 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn optimal Petrov-Galerkin framework for operator networks
Mar 06, 2025The optimal Petrov-Galerkin formulation to solve partial differential equations (PDEs) recovers the best approximation in a specified finite-dimensional (trial) space with respect to a suitable norm. However, the recovery of this optimal solution is contingent on being able to construct the optimal weighting functions associated with the trial basis. While explicit constructions are available for simple one- and two-dimensional problems, such constructions for a general multidimensional problem remain elusive. In the present work, we revisit the optimal Petrov-Galerkin formulation through the lens of deep learning. We propose an operator network framework called Petrov-Galerkin Variationally Mimetic Operator Network (PG-VarMiON), which emulates the optimal Petrov-Galerkin weak form of the underlying PDE. The PG-VarMiON is trained in a supervised manner using a labeled dataset comprising the PDE data and the corresponding PDE solution, with the training loss depending on the choice of the optimal norm. The special architecture of the PG-VarMiON allows it to implicitly learn the optimal weighting functions, thus endowing the proposed operator network with the ability to generalize well beyond the training set. We derive approximation error estimates for PG-VarMiON, highlighting the contributions of various error sources, particularly the error in learning the true weighting functions. Several numerical results are presented for the advection-diffusion equation to demonstrate the efficacy of the proposed method. By embedding the Petrov-Galerkin structure into the network architecture, PG-VarMiON exhibits greater robustness and improved generalization compared to other popular deep operator frameworks, particularly when the training data is limited.
Graph Laplacian-based Bayesian Multi-fidelity Modeling
Sep 12, 2024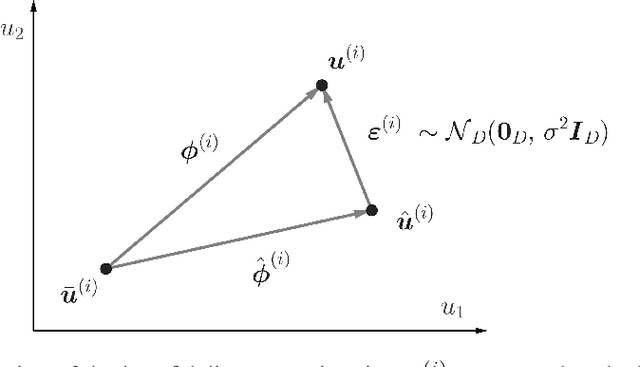


We present a novel probabilistic approach for generating multi-fidelity data while accounting for errors inherent in both low- and high-fidelity data. In this approach a graph Laplacian constructed from the low-fidelity data is used to define a multivariate Gaussian prior density for the coordinates of the true data points. In addition, few high-fidelity data points are used to construct a conjugate likelihood term. Thereafter, Bayes rule is applied to derive an explicit expression for the posterior density which is also multivariate Gaussian. The maximum \textit{a posteriori} (MAP) estimate of this density is selected to be the optimal multi-fidelity estimate. It is shown that the MAP estimate and the covariance of the posterior density can be determined through the solution of linear systems of equations. Thereafter, two methods, one based on spectral truncation and another based on a low-rank approximation, are developed to solve these equations efficiently. The multi-fidelity approach is tested on a variety of problems in solid and fluid mechanics with data that represents vectors of quantities of interest and discretized spatial fields in one and two dimensions. The results demonstrate that by utilizing a small fraction of high-fidelity data, the multi-fidelity approach can significantly improve the accuracy of a large collection of low-fidelity data points.
