 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Constrained Reinforcement Learning under Strong Duality
Jun 22, 2024


We study the problem of Distributionally Robust Constrained RL (DRC-RL), where the goal is to maximize the expected reward subject to environmental distribution shifts and constraints. This setting captures situations where training and testing environments differ, and policies must satisfy constraints motivated by safety or limited budgets. Despite significant progress toward algorithm design for the separate problems of distributionally robust RL and constrained RL, there do not yet exist algorithms with end-to-end convergence guarantees for DRC-RL. We develop an algorithmic framework based on strong duality that enables the first efficient and provable solution in a class of environmental uncertainties. Further, our framework exposes an inherent structure of DRC-RL that arises from the combination of distributional robustness and constraints, which prevents a popular class of iterative methods from tractably solving DRC-RL, despite such frameworks being applicable for each of distributionally robust RL and constrained RL individually. Finally, we conduct experiments on a car racing benchmark to evaluate the effectiveness of the proposed algorithm.
An Invariant Information Geometric Method for High-Dimensional Online Optimization
Jan 03, 2024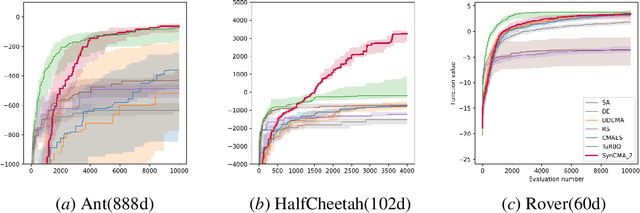
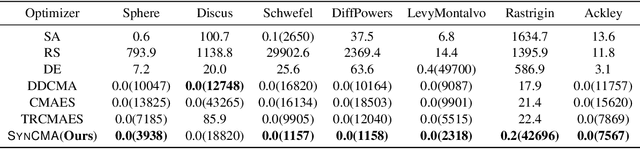
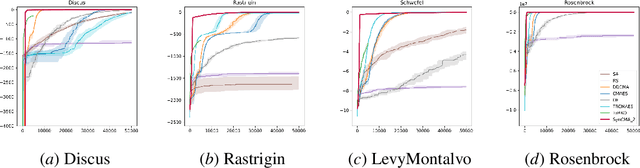

Sample efficiency is crucial in optimization, particularly in black-box scenarios characterized by expensive evaluations and zeroth-order feedback. When computing resources are plentiful, Bayesian optimization is often favored over evolution strategies. In this paper, we introduce a full invariance oriented evolution strategies algorithm, derived from its corresponding framework, that effectively rivals the leading Bayesian optimization method in tasks with dimensions at the upper limit of Bayesian capability. Specifically, we first build the framework InvIGO that fully incorporates historical information while retaining the full invariant and computational complexity. We then exemplify InvIGO on multi-dimensional Gaussian, which gives an invariant and scalable optimizer SynCMA . The theoretical behavior and advantages of our algorithm over other Gaussian-based evolution strategies are further analyzed. Finally, We benchmark SynCMA against leading algorithms in Bayesian optimization and evolution strategies on various high dimension tasks, in cluding Mujoco locomotion tasks, rover planning task and synthetic functions. In all scenarios, SynCMA demonstrates great competence, if not dominance, over other algorithms in sample efficiency, showing the underdeveloped potential of property oriented evolution strategies.