 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Inverse Parametrized Problems via Finite Elements and Extreme Learning Networks
Feb 16, 2026We develop an interpolation-based reduced-order modeling framework for parameter-dependent partial differential equations arising in control, inverse problems, and uncertainty quantification. The solution is discretized in the physical domain using finite element methods, while the dependence on a finite-dimensional parameter is approximated separately. We establish existence, uniqueness, and regularity of the parametric solution and derive rigorous error estimates that explicitly quantify the interplay between spatial discretization and parameter approximation. In low-dimensional parameter spaces, classical interpolation schemes yield algebraic convergence rates based on Sobolev regularity in the parameter variable. In higher-dimensional parameter spaces, we replace classical interpolation by extreme learning machine (ELM) surrogates and obtain error bounds under explicit approximation and stability assumptions. The proposed framework is applied to inverse problems in quantitative photoacoustic tomography, where we derive potential and parameter reconstruction error estimates and demonstrate substantial computational savings compared to standard approaches, without sacrificing accuracy.
An optimal Petrov-Galerkin framework for operator networks
Mar 06, 2025The optimal Petrov-Galerkin formulation to solve partial differential equations (PDEs) recovers the best approximation in a specified finite-dimensional (trial) space with respect to a suitable norm. However, the recovery of this optimal solution is contingent on being able to construct the optimal weighting functions associated with the trial basis. While explicit constructions are available for simple one- and two-dimensional problems, such constructions for a general multidimensional problem remain elusive. In the present work, we revisit the optimal Petrov-Galerkin formulation through the lens of deep learning. We propose an operator network framework called Petrov-Galerkin Variationally Mimetic Operator Network (PG-VarMiON), which emulates the optimal Petrov-Galerkin weak form of the underlying PDE. The PG-VarMiON is trained in a supervised manner using a labeled dataset comprising the PDE data and the corresponding PDE solution, with the training loss depending on the choice of the optimal norm. The special architecture of the PG-VarMiON allows it to implicitly learn the optimal weighting functions, thus endowing the proposed operator network with the ability to generalize well beyond the training set. We derive approximation error estimates for PG-VarMiON, highlighting the contributions of various error sources, particularly the error in learning the true weighting functions. Several numerical results are presented for the advection-diffusion equation to demonstrate the efficacy of the proposed method. By embedding the Petrov-Galerkin structure into the network architecture, PG-VarMiON exhibits greater robustness and improved generalization compared to other popular deep operator frameworks, particularly when the training data is limited.
Stabilizing and Solving Inverse Problems using Data and Machine Learning
Dec 05, 2024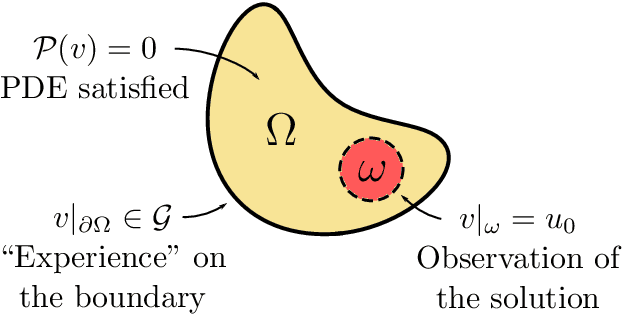

We consider an inverse problem involving the reconstruction of the solution to a nonlinear partial differential equation (PDE) with unknown boundary conditions. Instead of direct boundary data, we are provided with a large dataset of boundary observations for typical solutions (collective data) and a bulk measurement of a specific realization. To leverage this collective data, we first compress the boundary data using proper orthogonal decomposition (POD) in a linear expansion. Next, we identify a possible nonlinear low-dimensional structure in the expansion coefficients using an auto-encoder, which provides a parametrization of the dataset in a lower-dimensional latent space. We then train a neural network to map the latent variables representing the boundary data to the solution of the PDE. Finally, we solve the inverse problem by optimizing a data-fitting term over the latent space. We analyze the underlying stabilized finite element method in the linear setting and establish optimal error estimates in the $H^1$ and $L^2$-norms. The nonlinear problem is then studied numerically, demonstrating the effectiveness of our approach.