Solution of physics-based inverse problems using conditional generative adversarial networks with full gradient penalty
Jun 08, 2023The solution of probabilistic inverse problems for which the corresponding forward problem is constrained by physical principles is challenging. This is especially true if the dimension of the inferred vector is large and the prior information about it is in the form of a collection of samples. In this work, a novel deep learning based approach is developed and applied to solving these types of problems. The approach utilizes samples of the inferred vector drawn from the prior distribution and a physics-based forward model to generate training data for a conditional Wasserstein generative adversarial network (cWGAN). The cWGAN learns the probability distribution for the inferred vector conditioned on the measurement and produces samples from this distribution. The cWGAN developed in this work differs from earlier versions in that its critic is required to be 1-Lipschitz with respect to both the inferred and the measurement vectors and not just the former. This leads to a loss term with the full (and not partial) gradient penalty. It is shown that this rather simple change leads to a stronger notion of convergence for the conditional density learned by the cWGAN and a more robust and accurate sampling strategy. Through numerical examples it is shown that this change also translates to better accuracy when solving inverse problems. The numerical examples considered include illustrative problems where the true distribution and/or statistics are known, and a more complex inverse problem motivated by applications in biomechanics.
A few-shot graph Laplacian-based approach for improving the accuracy of low-fidelity data
Mar 29, 2023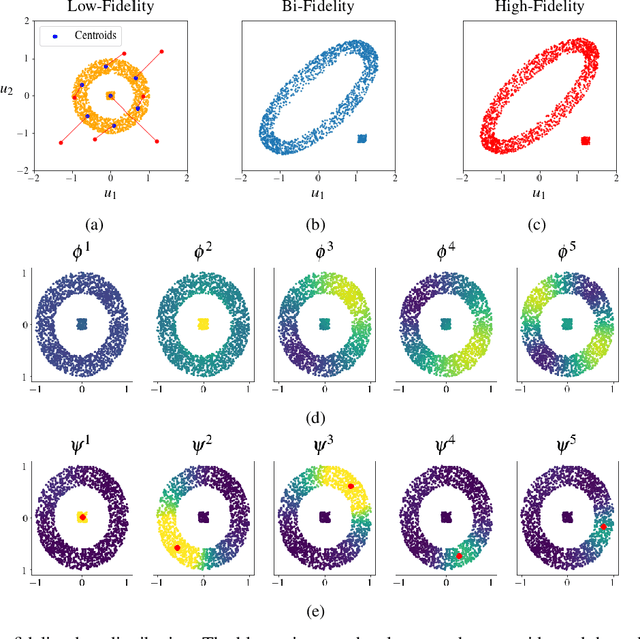

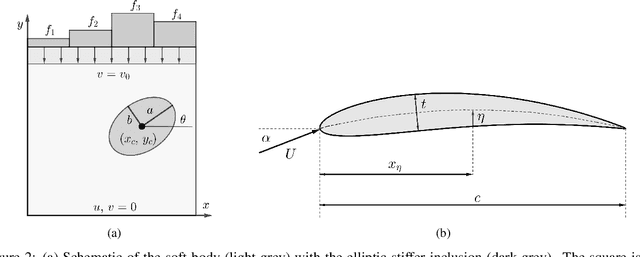

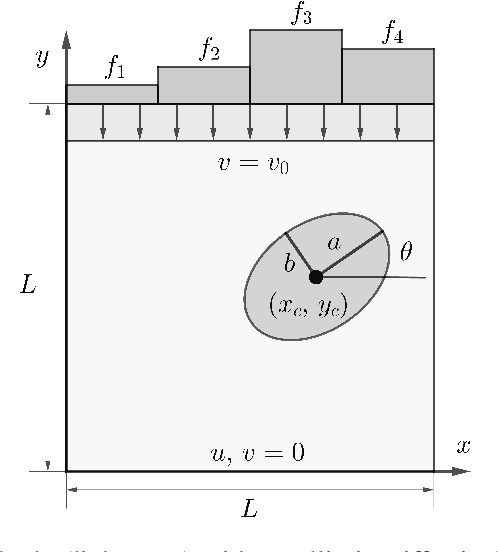
Low-fidelity data is typically inexpensive to generate but inaccurate. On the other hand, high-fidelity data is accurate but expensive to obtain. Multi-fidelity methods use a small set of high-fidelity data to enhance the accuracy of a large set of low-fidelity data. In the approach described in this paper, this is accomplished by constructing a graph Laplacian using the low-fidelity data and computing its low-lying spectrum. This spectrum is then used to cluster the data and identify points that are closest to the centroids of the clusters. High-fidelity data is then acquired for these key points. Thereafter, a transformation that maps every low-fidelity data point to its bi-fidelity counterpart is determined by minimizing the discrepancy between the bi- and high-fidelity data at the key points, and to preserve the underlying structure of the low-fidelity data distribution. The latter objective is achieved by relying, once again, on the spectral properties of the graph Laplacian. This method is applied to a problem in solid mechanics and another in aerodynamics. In both cases, this methods uses a small fraction of high-fidelity data to significantly improve the accuracy of a large set of low-fidelity data.
