 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foldable and Agile Soft Electromagnetic Robot for Multimodal Navigation in Confined and Unstructured Environments
Mar 30, 2026Multimodal locomotion is crucial for an animal's adaptability in unstructured wild environments. Similarly, in the human gastrointestinal tract, characterized by viscoelastic mucus, complex rugae, and narrow sphincters like the cardia, multimodal locomotion is also essential for a small-scale soft robot to conduct tasks. Here, we introduce a small-scale compact, foldable, and robust soft electromagnetic robot (M-SEMR) with more than nine locomotion modes designed for such a scenario. Featuring a six-spoke elastomer body embedded with liquid metal channels and driven by Laplace forces under a static magnetic field, the M-SEMR is capable of rapid transitions (< 0.35 s) among different locomotion modes. It achieves exceptional agility, including high-speed rolling (818 mm/s, 26 BL/s), omnidirectional crawling, jumping, and swimming. Notably, the robot can fold to reduce its volume by 79%, enabling it to traverse confined spaces. We further validate its navigation capabilities on complex terrains, including discrete obstacles, viscoelastic gelatin surfaces, viscous fluids, and simulated biological tissues. This system offers a versatile strategy for developing high-mobility soft robots for future biomedical applications.
Nearshore Underwater Target Detection Meets UAV-borne Hyperspectral Remote Sensing: A Novel Hybrid-level Contrastive Learning Framework and Benchmark Dataset
Feb 20, 2025UAV-borne hyperspectral remote sensing has emerged as a promising approach for underwater target detection (UTD). However, its effectiveness is hindered by spectral distortions in nearshore environments, which compromise the accuracy of traditional hyperspectral UTD (HUTD) methods that rely on bathymetric model. These distortions lead to significant uncertainty in target and background spectra, challenging the detection process. To address this, we propose the Hyperspectral Underwater Contrastive Learning Network (HUCLNet), a novel framework that integrates contrastive learning with a self-paced learning paradigm for robust HUTD in nearshore regions. HUCLNet extracts discriminative features from distorted hyperspectral data through contrastive learning, while the self-paced learning strategy selectively prioritizes the most informative samples. Additionally, a reliability-guided clustering strategy enhances the robustness of learned representations.To evaluate the method effectiveness, we conduct a novel nearshore HUTD benchmark dataset, ATR2-HUTD, covering three diverse scenarios with varying water types and turbidity, and target types. Extensive experiments demonstrate that HUCLNet significantly outperforms state-of-the-art methods. The dataset and code will be publicly available at: https://github.com/qjh1996/HUTD
A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
May 14, 2024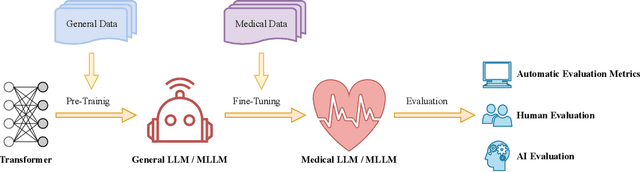