Nonlinear Operator Learning Using Energy Minimization and MLPs
Dec 05, 2024

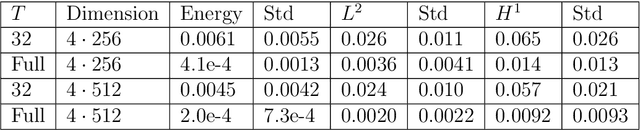
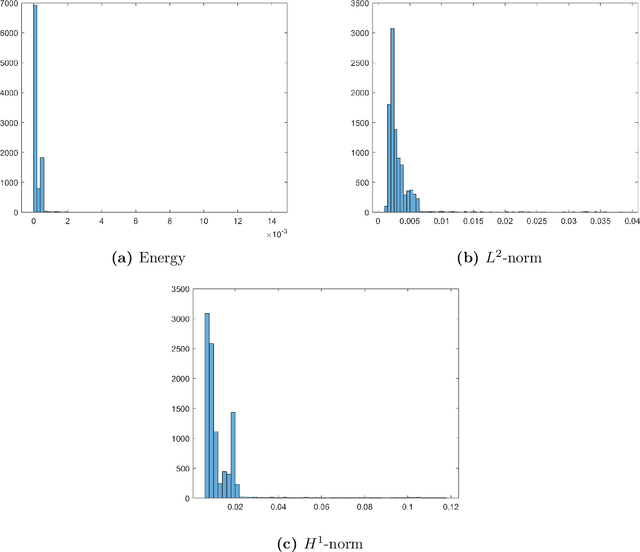
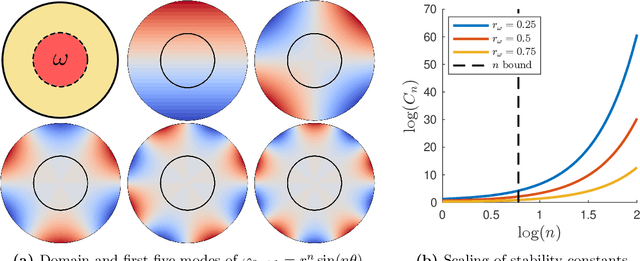
We develop and evaluate a method for learning solution operators to nonlinear problems governed by partial differential equations. The approach is based on a finite element discretization and aims at representing the solution operator by an MLP that takes latent variables as input. The latent variables will typically correspond to parameters in a parametrization of input data such as boundary conditions, coefficients, and right-hand sides. The loss function is most often an energy functional and we formulate efficient parallelizable training algorithms based on assembling the energy locally on each element. For large problems, the learning process can be made more efficient by using only a small fraction of randomly chosen elements in the mesh in each iteration. The approach is evaluated on several relevant test cases, where learning the solution operator turns out to be beneficial compared to classical numerical methods.
Implicit Hypersurface Approximation Capacity in Deep ReLU Networks
Jul 04, 2024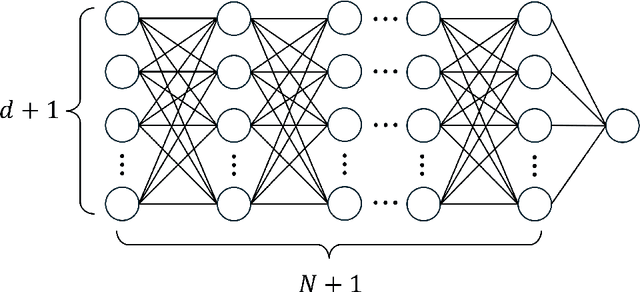
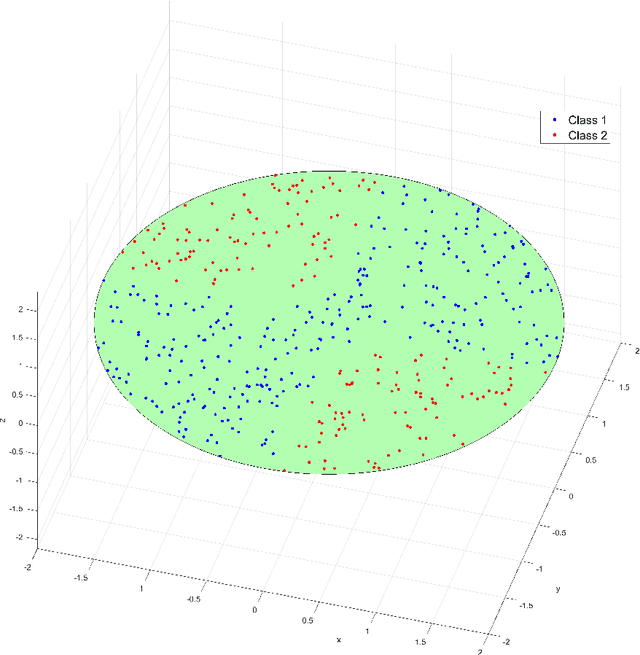
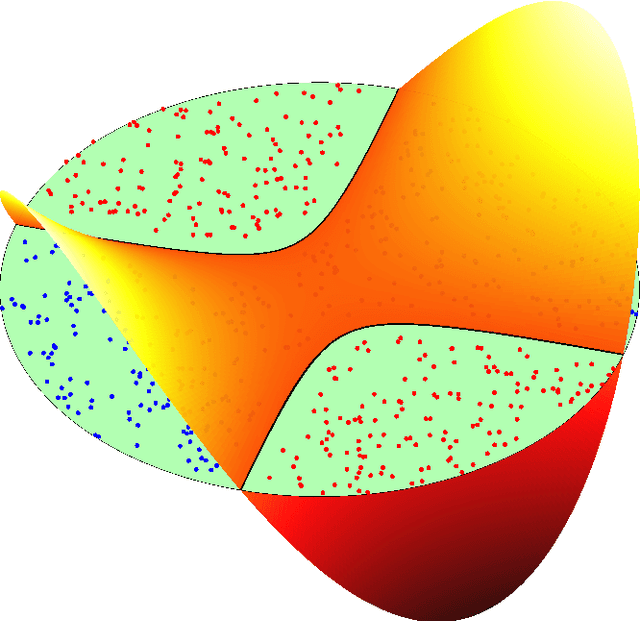

We develop a geometric approximation theory for deep feed-forward neural networks with ReLU activations. Given a $d$-dimensional hypersurface in $\mathbb{R}^{d+1}$ represented as the graph of a $C^2$-function $\phi$, we show that a deep fully-connected ReLU network of width $d+1$ can implicitly construct an approximation as its zero contour with a precision bound depending on the number of layers. This result is directly applicable to the binary classification setting where the sign of the network is trained as a classifier, with the network's zero contour as a decision boundary. Our proof is constructive and relies on the geometrical structure of ReLU layers provided