Deep Learning and Computational Physics (Lecture Notes)
Jan 03, 2023



These notes were compiled as lecture notes for a course developed and taught at the University of the Southern California. They should be accessible to a typical engineering graduate student with a strong background in Applied Mathematics. The main objective of these notes is to introduce a student who is familiar with concepts in linear algebra and partial differential equations to select topics in deep learning. These lecture notes exploit the strong connections between deep learning algorithms and the more conventional techniques of computational physics to achieve two goals. First, they use concepts from computational physics to develop an understanding of deep learning algorithms. Not surprisingly, many concepts in deep learning can be connected to similar concepts in computational physics, and one can utilize this connection to better understand these algorithms. Second, several novel deep learning algorithms can be used to solve challenging problems in computational physics. Thus, they offer someone who is interested in modeling a physical phenomena with a complementary set of tools.
Variationally Mimetic Operator Networks
Sep 26, 2022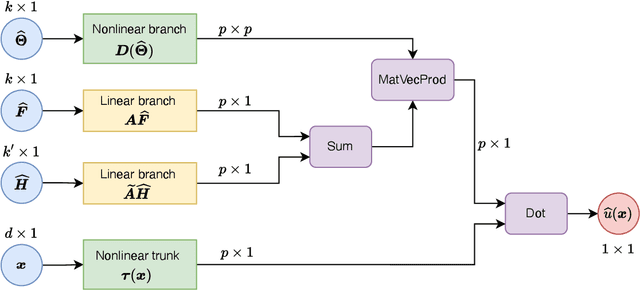

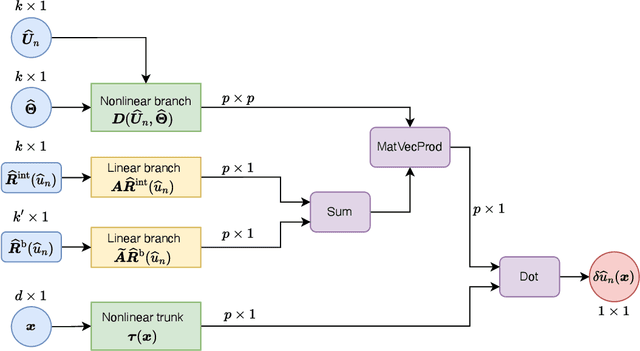
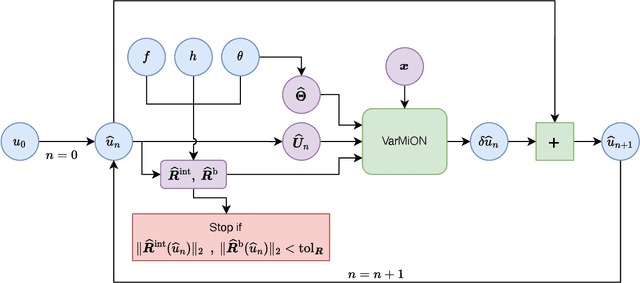
Operator networks have emerged as promising deep learning tools for approximating the solution to partial differential equations (PDEs). These networks map input functions that describe material properties, forcing functions and boundary data to the solution of a PDE. This work describes a new architecture for operator networks that mimics the form of the numerical solution obtained from an approximation of the variational or weak formulation of the problem. The application of these ideas to a generic elliptic PDE leads to a variationally mimetic operator network (VarMiON). Like the conventional Deep Operator Network (DeepONet) the VarMiON is also composed of a sub-network that constructs the basis functions for the output and another that constructs the coefficients for these basis functions. However, in contrast to the DeepONet, in the VarMiON the architecture of these networks is precisely determined. An analysis of the error in the VarMiON solution reveals that it contains contributions from the error in the training data, the training error, quadrature error in sampling input and output functions, and a "covering error" that measures the distance between the test input functions and the nearest functions in the training dataset. It also depends on the stability constants for the exact network and its VarMiON approximation. The application of the VarMiON to a canonical elliptic PDE reveals that for approximately the same number of network parameters, on average the VarMiON incurs smaller errors than a standard DeepONet. Further, its performance is more robust to variations in input functions, the techniques used to sample the input and output functions, the techniques used to construct the basis functions, and the number of input functions.