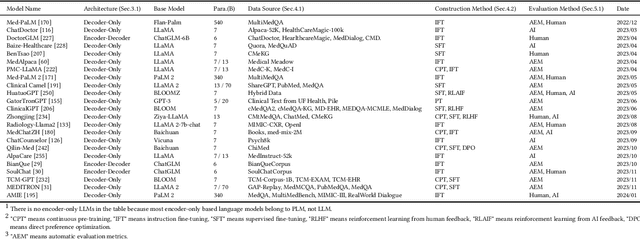
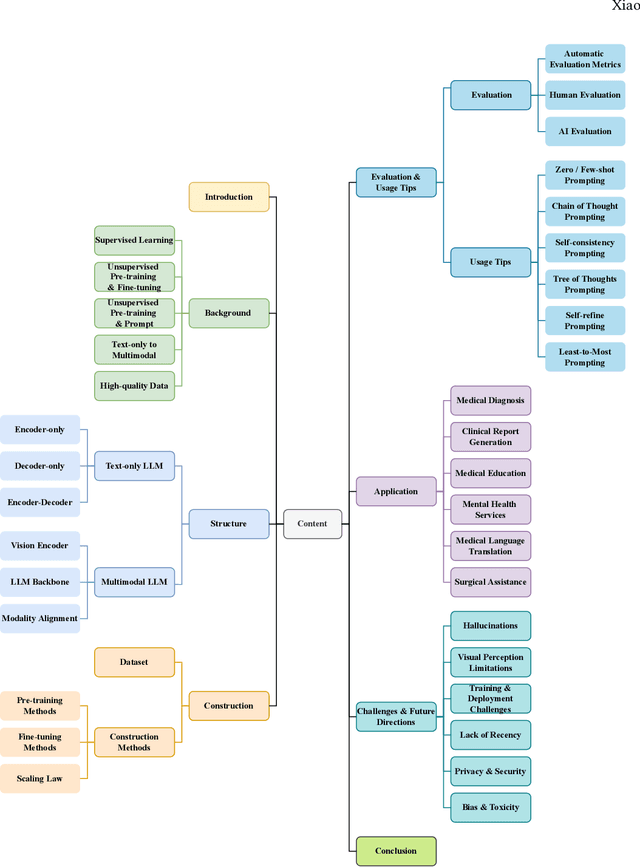
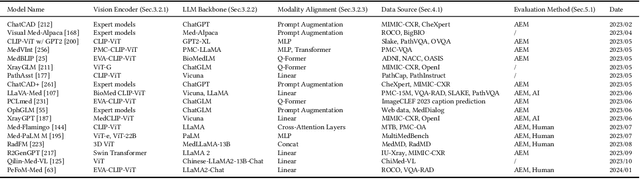
Since the release of ChatGPT and GPT-4, large language models (LLMs) and multimodal large language models (MLLMs) have garnered significant attention due to their powerful and general capabilities in understanding, reasoning, and generation, thereby offering new paradigms for the integration of artificial intelligence with medicine. This survey comprehensively overviews the development background and principles of LLMs and MLLMs, as well as explores their application scenarios, challenges, and future directions in medicine. Specifically, this survey begins by focusing on the paradigm shift, tracing the evolution from traditional models to LLMs and MLLMs, summarizing the model structures to provide detailed foundational knowledge. Subsequently, the survey details the entire process from constructing and evaluating to using LLMs and MLLMs with a clear logic. Following this, to emphasize the significant value of LLMs and MLLMs in healthcare, we survey and summarize 6 promising applications in healthcare. Finally, the survey discusses the challenges faced by medical LLMs and MLLMs and proposes a feasible approach and direction for the subsequent integration of artificial intelligence with medicine. Thus, this survey aims to provide researchers with a valuable and comprehensive reference guide from the perspectives of the background, principles, and clinical applications of LLMs and MLLMs.
Beyond Sharing Weights in Decoupling Feature Learning Network for UAV RGB-Infrared Vehicle Re-Identification
Oct 12, 2023Owing to the capacity of performing full-time target search, cross-modality vehicle re-identification (Re-ID) based on unmanned aerial vehicle (UAV) is gaining more attention in both video surveillance and public security. However, this promising and innovative research has not been studied sufficiently due to the data inadequacy issue. Meanwhile, the cross-modality discrepancy and orientation discrepancy challenges further aggravate the difficulty of this task. To this end, we pioneer a cross-modality vehicle Re-ID benchmark named UAV Cross-Modality Vehicle Re-ID (UCM-VeID), containing 753 identities with 16015 RGB and 13913 infrared images. Moreover, to meet cross-modality discrepancy and orientation discrepancy challenges, we present a hybrid weights decoupling network (HWDNet) to learn the shared discriminative orientation-invariant features. For the first challenge, we proposed a hybrid weights siamese network with a well-designed weight restrainer and its corresponding objective function to learn both modality-specific and modality shared information. In terms of the second challenge, three effective decoupling structures with two pretext tasks are investigated to learn orientation-invariant feature. Comprehensive experiments are carried out to validate the effectiveness of the proposed method. The dataset and codes will be released at https://github.com/moonstarL/UAV-CM-VeID.
