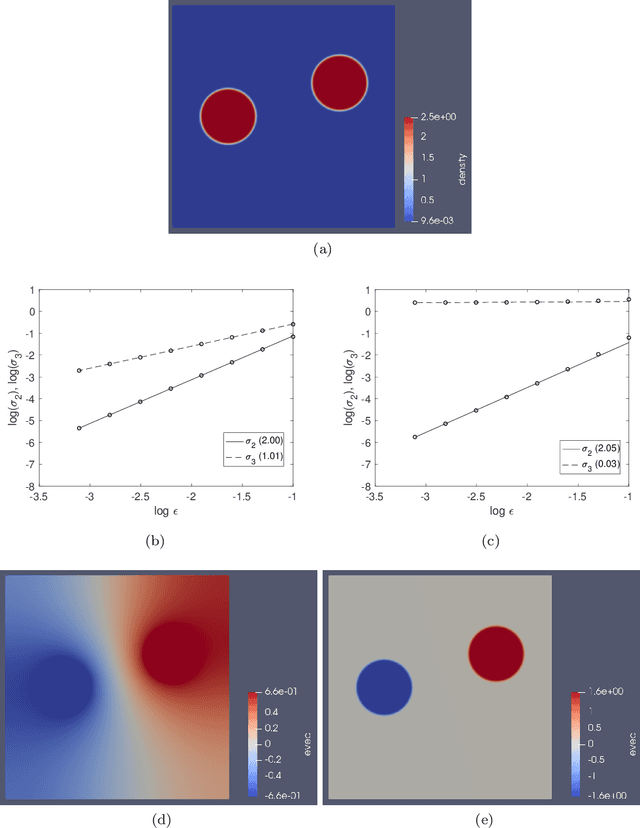
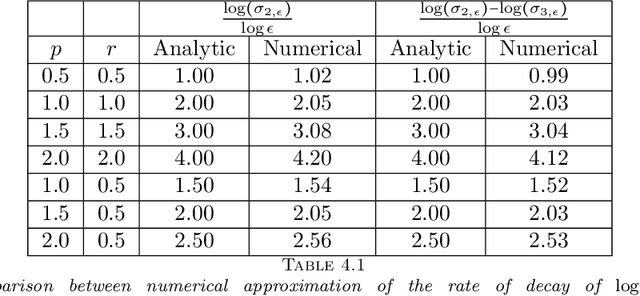
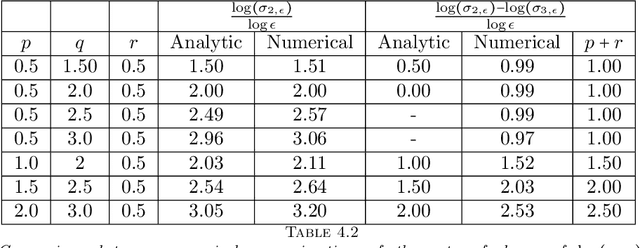
Graph Laplacians computed from weighted adjacency matrices are widely used to identify geometric structure in data, and clusters in particular; their spectral properties play a central role in a number of unsupervised and semi-supervised learning algorithms. When suitably scaled, graph Laplacians approach limiting continuum operators in the large data limit. Studying these limiting operators, therefore, sheds light on learning algorithms. This paper is devoted to the study of a parameterized family of divergence form elliptic operators that arise as the large data limit of graph Laplacians. The link between a three-parameter family of graph Laplacians and a three-parameter family of differential operators is explained. The spectral properties of these differential perators are analyzed in the situation where the data comprises two nearly separated clusters, in a sense which is made precise. In particular, we investigate how the spectral gap depends on the three parameters entering the graph Laplacian and on a parameter measuring the size of the perturbation from the perfectly clustered case. Numerical results are presented which exemplify and extend the analysis; in particular the computations study situations with more than two clusters. The findings provide insight into parameter choices made in learning algorithms which are based on weighted adjacency matrices; they also provide the basis for analysis of the consistency of various unsupervised and semi-supervised learning algorithms, in the large data limit.
Consistency of semi-supervised learning algorithms on graphs: Probit and one-hot methods
Jun 18, 2019



Graph-based semi-supervised learning is the problem of propagating labels from a small number of labelled data points to a larger set of unlabelled data. This paper is concerned with the consistency of optimization-based techniques for such problems, in the limit where the labels have small noise and the underlying unlabelled data is well clustered. We study graph-based probit for binary classification, and a natural generalization of this method to multi-class classification using one-hot encoding. The resulting objective function to be optimized comprises the sum of a quadratic form defined through a rational function of the graph Laplacian, involving only the unlabelled data, and a fidelity term involving only the labelled data. The consistency analysis sheds light on the choice of the rational function defining the optimization.
Geometric structure of graph Laplacian embeddings
Jan 30, 2019

We analyze the spectral clustering procedure for identifying coarse structure in a data set $x_1, \dots, x_n$, and in particular study the geometry of graph Laplacian embeddings which form the basis for spectral clustering algorithms. More precisely, we assume that the data is sampled from a mixture model supported on a manifold $\mathcal{M}$ embedded in $\mathbb{R}^d$, and pick a connectivity length-scale $\varepsilon>0$ to construct a kernelized graph Laplacian. We introduce a notion of a well-separated mixture model which only depends on the model itself, and prove that when the model is well separated, with high probability the embedded data set concentrates on cones that are centered around orthogonal vectors. Our results are meaningful in the regime where $\varepsilon = \varepsilon(n)$ is allowed to decay to zero at a slow enough rate as the number of data points grows. This rate depends on the intrinsic dimension of the manifold on which the data is supported.