The efficacy and generalizability of conditional GANs for posterior inference in physics-based inverse problems
Feb 15, 2022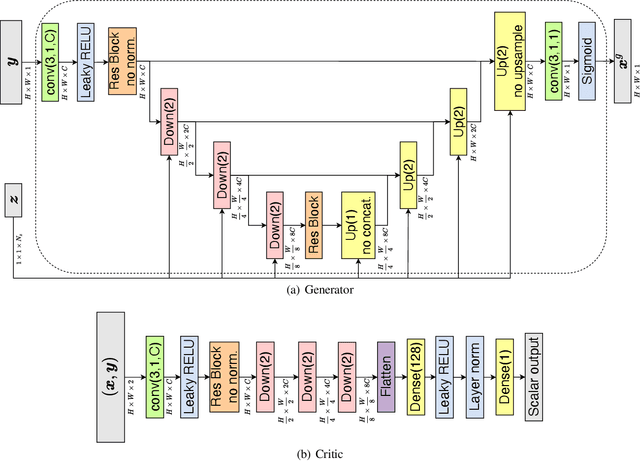
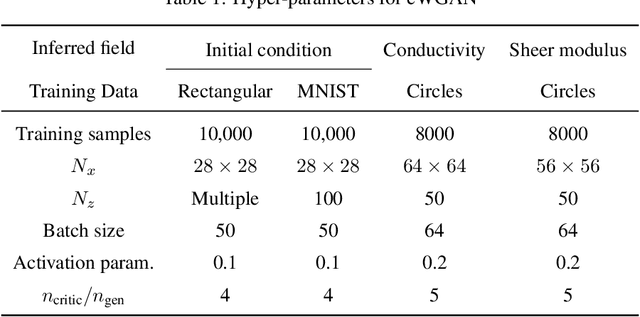
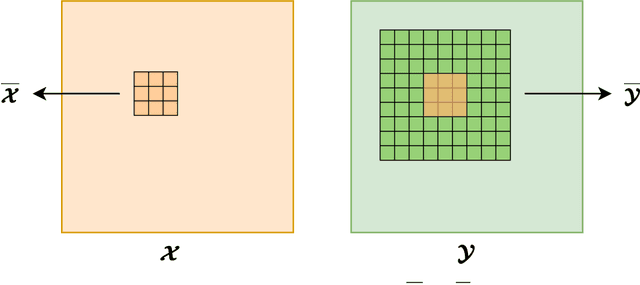
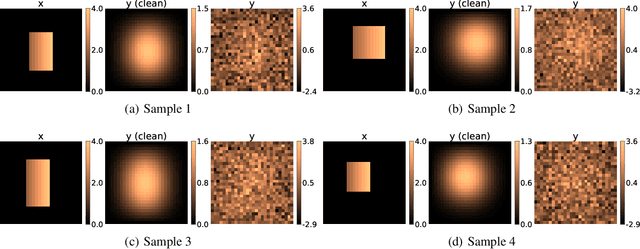
In this work, we train conditional Wasserstein generative adversarial networks to effectively sample from the posterior of physics-based Bayesian inference problems. The generator is constructed using a U-Net architecture, with the latent information injected using conditional instance normalization. The former facilitates a multiscale inverse map, while the latter enables the decoupling of the latent space dimension from the dimension of the measurement, and introduces stochasticity at all scales of the U-Net. We solve PDE-based inverse problems to demonstrate the performance of our approach in quantifying the uncertainty in the inferred field. Further, we show the generator can learn inverse maps which are local in nature, which in turn promotes generalizability when testing with out-of-distribution samples.