in [doi:10.48550/arXiv.2310.03482]. Inspired by this geometrical description, we define a new equivalent network architecture that is easier to interpret geometrically, where the action of each hidden layer is a projection onto a polyhedral cone derived from the layer's parameters. By repeatedly adding such layers, with parameters chosen such that we project small parts of the graph of $\phi$ from the outside in, we, in a controlled way, construct a network that implicitly approximates the graph over a ball of radius $R$. The accuracy of this construction is controlled by a discretization parameter $\delta$ and we show that the tolerance in the resulting error bound scales as $(d-1)R^{3/2}\delta^{1/2}$ and the required number of layers is of order $d\big(\frac{32R}{\delta}\big)^{\frac{d+1}{2}}$.
The Geometric Structure of Fully-Connected ReLU-Layers
Oct 05, 2023



We formalize and interpret the geometric structure of $d$-dimensional fully connected ReLU-layers in neural networks. The parameters of a ReLU-layer induce a natural partition of the input domain, such that in each sector of the partition, the ReLU-layer can be greatly simplified. This leads to a geometric interpretation of a ReLU-layer as a projection onto a polyhedral cone followed by an affine transformation, in line with the description in [doi:10.48550/arXiv.1905.08922] for convolutional networks with ReLU activations. Further, this structure facilitates simplified expressions for preimages of the intersection between partition sectors and hyperplanes, which is useful when describing decision boundaries in a classification setting. We investigate this in detail for a feed-forward network with one hidden ReLU-layer, where we provide results on the geometric complexity of the decision boundary generated by such networks, as well as proving that modulo an affine transformation, such a network can only generate $d$ different decision boundaries. Finally, the effect of adding more layers to the network is discussed.