Masked Spatial-Spectral Autoencoders Are Excellent Hyperspectral Defenders
Jul 16, 2022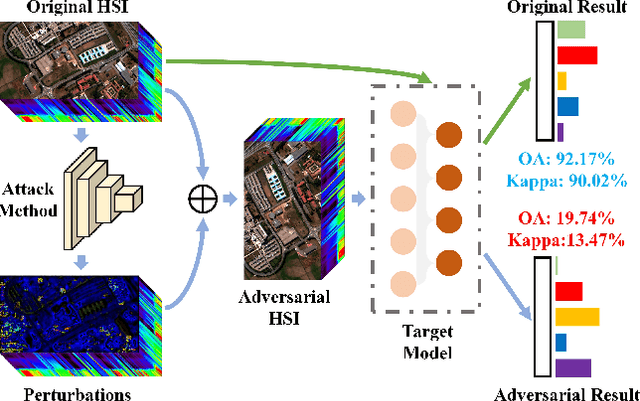
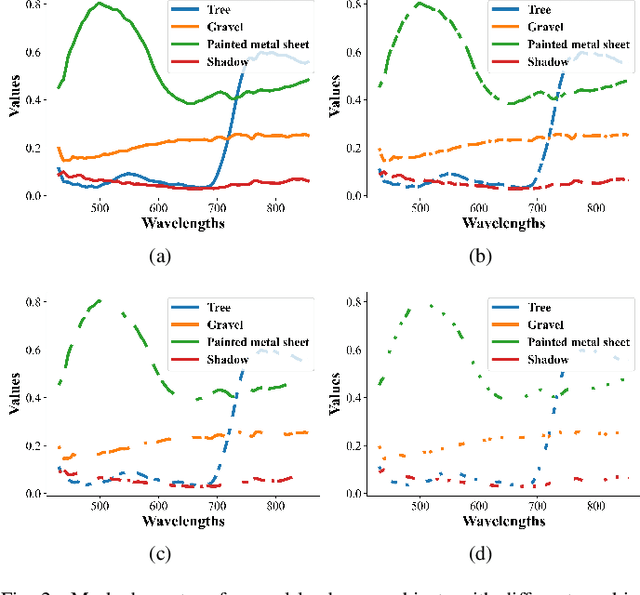
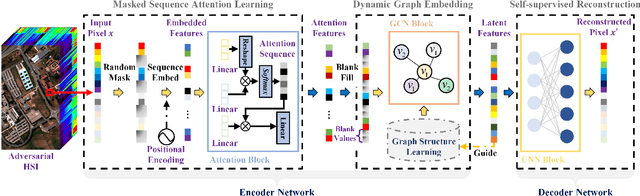
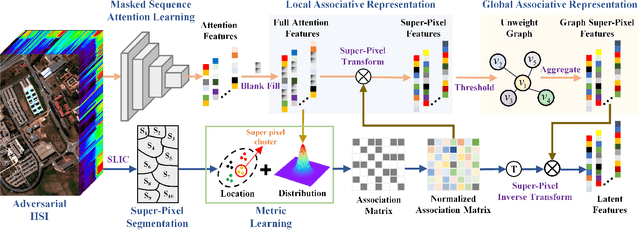
Deep learning methodology contributes a lot to the development of hyperspectral image (HSI) analysis community. However, it also makes HSI analysis systems vulnerable to adversarial attacks. To this end, we propose a masked spatial-spectral autoencoder (MSSA) in this paper under self-supervised learning theory, for enhancing the robustness of HSI analysis systems. First, a masked sequence attention learning module is conducted to promote the inherent robustness of HSI analysis systems along spectral channel. Then, we develop a graph convolutional network with learnable graph structure to establish global pixel-wise combinations.In this way, the attack effect would be dispersed by all the related pixels among each combination, and a better defense performance is achievable in spatial aspect.Finally, to improve the defense transferability and address the problem of limited labelled samples, MSSA employs spectra reconstruction as a pretext task and fits the datasets in a self-supervised manner.Comprehensive experiments over three benchmarks verify the effectiveness of MSSA in comparison with the state-of-the-art hyperspectral classification methods and representative adversarial defense strategies.