GAN-based Priors for Quantifying Uncertainty
Mar 27, 2020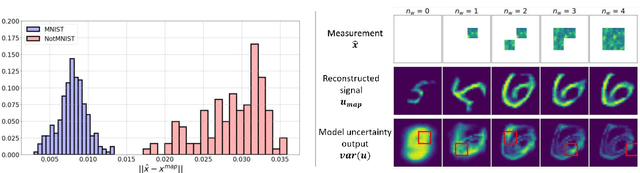
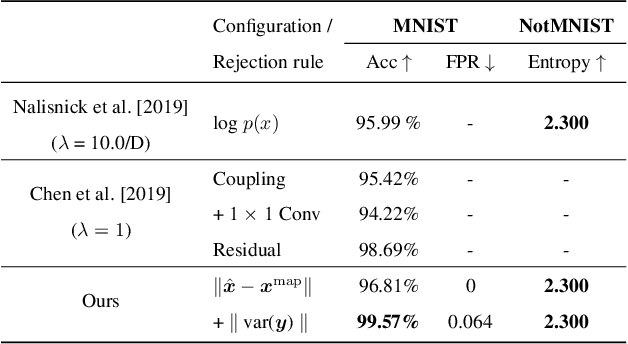
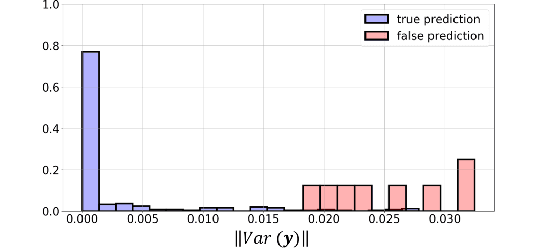
Bayesian inference is used extensively to quantify the uncertainty in an inferred field given the measurement of a related field when the two are linked by a mathematical model. Despite its many applications, Bayesian inference faces challenges when inferring fields that have discrete representations of large dimension, and/or have prior distributions that are difficult to characterize mathematically. In this work we demonstrate how the approximate distribution learned by a deep generative adversarial network (GAN) may be used as a prior in a Bayesian update to address both these challenges. We demonstrate the efficacy of this approach on two distinct, and remarkably broad, classes of problems. The first class leads to supervised learning algorithms for image classification with superior out of distribution detection and accuracy, and for image inpainting with built-in variance estimation. The second class leads to unsupervised learning algorithms for image denoising and for solving physics-driven inverse problems.
Spectral Analysis Of Weighted Laplacians Arising In Data Clustering
Sep 13, 2019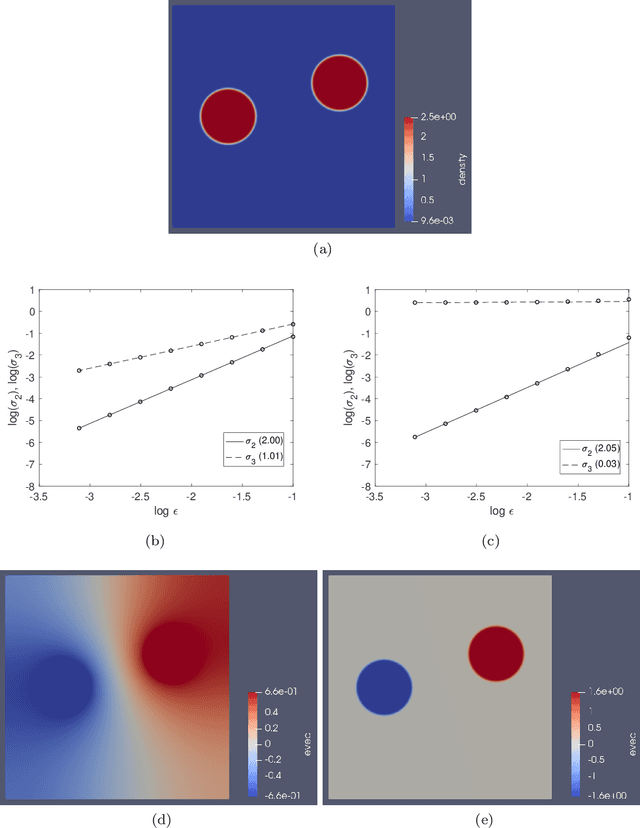
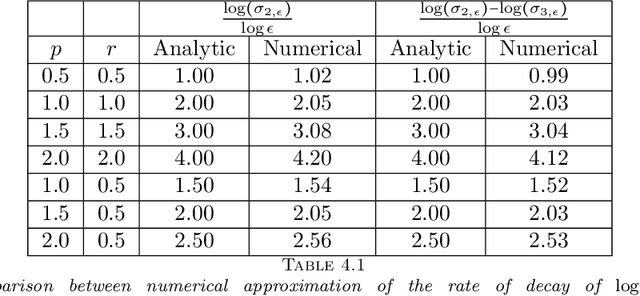
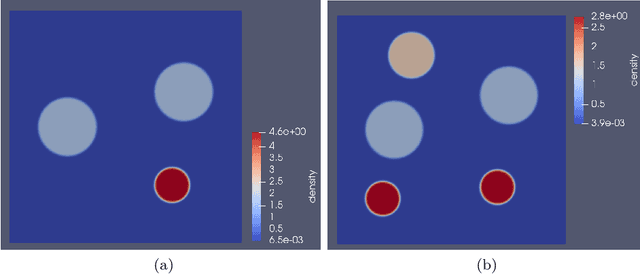
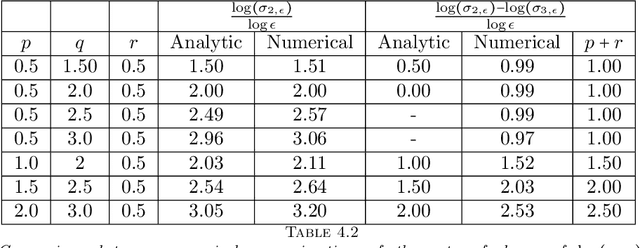
Graph Laplacians computed from weighted adjacency matrices are widely used to identify geometric structure in data, and clusters in particular; their spectral properties play a central role in a number of unsupervised and semi-supervised learning algorithms. When suitably scaled, graph Laplacians approach limiting continuum operators in the large data limit. Studying these limiting operators, therefore, sheds light on learning algorithms. This paper is devoted to the study of a parameterized family of divergence form elliptic operators that arise as the large data limit of graph Laplacians. The link between a three-parameter family of graph Laplacians and a three-parameter family of differential operators is explained. The spectral properties of these differential perators are analyzed in the situation where the data comprises two nearly separated clusters, in a sense which is made precise. In particular, we investigate how the spectral gap depends on the three parameters entering the graph Laplacian and on a parameter measuring the size of the perturbation from the perfectly clustered case. Numerical results are presented which exemplify and extend the analysis; in particular the computations study situations with more than two clusters. The findings provide insight into parameter choices made in learning algorithms which are based on weighted adjacency matrices; they also provide the basis for analysis of the consistency of various unsupervised and semi-supervised learning algorithms, in the large data limit.